
AWS DataLake 構築ハンズオンに行ってきました
AWSJ大阪が増床されて2019年10月限定でAWS pop-up loftというコワーキングスペースを解放されていて、そこでデータレイクハンズオンが開催されていましたので行ってきました。

10/31の最終日でしたので、最後に来られてよかったです。

Still Day One!!

DeepRacerな席もあります。

さて、ハンズオンです。

期間限定ロフトなのでステッカーはレアになるかもしれないですね。
いただきました。
ハンズオンの前に少しセミナーがありました。
すごく参考になりました。
以下は、気になったことのメモとか感想を書いています。
登壇者、発表者、主催企業などの意図とは異なる可能性がありますことをご了承ください。
目次
なぜ、データレイクか?
何をどう分析するか?
データをどうためていくべきか?
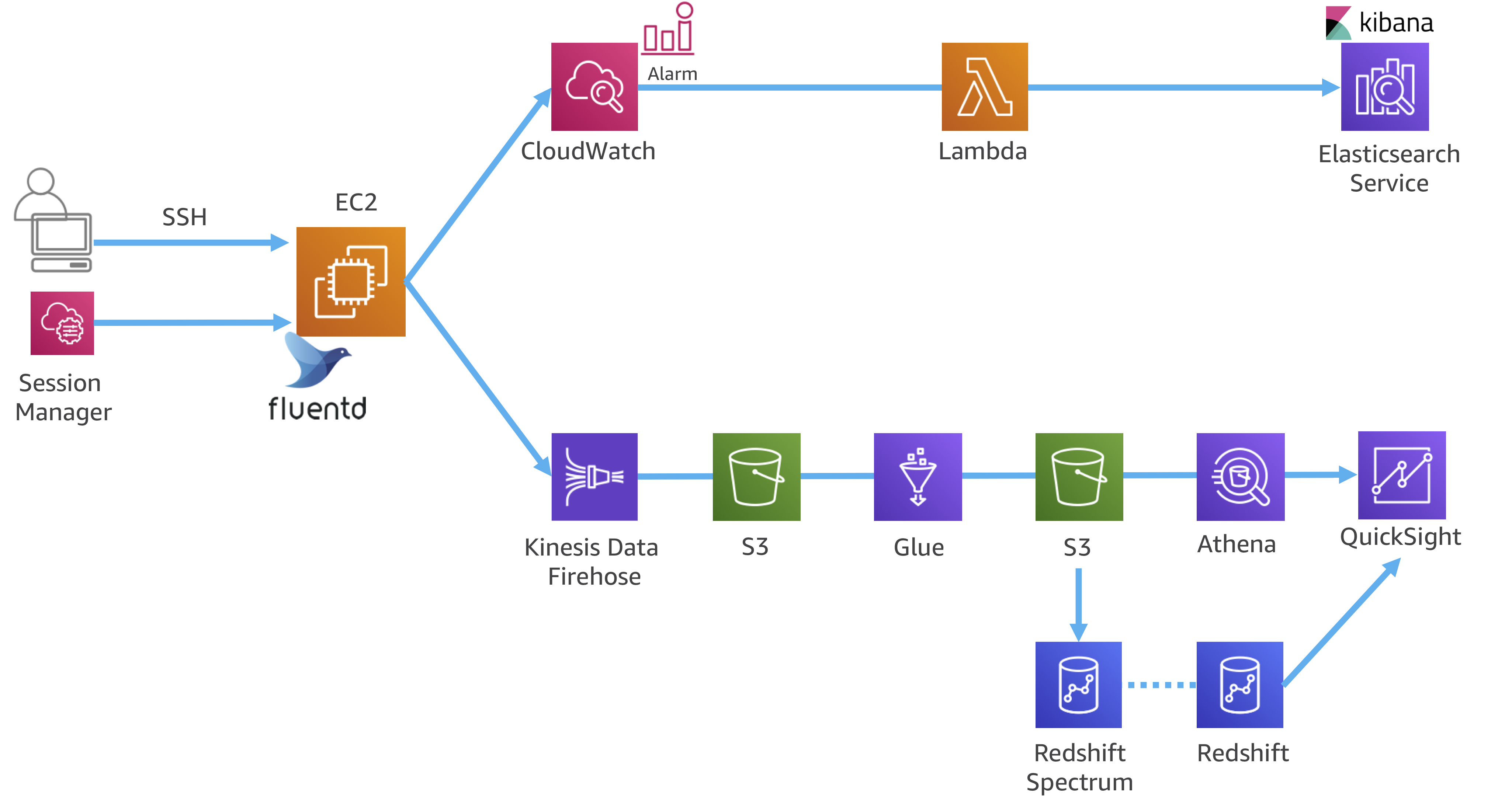
まずはAWSの王道アーキテクチャを使って構成してみるハンズオン。
使ってみて、自社課題に対応できるか今後確認していくきっかけになれば。
RDBにデータを貯める旧来のやり方の場合、スキーマが固定、それにあわせた加工をしなければならない。
しかし、入ってくるデータの量が多くなり多様化してきた。
データ量が多いことでクエリも重くなる。
多様化したことで固定化されたスキーマでの対応も辛くなった。
コールセンターからの音声やIoTデバイスからの画像も入ってくるようになった。
このような非構造化データもRDBには向いていない。
ビジネスのスピードが早くなることによって、リアルタイム分析が必要になり、機械学習アルゴリズムの発達によって分析も多様化した。
分析方法も変化のスピードが早くSQLだけでは対応できない。
なので、データのサイロ化が必要。
サイロ化により、扱うデータによって適したデータベースを選択する。
でもスケーラビリティの問題が解決せず、データの所在管理がカオス化する。
サイロをまたいだ分析も困難になる。
この課題を解決する仕組みがデータレイク。
いろんなところからやってくる多種多様なデータを一回データレイクとして全部データの形を変えずに貯める。
要望や要件にあわせて適切なデータベース、分析ツールにデータを取り出して処理をする。
データを貯めるリソースと、分析するリソースを分けるので、個別にスケールできる。
分析結果だけでいいのであれば、分析リソースを使い捨てできる。
データレイクにあるものを正とできる(SSOT=Single Source of Truth)。
多様な分析に対応できる。
データレイクに必要なストレージとは?
* 構造化、非構造化データ関係なく多様なデータを保存できる。
* データがなくならない=耐久性が高い。
* サイズ無制限。
* APIですぐにアクセスできる。
* 様々なシステムのハブとしてどこからでもアクセスできる。
なのでS3=Simple Storage Service。
* 容量無制限
* イレブンナインの耐久性
* 従量課金
* インターネットAPI対応ストレージ
データ分析をうまくすすめるには、試行錯誤のサイクルをうまく早くまわしていく必要がある。
やり直しができる環境が必要。
なのでクラウドは向いている。
ラムダアーキテクチャとは
分析のリアルタイム性に対応するアーキテクチャ
ログの収集方法、頻度、タイミング、一時保存場所、利用目的は様々。
ラムダアーキテクチャはバッチレイヤ、サービングレイヤ、スピードレイヤでデータとクエリをつなぐ。
1ヶ月の売上や傾向など中長期的な分析は、バッチレイヤ、サービングレイヤでつなぐ。
秒間などリアルタイム性が必要なものはスピードレイヤでつなぐ。
同じデータレイクを使って、バッチ処理とストリーミング処理の両方ができるアーキテクチャモデルってことでとりあえずはよさそうですかね。
ハンズオン
手順はこちらのGithubにあります。
Lab1からLab6まであります。
Lab1
まず最初は準備です。
CloudFormationテンプレートをご用意いただいているのでStack作成からスタートです。
1つのVPCとEC2 1インスタンスを作成しますので、特にVPCがソフトリミットなどで制限されていないかアカウントで確認しておいたほうがいいですね。
私の場合は、起動後すぐに、IAMロールを設定して、EC2を再起動して、セッションマネージャからコマンド操作をしました。
Flientdのインストールまでを行います。
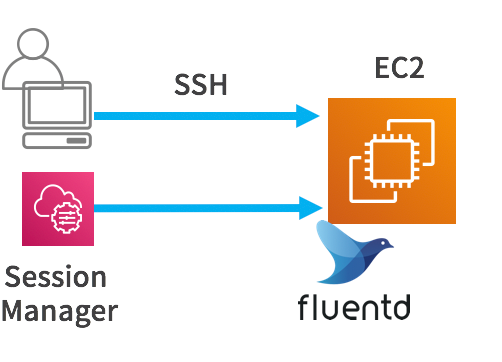
できました!
