
AWS Lambda(Python)でDynamoDB テーブルを日次で削除/作成(オートスケーリング付き)
2018/12/08
この記事はAWS #2 Advent Calendar 2018に参加した記事です。
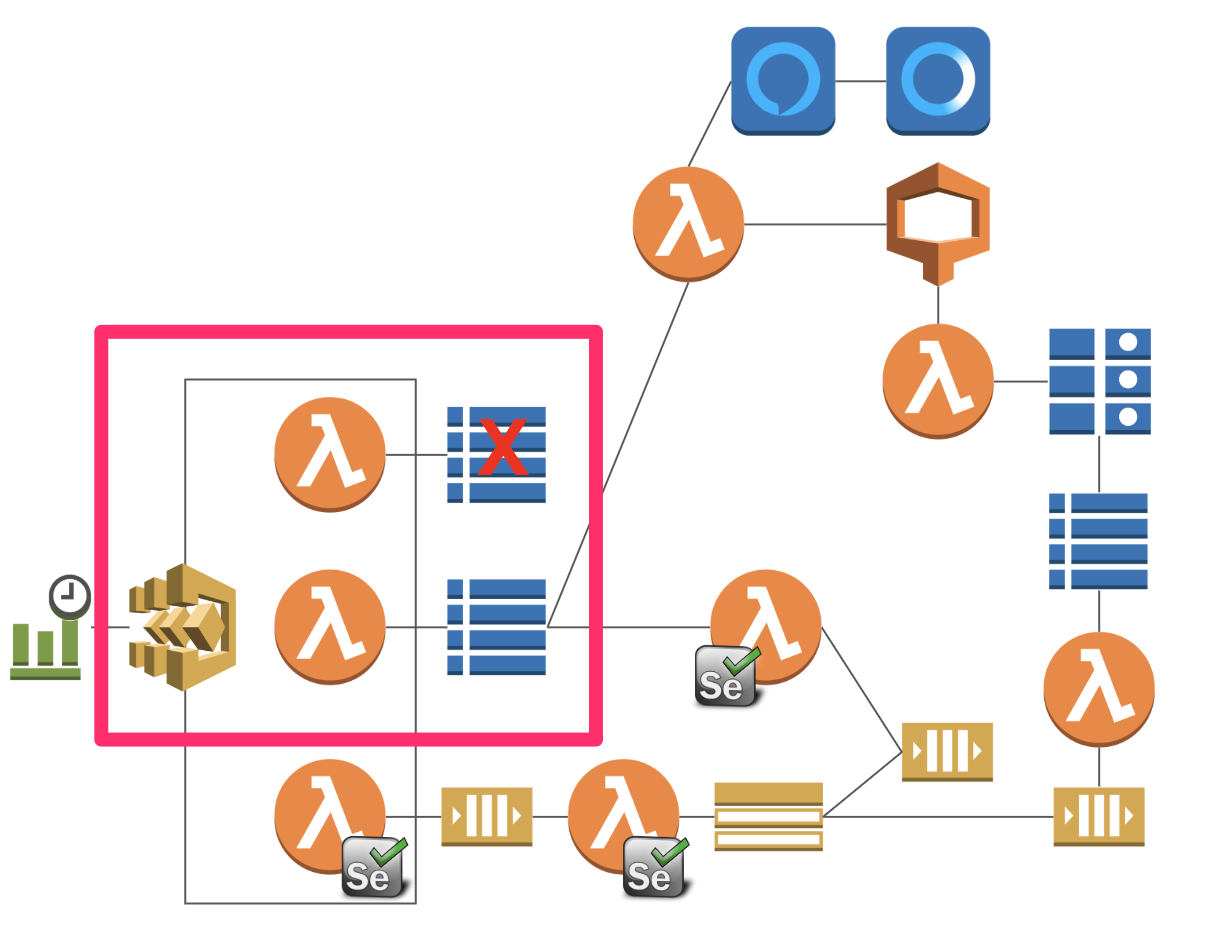
「Selenium, Headless ChromeとAWS Lambdaで夜な夜なスクレイピング」にも書きましたが、上記のようなアーキテクチャで、Alexaスキルの開発を進めていまして、元となる情報をwebとあるwebサイトから収集しています。
日時点での最新情報をDynamoDBに書き込んでいます。
洗い替えでかまわないので、テーブル名に日付け文字列を付加して、毎日作り直しています。
作り直しが完了すれば、スクレイピングを始めるという処理順番をStepFunctionsで設定しています。
DynamoDBテーブルを作るだけなら調べることなくさっさと終わったのですが、キャパシティユニットのオートスケーリングを有効にするところで、少し調べたので書き残します。
目次
StepFunctions
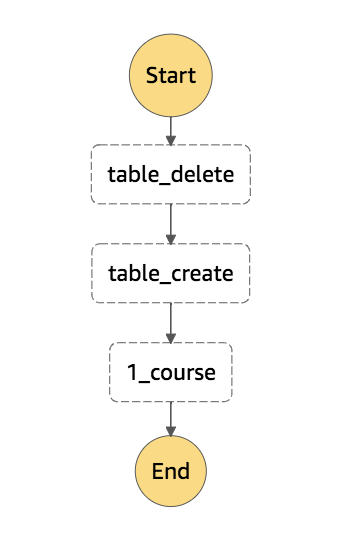
一応StepFunctionsのステートマシンのJSONです。
順番に処理しているだけなのでシンプルです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ "StartAt": "table_delete", "States": { "table_delete": { "Type": "Task", "Next": "table_create", "Resource": "arn:aws:lambda:ap-northeast-1:123456789012:function:table_delete" }, "table_create": { "Type": "Task", "Next": "1_course", "Resource": "arn:aws:lambda:ap-northeast-1:123456789012:function:table_create" }, "1_course": { "Type": "Task", "Resource": "arn:aws:lambda:ap-northeast-1:123456789012:function:1_course", "End": true } } } |