Lab2
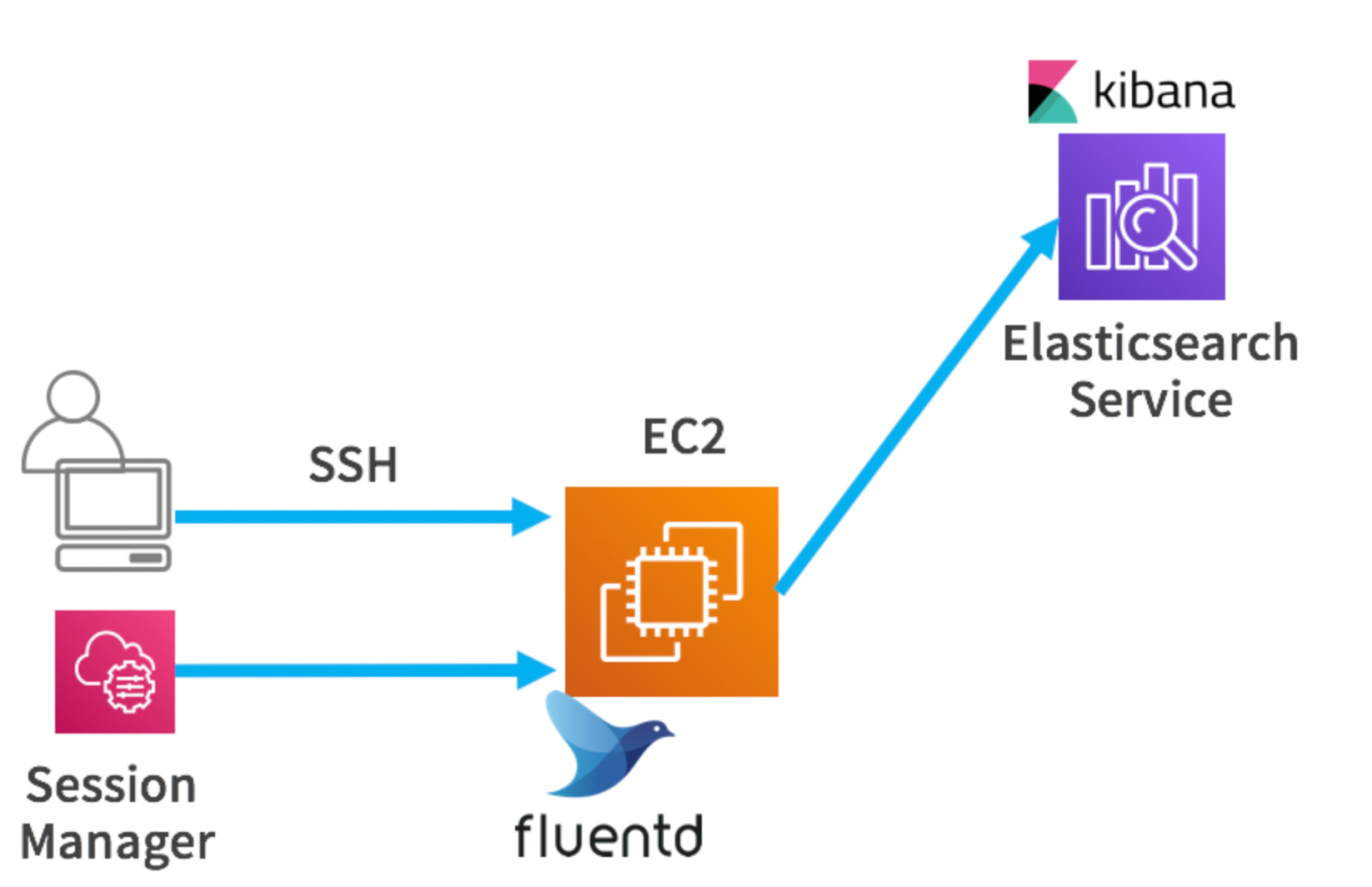
次はアプリケーションログを、ElasticSearch Serviceに取り込んで、Kibanaで可視化します。
手順どおりに進めればだいたいOKなのですが、kibanaでVisulaizationのインポートをするときに、インデックスの競合が発生しました。
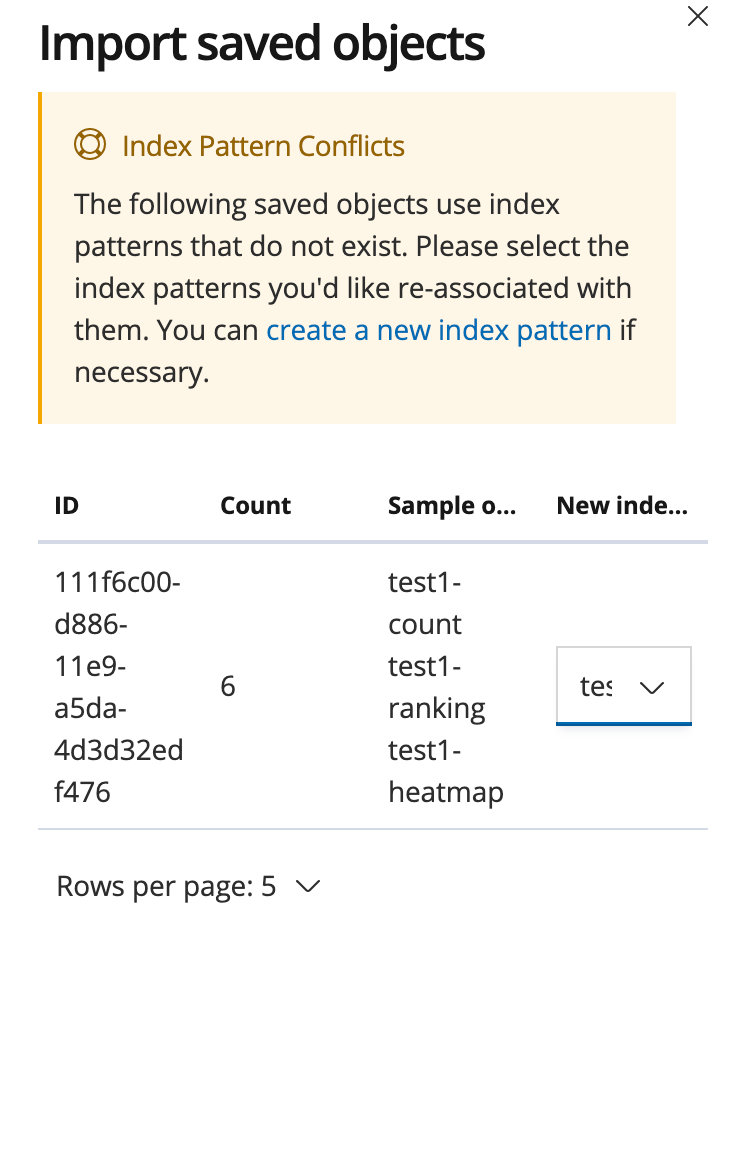
ここで、New Indexを選択しないと、インポートが正常完了しないようです。
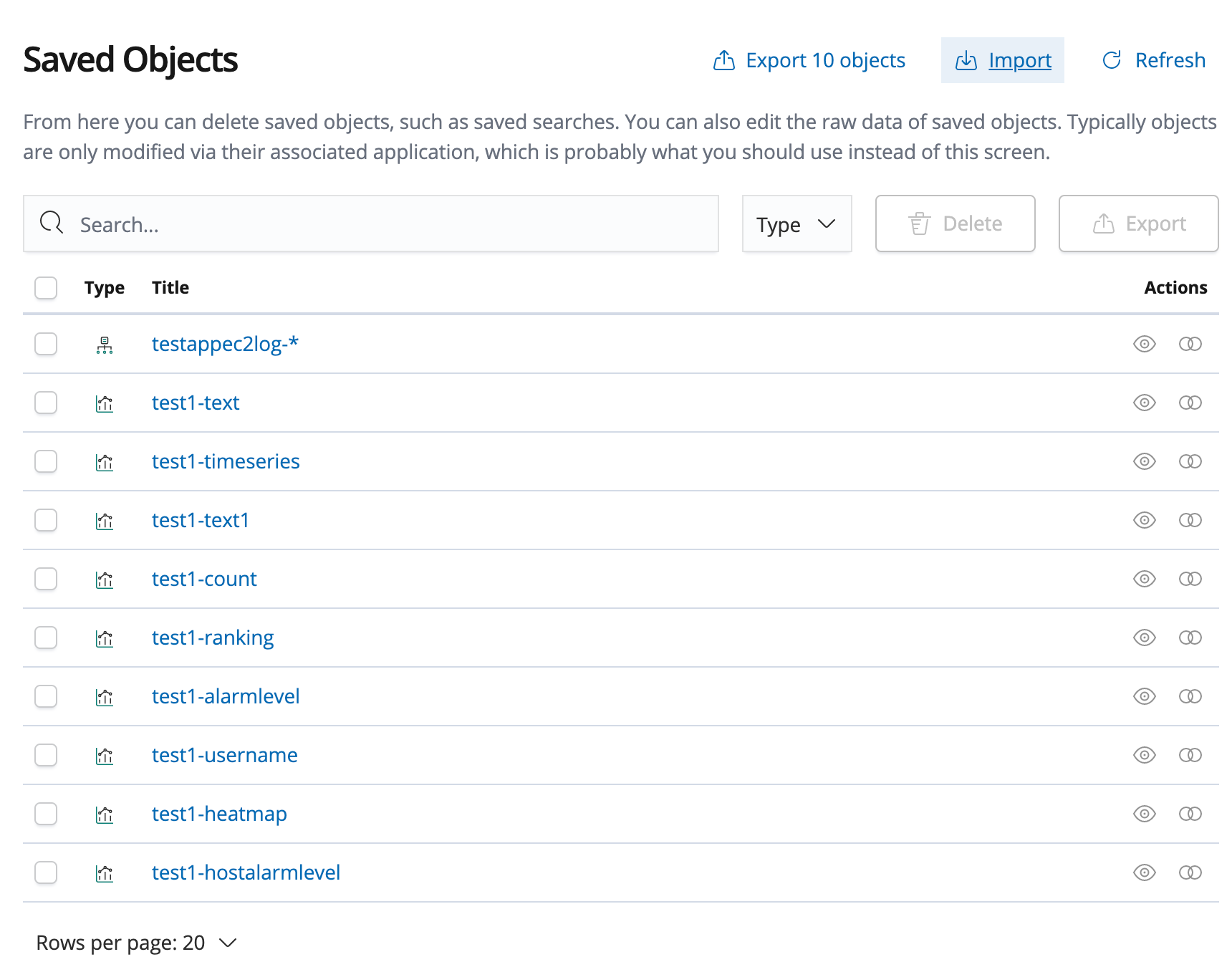
こちらのようになればOKでした。
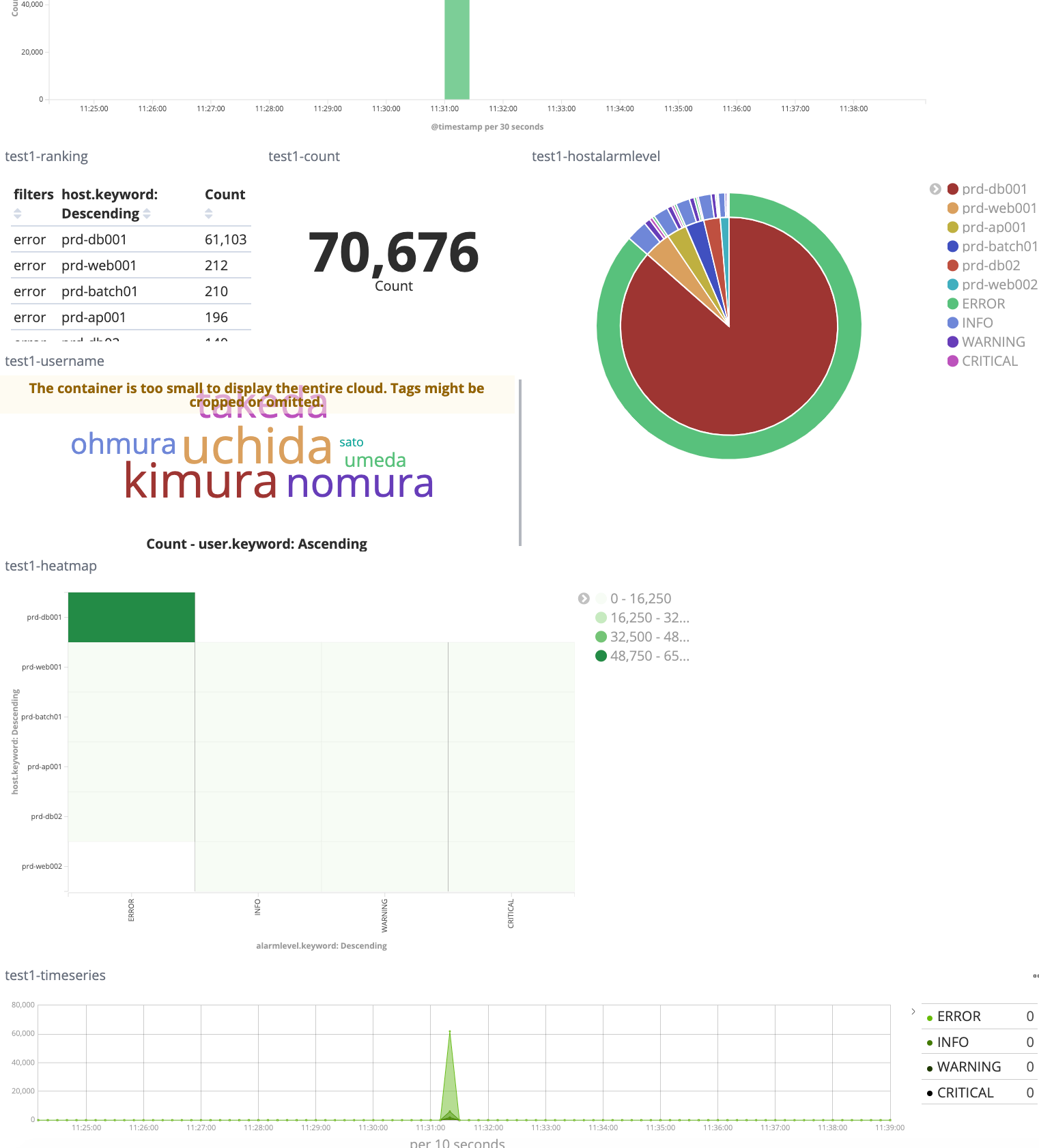
アプリケーションログを可視化したダッシュボードが表示できました。
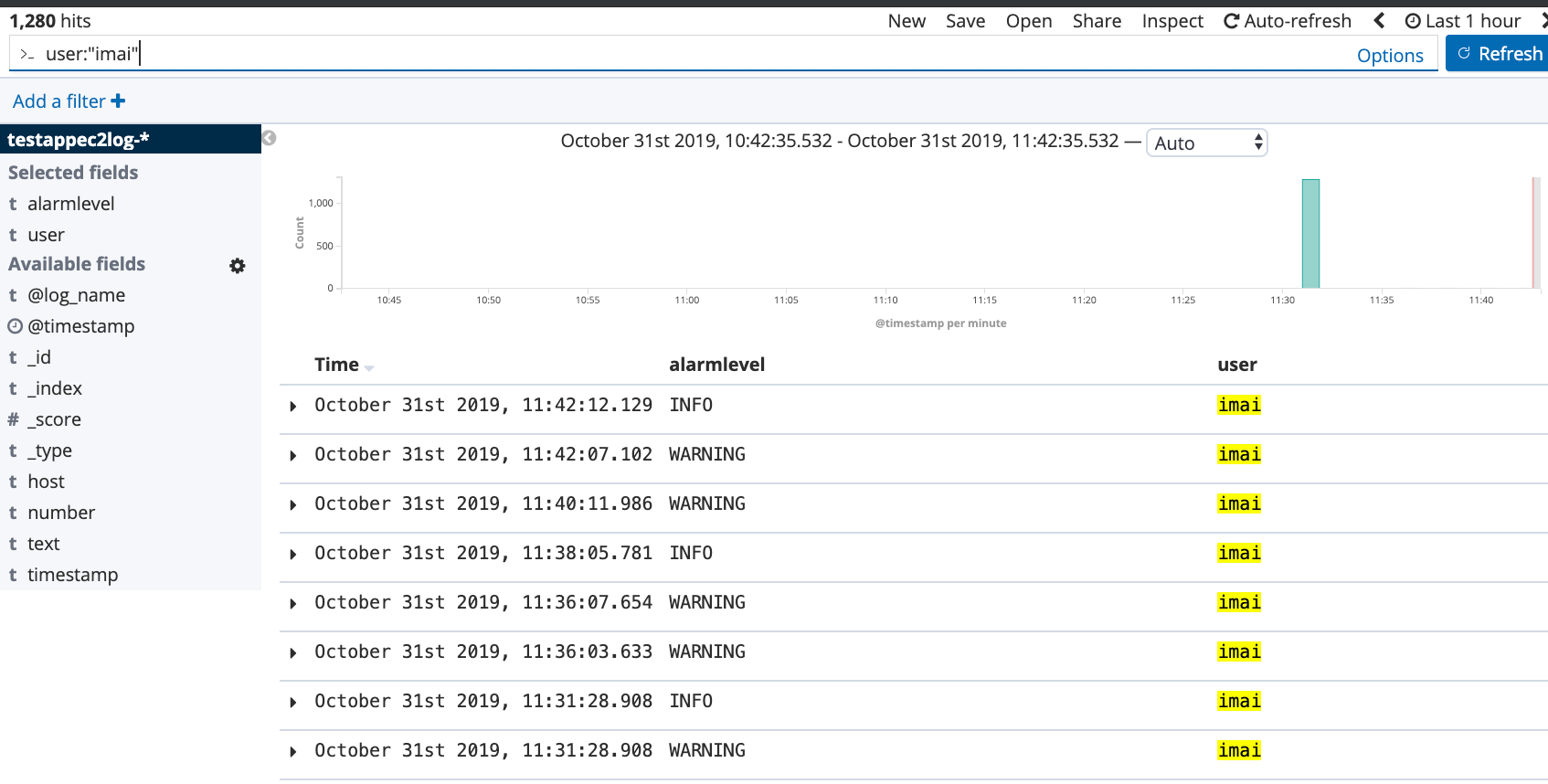
アプリケーションユーザー名でのフィルタリングなど、ログの分析もやりやすくなりました!
lab3
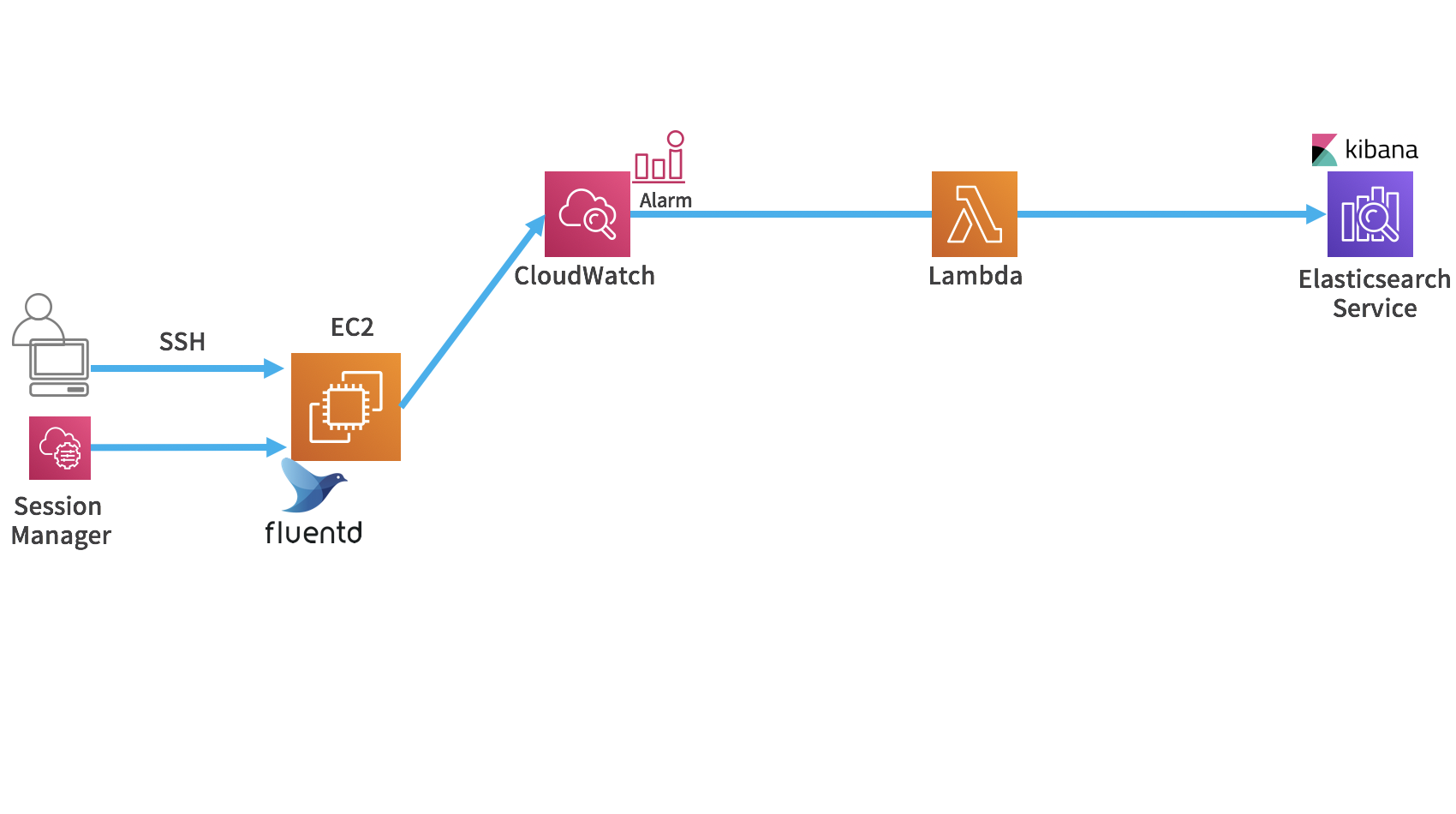
次のラボでは、アプリケーションログをCloudWatch Logsに一度書き出して、CloudWatchアラームの対象として、さらにElasticSearch Service + Kibanaで可視化、分析しやすくします。
CloudWatch LogsへはFluentdのプラグインで送信します。
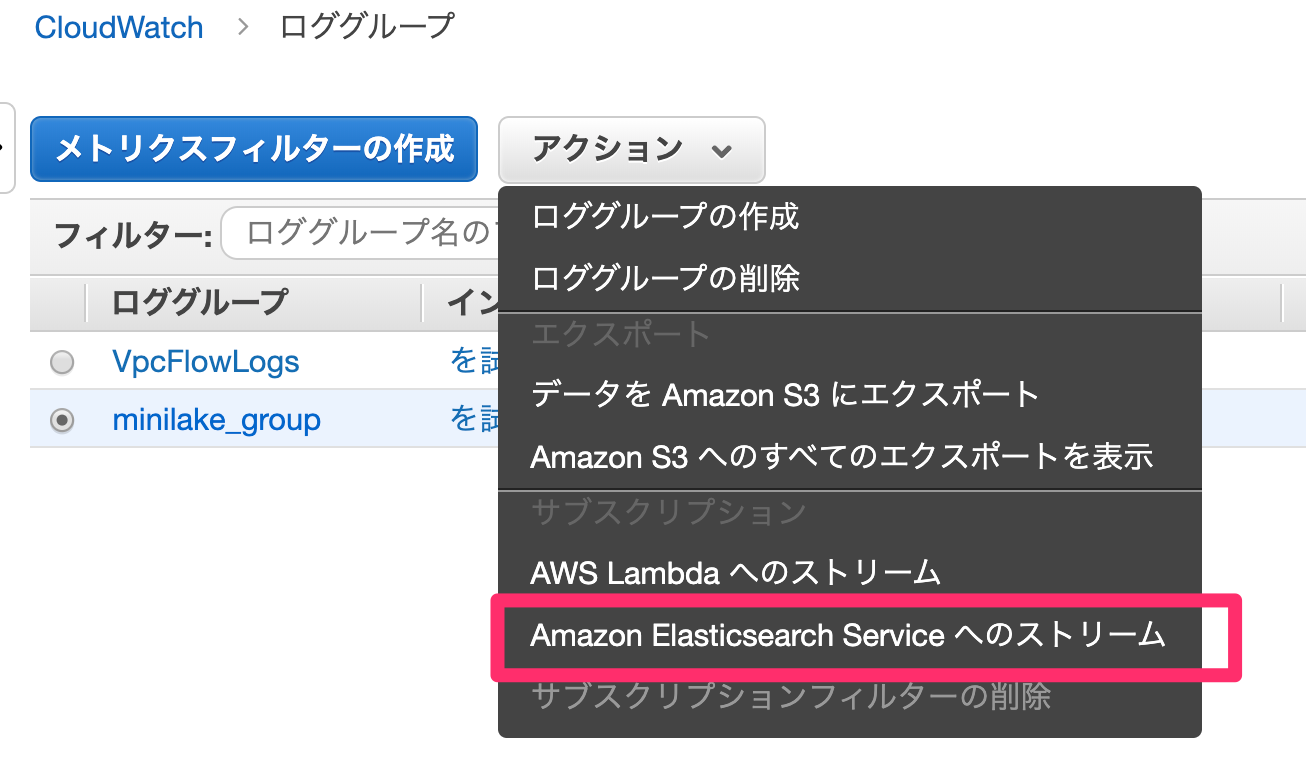
CloudWatch Logsからは、「Elasticsearch Service へのストリーミングの開始」という機能を使いました。
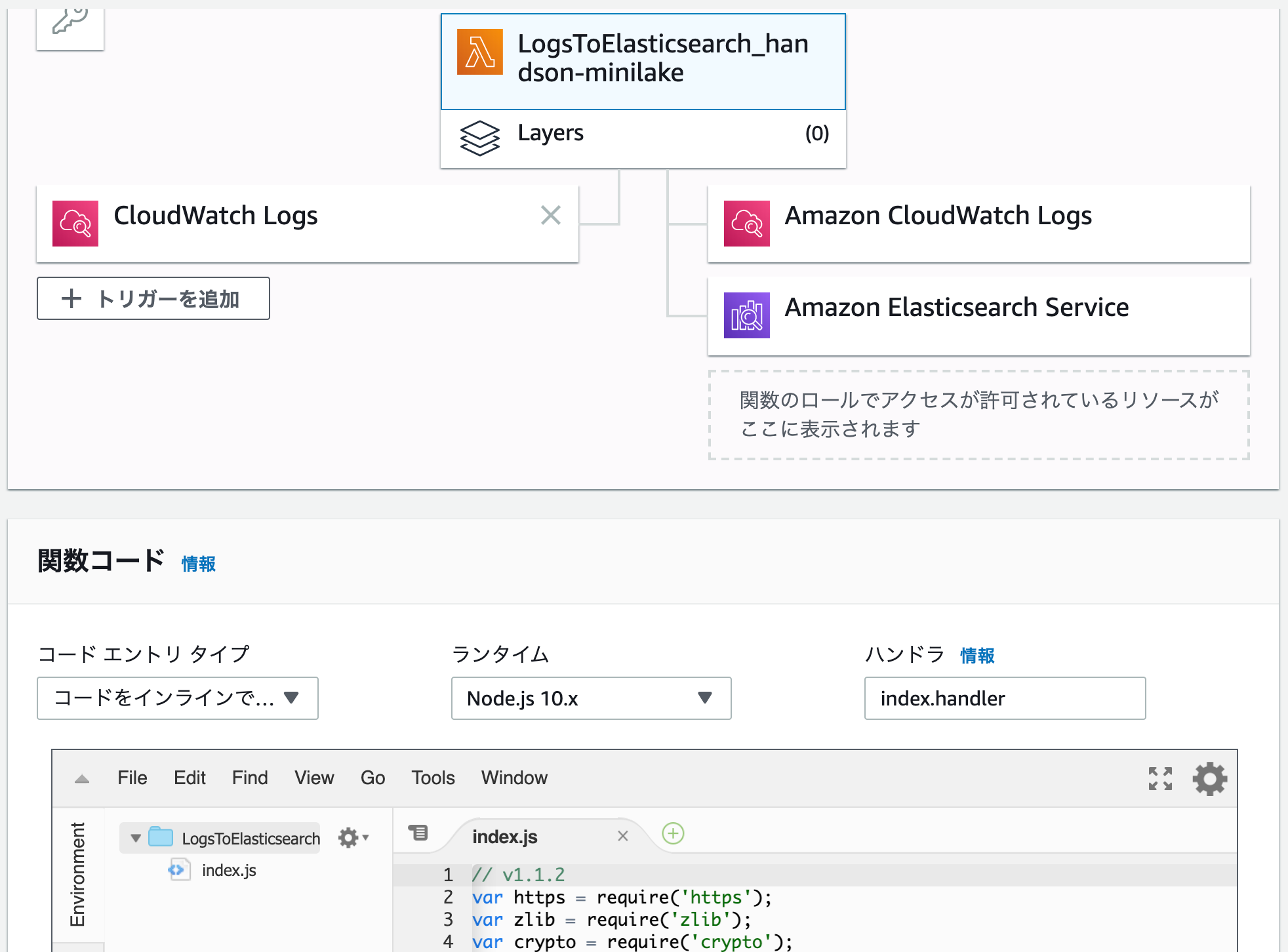
この機能を使うの初めてでしたが、CloudWatch LogsをトリガーとしてESSへ書き込むLambdaを自動で作成してくれるのですね。
すごく便利です。
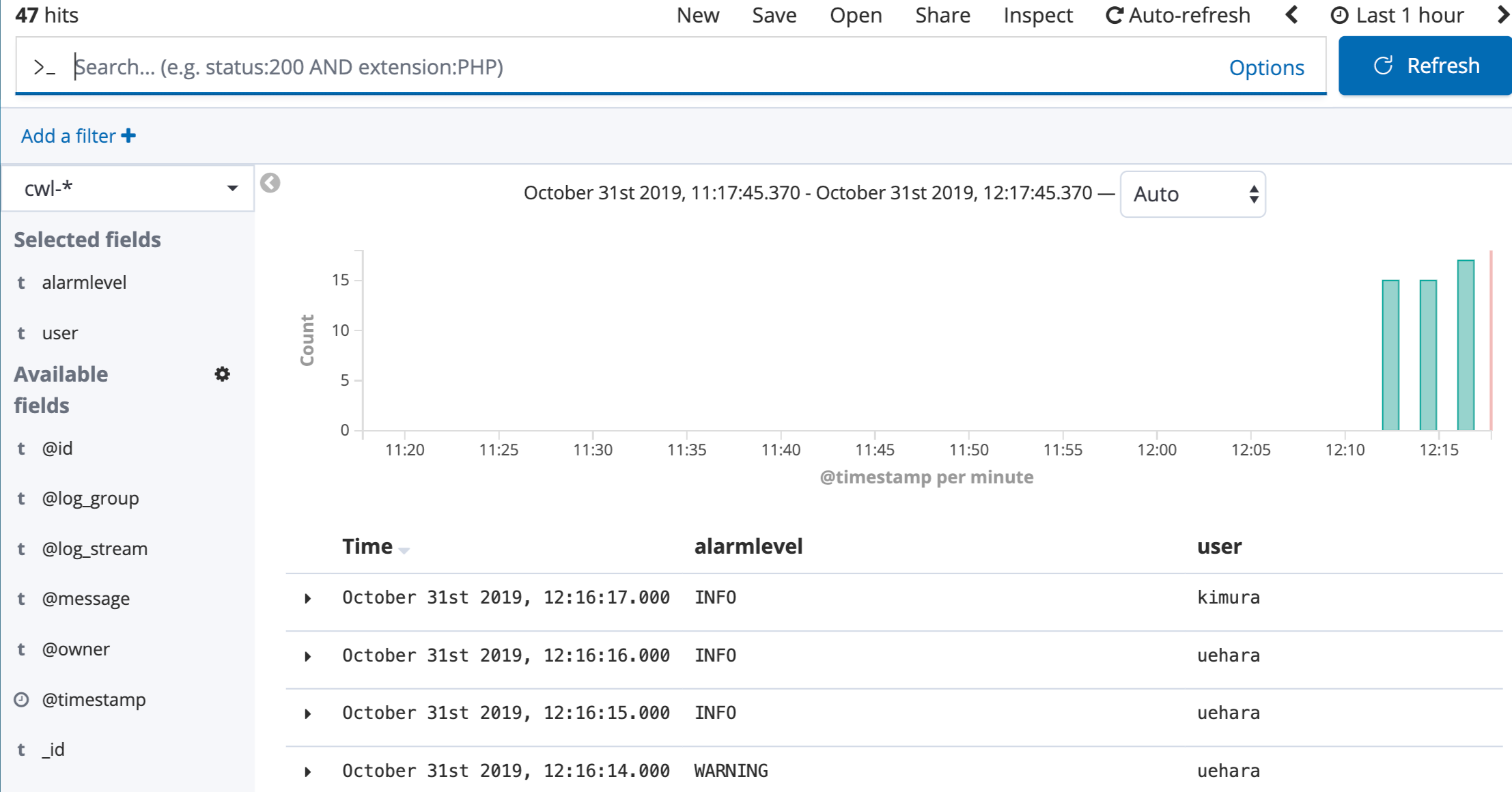
手順通りに進めることで、リアルタイムな可視化分析とアラームの両方が設定できました。
ここまでがスピードレイヤーのハンズオンでした。
Lab4
次は、バッチレイヤのハンズオンに入っていきます。
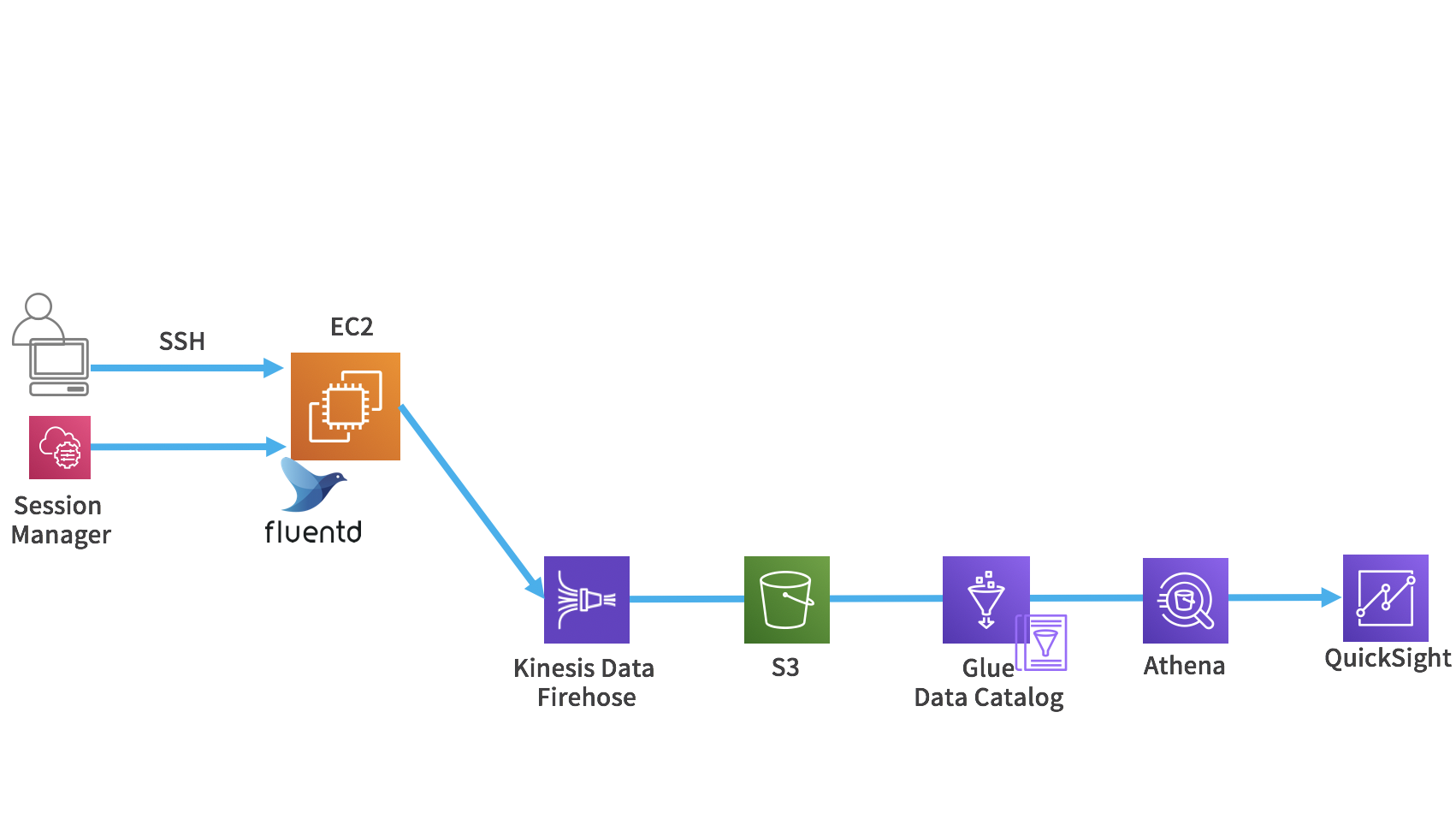
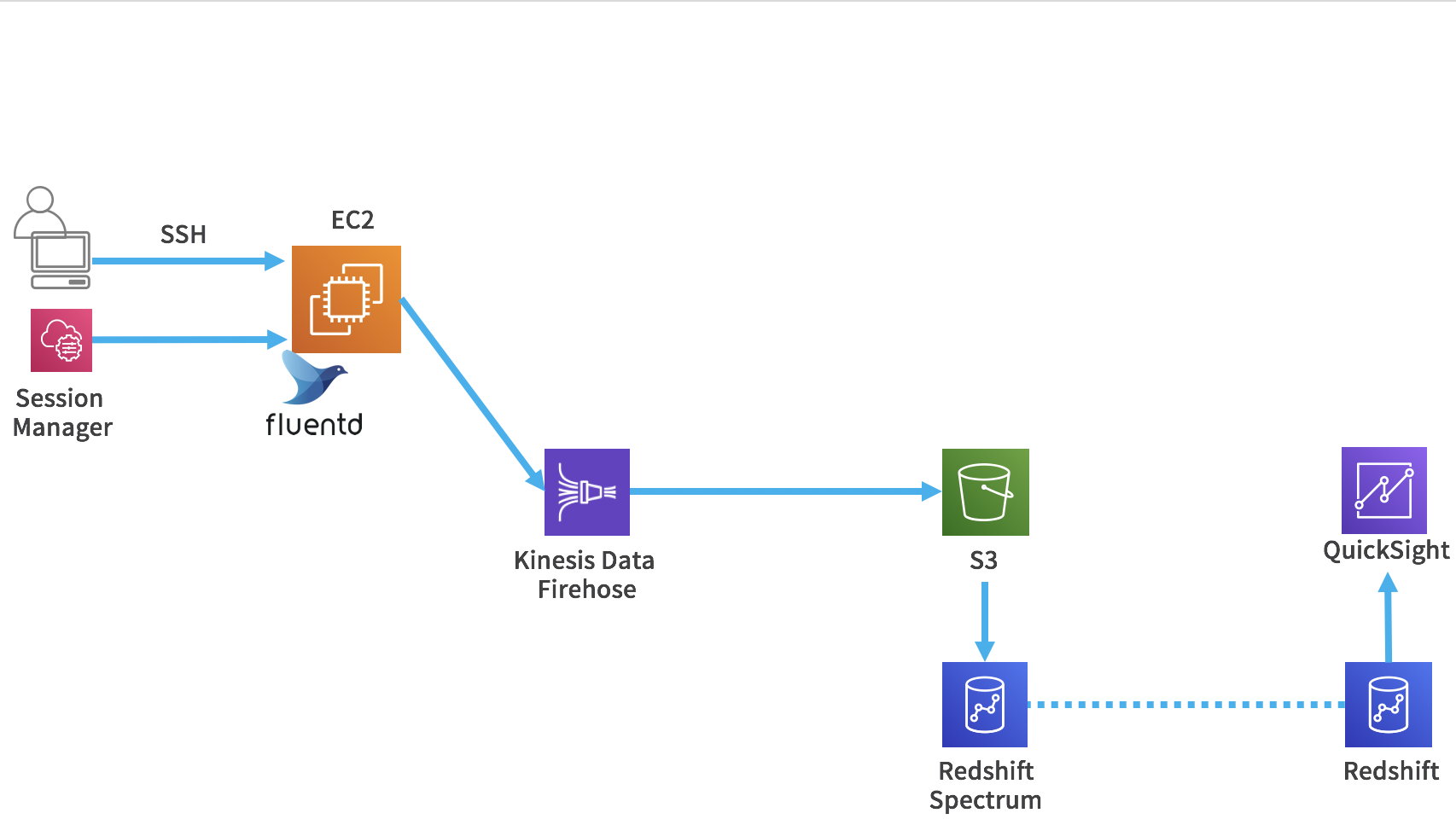
Kinesis Data Firehoseを使ってログをS3に格納します。
そして、Glueで加工し、Athenaでクエリを実行して、QuickSightで可視化します。
Kinesis Data FirehoseはFluentdのプラグインを使用しています。
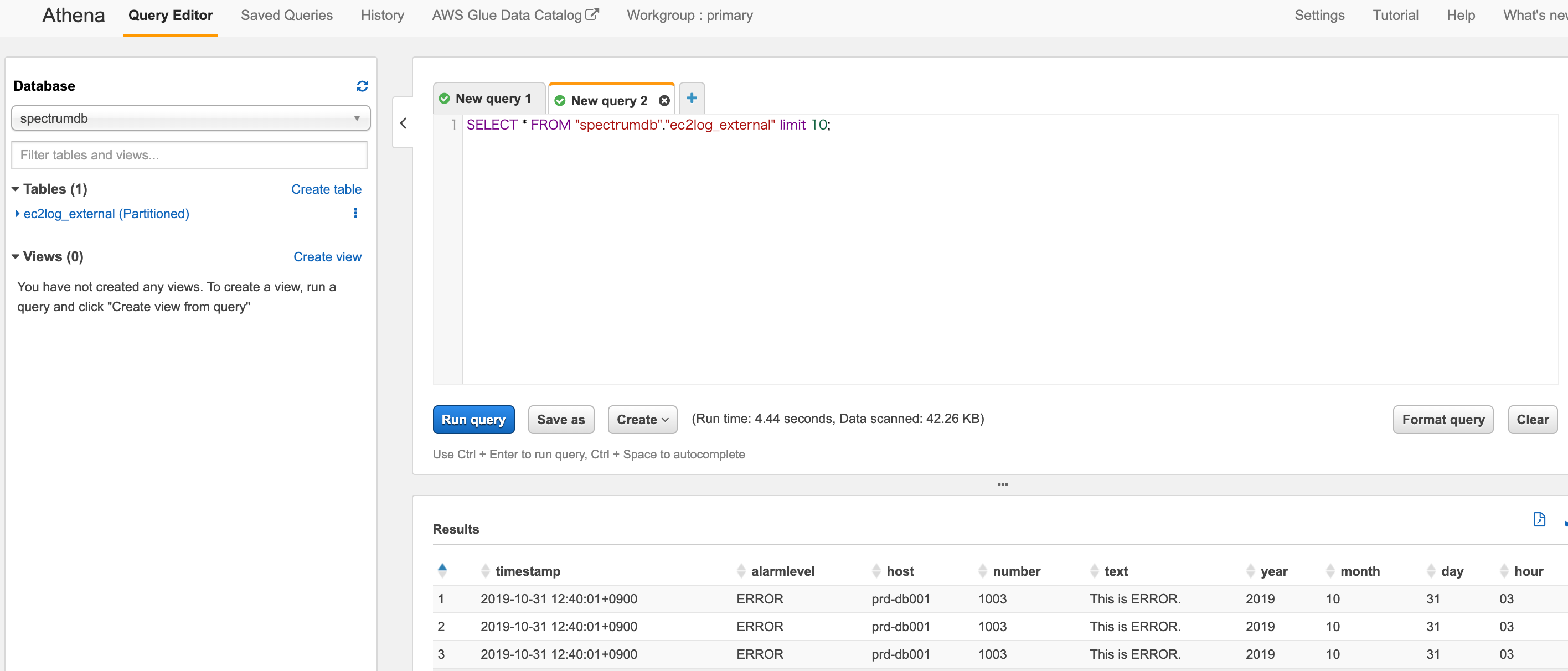
Athenaを使う際に最初に、AthenaのSettingは必要です。
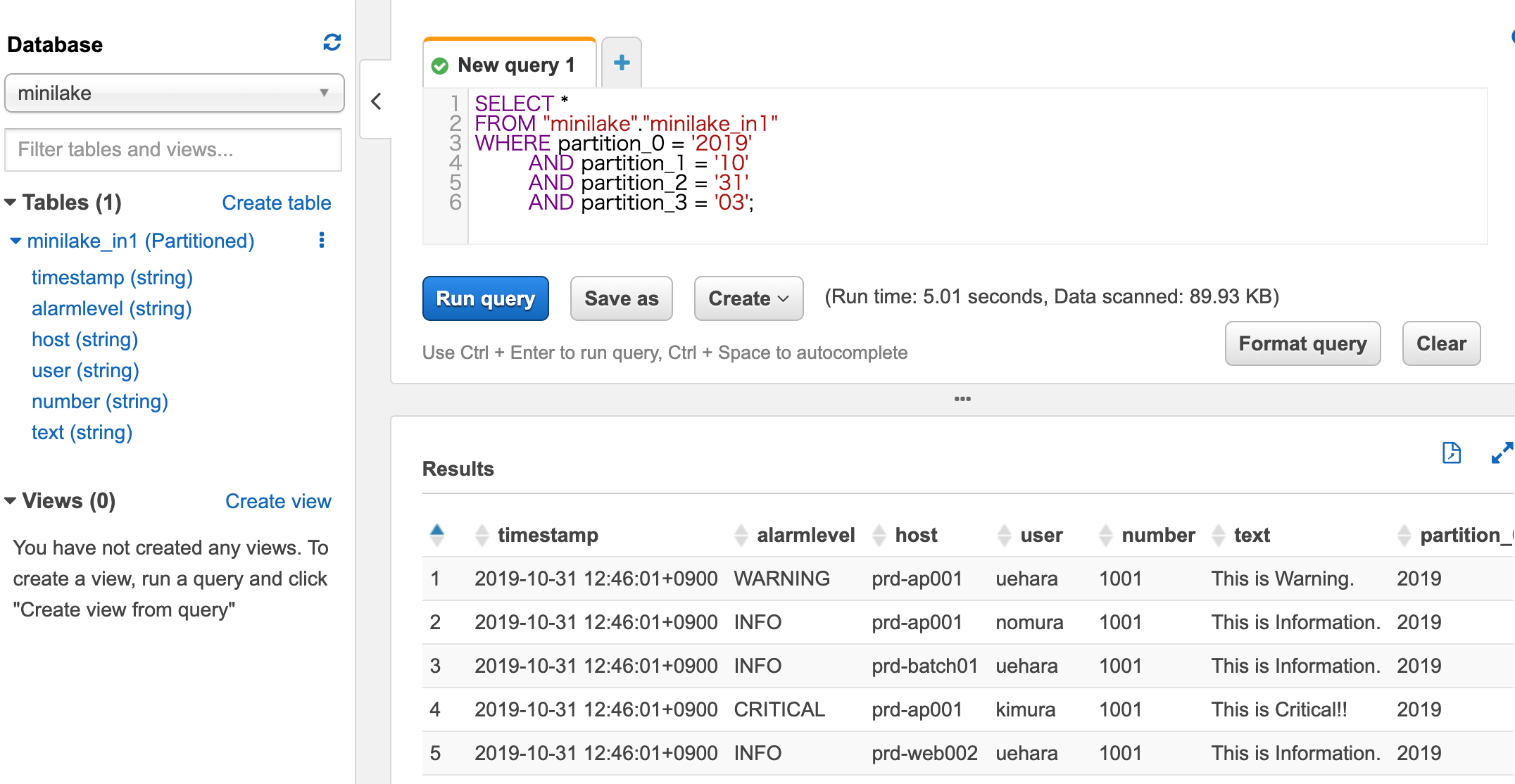
Athenaでクエリ実行、検索ができました。
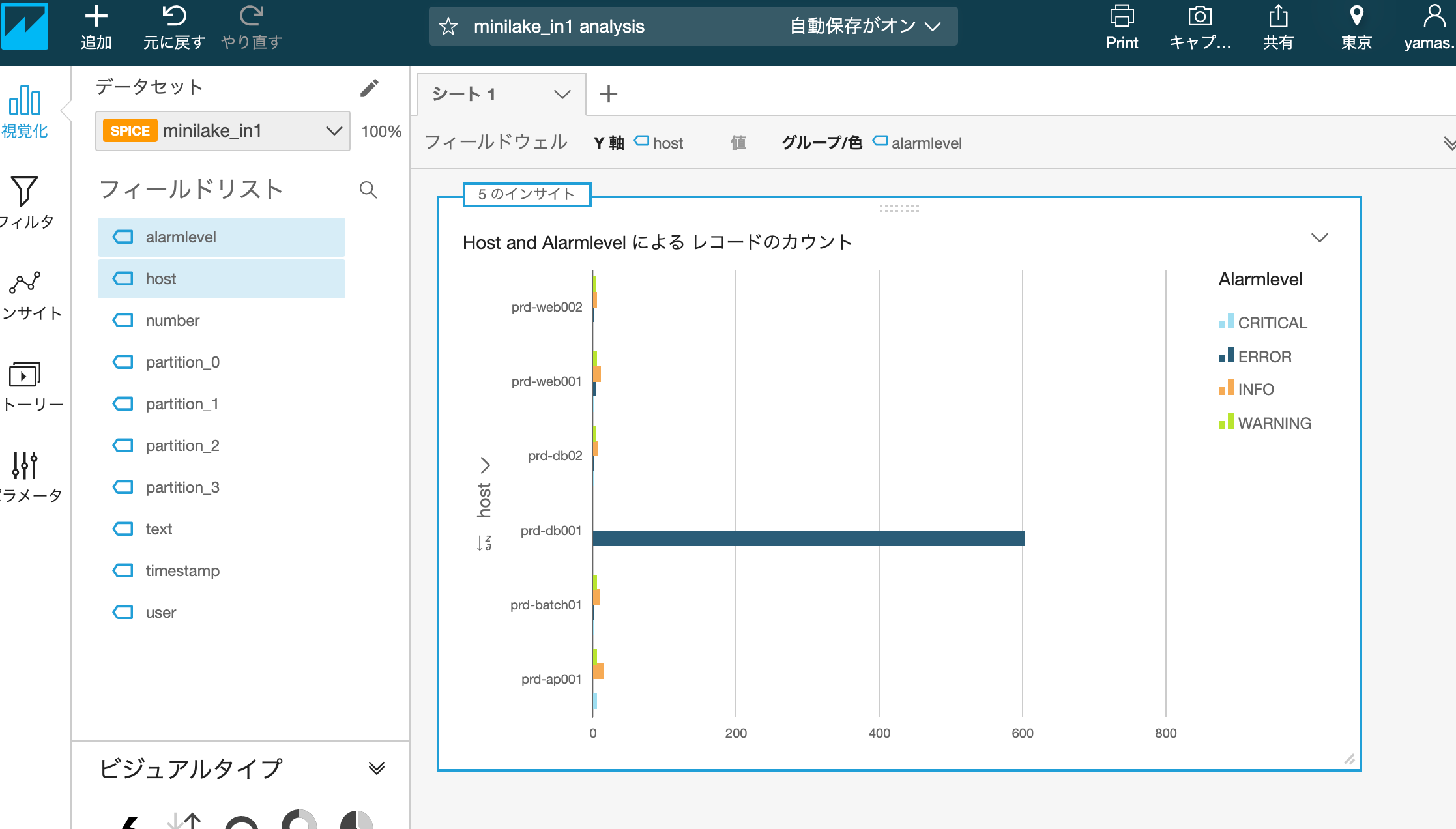
QuikSightでの可視化もできました。