では、Lambdaのコードを見ていきますが、削除の前に作成から見ます。
作成したものを翌々日に削除するので、何を作成しているかから見たほうがわかりやすいからです。
テーブル作成(オートスケーリング付き)
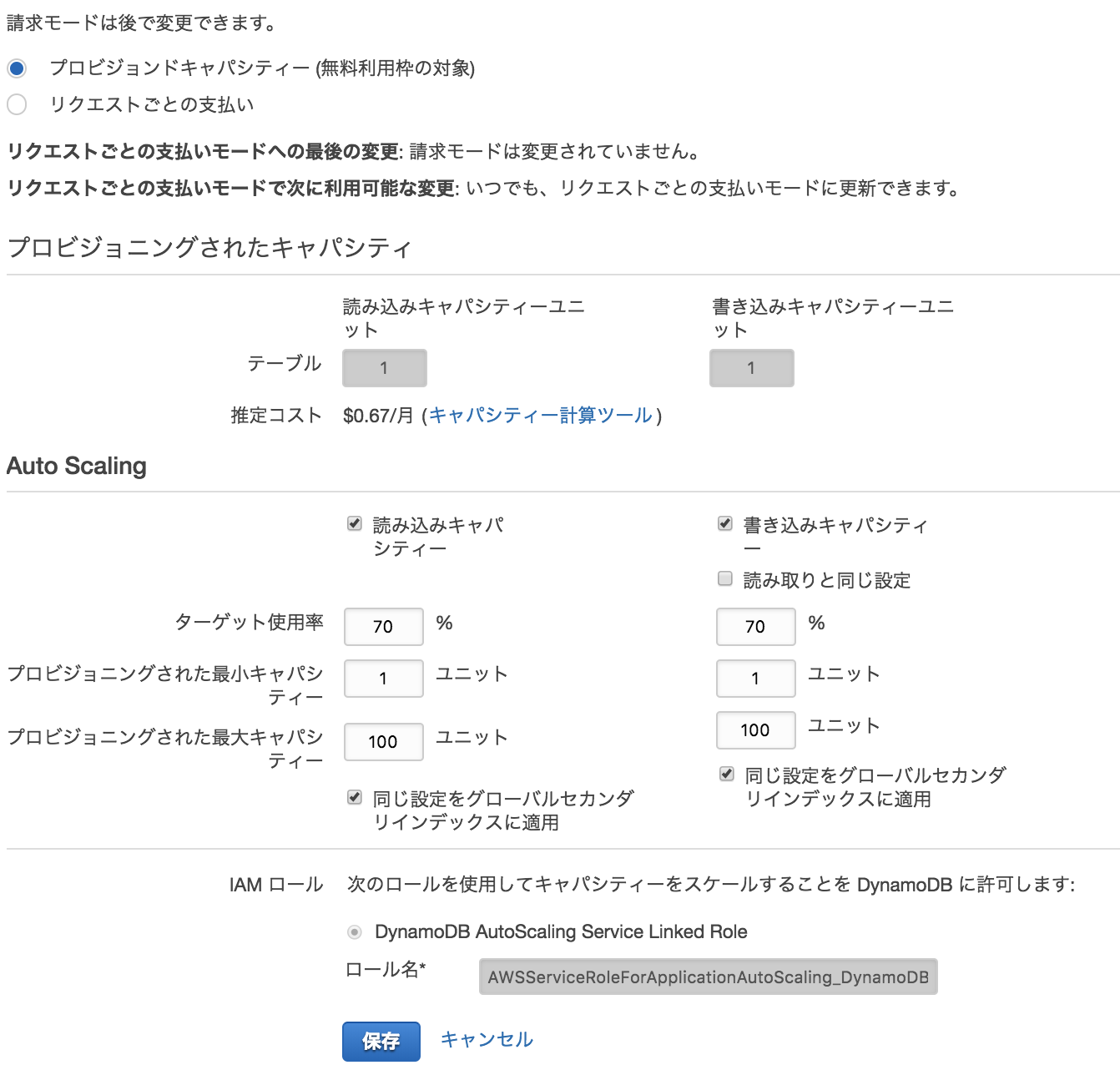
現在、マネジメントコンソールでDynamoDBテーブルを作成すると、オートスケーリングがデフォルトで有効になります。
ですが、LambdaのSDK boto3ではそこまではやってくれません。
このLambdaは環境変数で、タイムゾーンをJSTにしています。
具体的にはLambdaの環境変数キーに TZ , 値に Asia/Toky としています。
そして、StepFunctionsはCloudWatch Eventsで23時にターゲットとして実行されています。
UTCでは9時間の時差があるので、Cron式で 0 14 * * ? としています。
それを踏まえた上で見ていきます。
まず最初に作成するテーブル名を決めます。
明日の日付が入るテーブル名にします。
|
1 2 3 4 |
table_name = 'course_detail{tomorrow}'.format( tomorrow=(datetime.now() + timedelta(days=1)).strftime('%Y%m%d') ) |
そしてDynamoDBテーブルを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
dynamodb = boto3.client('dynamodb') response = dynamodb.create_table( TableName=table_name, AttributeDefinitions=[ { 'AttributeName': 'course_code', 'AttributeType': 'S' }, { 'AttributeName': 'row_no', 'AttributeType': 'N' }, { 'AttributeName': 'venue', 'AttributeType': 