私の環境では、Spiceの容量が使える分なかったので、1GB購入してから進めました。
Lab5
次はDWHを使用したデータ分析です。
DWHといえばRedshiftです。
Redshift用のプライベートサブネット、セキュリティグループの作成も、用意されているCloudFormationテンプレートを使用しました。
Redshiftだけを使ったケースとRedshift Spectrumを使うケースと両方試すことができました。
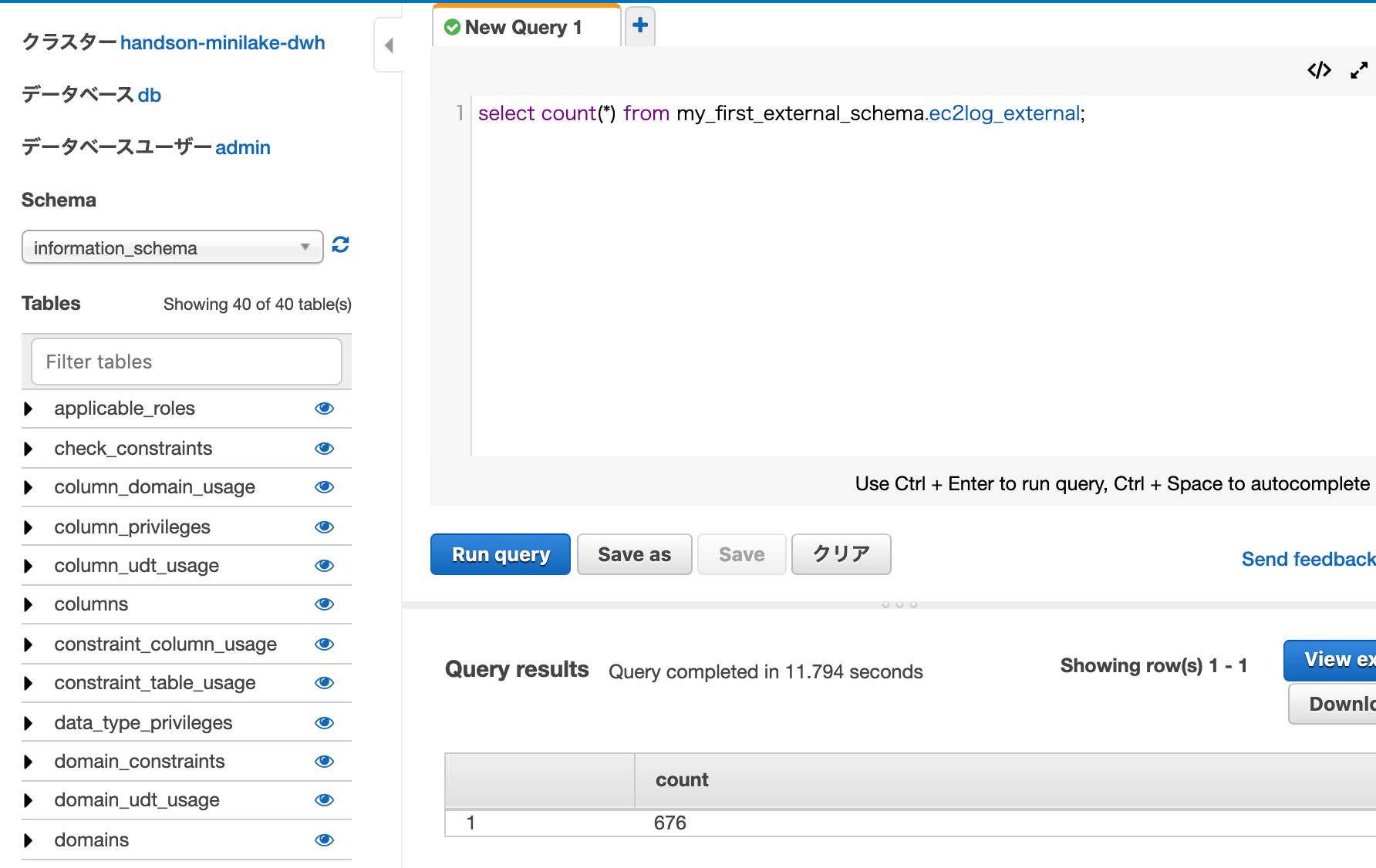
Reshiftでクエリができました。
Athenaにもテーブルができているのでクエリが実行できました。
そして、QuicksightからVPC接続でRedshiftに接続して可視化できました。
Lab6
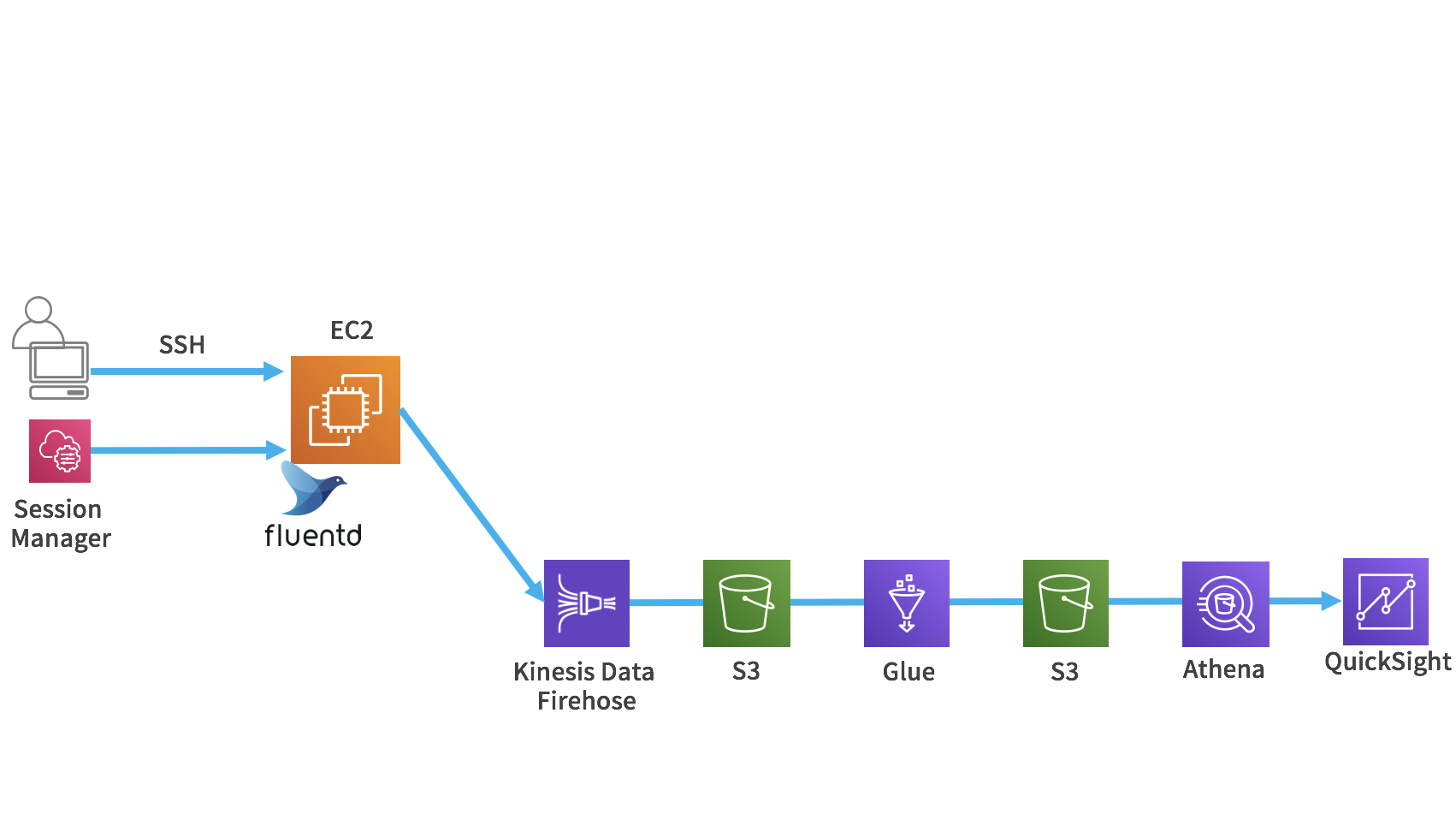
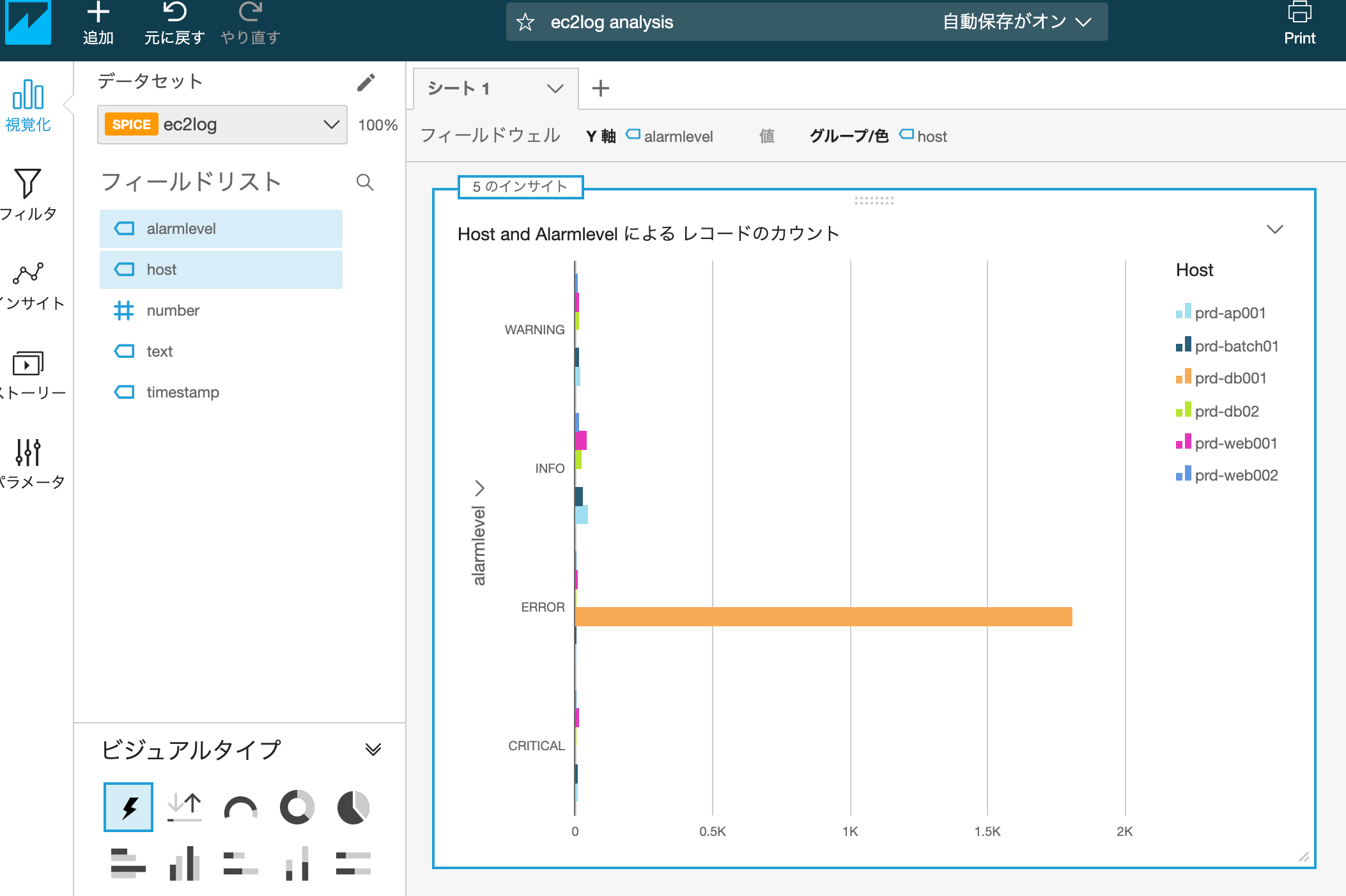
そして最後のLab6では、Glueでデータ変換した結果をS3バケットの別のプレフィックスに保管してAthena→Quicksightで可視化します。
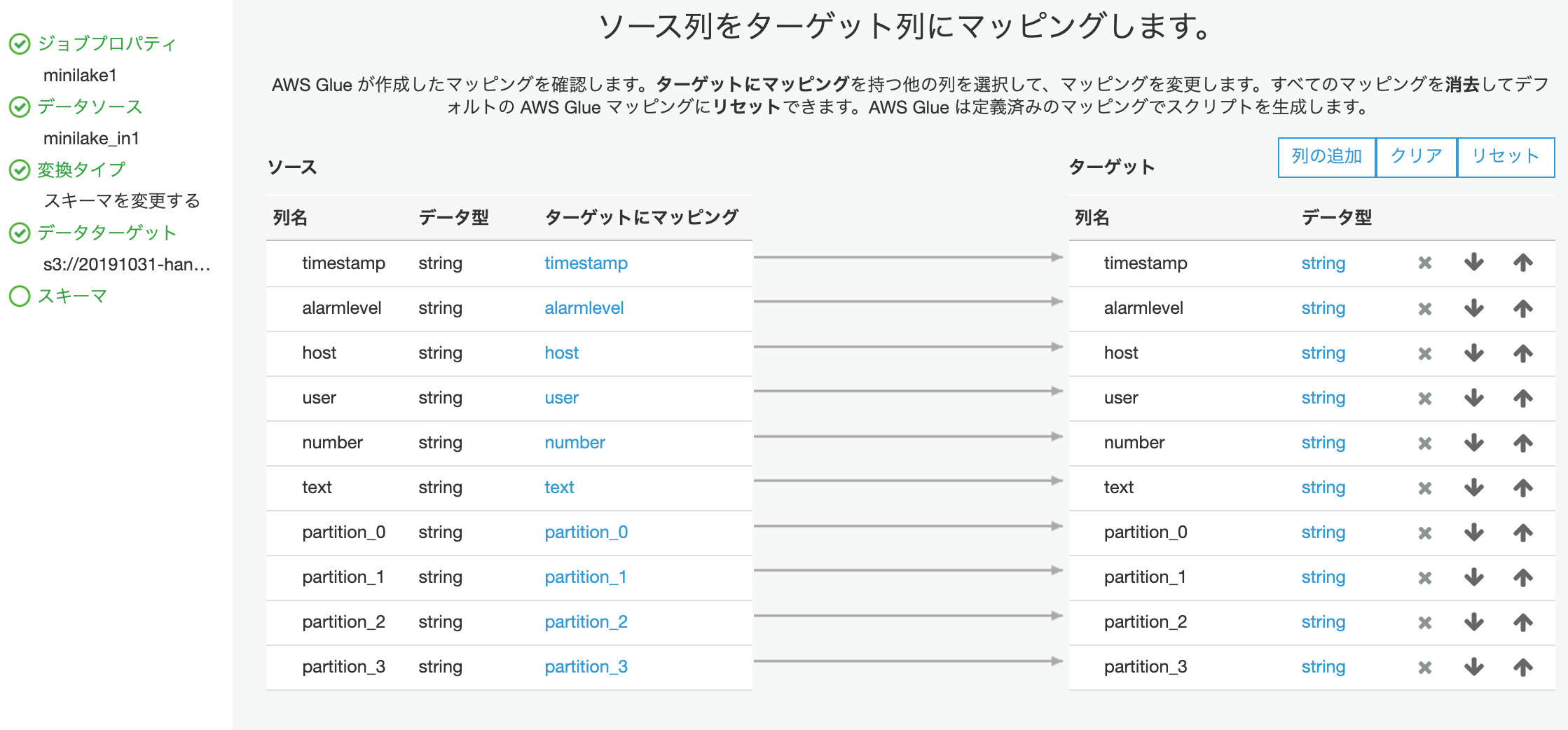
マッピングして変換してETLな感じの画面です。
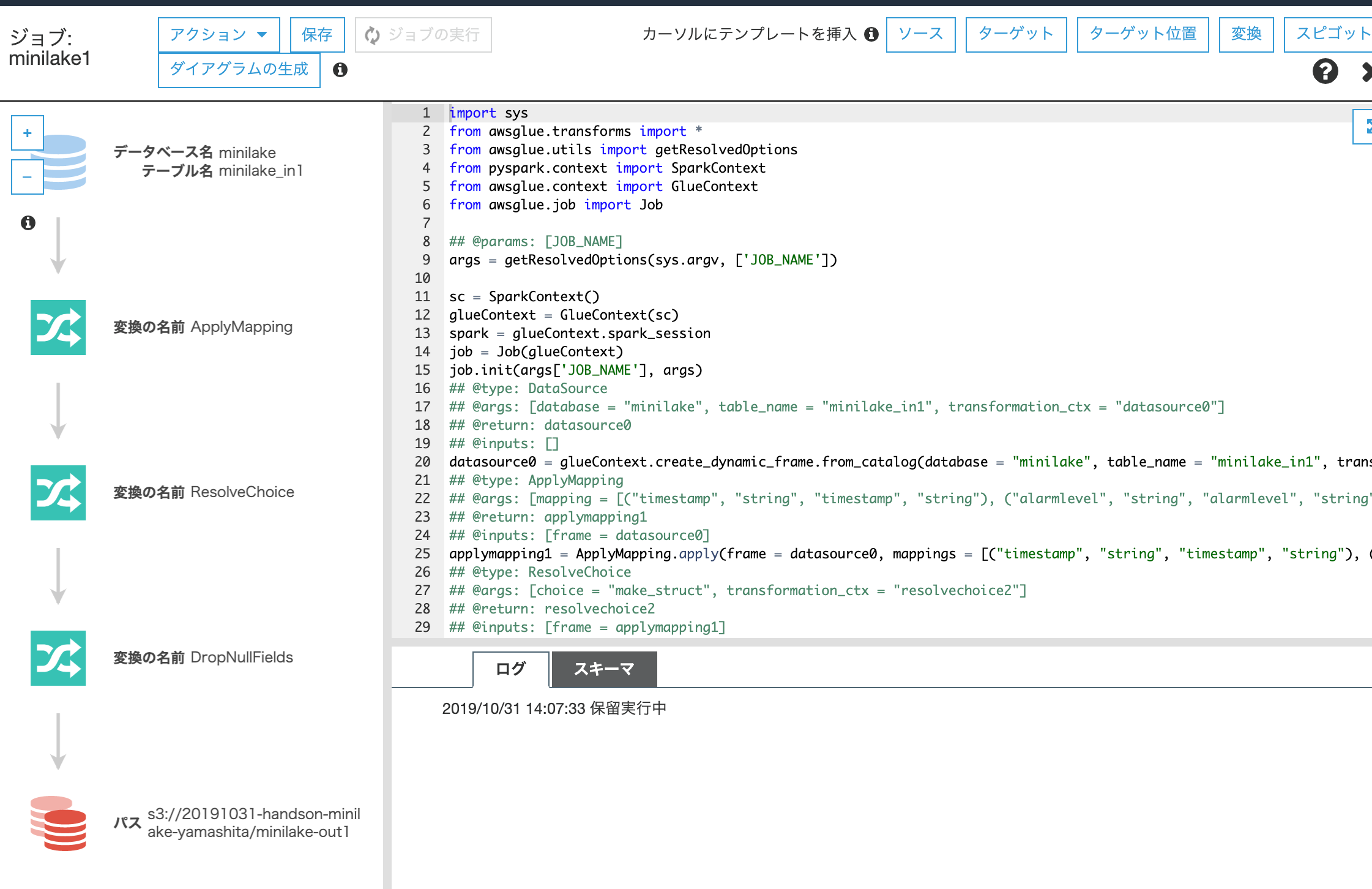
ジョブの実行画面です。
S3に変換後のデータができました。
このまま、クローラーを設定して実行しました。

変換前がjson、変換後がParquetの形式のテーブルが2つできましたので、データの比較をします。
|
1 2 3 4 5 6 |
SELECT count(user) FROM "minilake"."minilake_in1" WHERE user='uchida' AND timestamp >= '2019-10-31 00%' AND timestamp <= '2019-10-31 23%'; |
Run time: 4.25 seconds, Data scanned: 92.57 KB
|
1 2 3 4 5 6 |
SELECT count(user) FROM "minilake"."minilake_out1" WHERE user='uchida' AND timestamp >= '2019-10-31 00%' AND timestamp <= '2019-10-31 23%'; |
Run time: 3.09 seconds, Data scanned: 3.61 KB
どちらも結果6件であってました。
そして実行時間、データのスキャン量は、Parquet形式の方が効率的なことがわかります。
最後にパーティションを設定して出力した結果でさらに確認します。
S3にパーティション化されたプレフィックスでデータができました。
|
1 2 3 4 5 6 |
SELECT count(user) FROM "minilake"."minilake_out2" WHERE user='uchida' AND timestamp >= '2019-10-31 00%' AND timestamp <= '2019-10-31 23%'; |
Run time: 4.46 seconds, Data scanned: 0.85 KB
パーティションを設定することで、スキャン量がさらに小さくなったことがわかりました。
これですべてのラボが完了です。
どっぷりとデータレイクアーキテクチャのファーストステップを試すことができました。
これだけの環境を半日程度で試してしまえるのもすごいですね。
リソース削除
けっこう課金発生するリソースが多いと思うので、今日はハンズオン終了時に削除しました。
削除した手順を以下に記録しておきます。
Glue
- ジョブの削除
- クローラーの削除
- テーブルの削除
- データベースの削除
QuickSight
- VPC接続の削除
- QuickSightサブスクリプション解除
S3
- バケットの削除
Kinesis Firehose
- 配信ストリームの削除
Redshift
- クラスターの削除
VPC
- 手動で設定したセキュリティグループの削除
(ソースとしての設定ルールを先に消さないと削除できないので注意)
Cloudwatch Logs
- 今回作成されたログの削除
CloudWatch
- メトリクスフィルタで作ったアラームの削除
Lambda
- 自動作成されたLogをESSに書き出すLambdaの削除
Elasticsearch Service
- ドメインの削除
IAM
- 2つのロールの削除
CloudFormation
- スタック2つを順番に削除
最後までお読みいただきましてありがとうございました!
「AWS認定資格試験テキスト&問題集 AWS認定ソリューションアーキテクト - プロフェッショナル 改訂第2版」という本を書きました。

「AWS認定資格試験テキスト AWS認定クラウドプラクティショナー 改訂第3版」という本を書きました。

「AWS認定資格試験テキスト AWS認定AIプラクティショナー」という本を書きました。

「ポケットスタディ AWS認定 デベロッパーアソシエイト [DVA-C02対応] 」という本を書きました。

「要点整理から攻略するAWS認定ソリューションアーキテクト-アソシエイト」という本を書きました。

「AWSではじめるLinux入門ガイド」という本を書きました。

開発ベンダー5年、ユーザ企業システム部門通算9年、ITインストラクター5年目でプロトタイプビルダーもやりだしたSoftware Engineerです。
質問はコメントかSNSなどからお気軽にどうぞ。
出来る限りなるべく答えます。
このブログの内容/発言の一切は個人の見解であり、所属する組織とは関係ありません。
このブログは経験したことなどの共有を目的としており、手順や結果などを保証するものではありません。
ご参考にされる際は、読者様自身のご判断にてご対応をお願いいたします。
また、勉強会やイベントのレポートは自分が気になったことをメモしたり、聞いて思ったことを書いていますので、登壇者の意見や発表内容ではありません。
関連記事
-

-
Amazon Keyspacesのキースペースを作成してみました
Amazon Keyspaces(Apache Cassandra互換のマネージ …
-
-
CloudWatchエンドポイントがIPv6に対応したのでCloudWatchエージェントからカスタムメトリクスを送信しました
追記 翌日のブログで、CloudWatchエージェントのアップデートにより、Cl …
-
-
kintoneに登録されたアカウントの電話番号にGoogleカレンダーの予定をAmazon Pollyが読み上げてTwilioから電話でお知らせする(AWS Lambda Python)
Google Calendar Twilio Reminder Googleカレ …
-
-
CloudFrontのカスタムヘッダーがなければALBのルーティングで403レスポンスを返す
大阪リージョンにはWAFがまだないです(2021年4月現在) 今のこのブログの構 …
-
-
ブログのアーキテクチャをコストベースで見直しました
当ブログはAWSで構築しています。 アーキテクチャをコストを最重視して見直しまし …
-
-
AWS SSOのパスワードリマインダーでADのパスワードを変更
AWS Managed Microsoft ADを構築してユーザー追加までで構築 …
-
-
サービスディスカバリを使用してECSサービスの作成
ECSデベロッパーガイドのチュートリアル:サービスディスカバリを使用して、サービ …
-
-
S3 Intelligent-Tieringで高頻度階層(FREQUENT)に戻る「アクセス」にS3 SelectとGlueクローラーが該当するのか確認してみました
ユーザーガイドのS3 Intelligent-Tiering のしくみには、「低 …
-
-
Feedlyのリフレッシュトークンを使ってアクセストークンを取得する
FeedlyというRSSリーダーから連携している構成があります。 Feedlyの …
-
-
Amazon Linux2のCloud9でPython CDKのモジュールインストール
AMIがCloud9AmazonLinux2-2021-02-02T16-48の …