'S' }, ], KeySchema=[ { 'AttributeName': 'course_code', 'KeyType': 'HASH' }, { 'AttributeName': 'row_no', 'KeyType': 'RANGE' } ], LocalSecondaryIndexes=[ { 'IndexName': 'venue_index', 'KeySchema': [ { 'AttributeName': 'course_code', 'KeyType': 'HASH' }, { 'AttributeName': 'venue', 'KeyType': 'RANGE' } ], 'Projection': { 'ProjectionType': 'INCLUDE', 'NonKeyAttributes': [ 'date' ] } } ], ProvisionedThroughput={ 'ReadCapacityUnits': 1, 'WriteCapacityUnits': 100 } ) waiter = dynamodb.get_waiter('table_exists') waiter.wait( TableName=table_name ) |
ローカルセカンダリインデックスを持つDynamoDBテーブルを作成しました。
waiterを使ってテーブルが作成完了するまで待ちます。
次にこのテーブルにRCU,WCUそれぞれのオートスケーリングを設定していきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
autoscaling_client = boto3.client('application-autoscaling') response = autoscaling_client.register_scalable_target( ServiceNamespace='dynamodb', ResourceId='table/{table_name}'.format( table_name=table_name ), ScalableDimension='dynamodb:table:ReadCapacityUnits', MinCapacity=1, MaxCapacity=100, RoleARN=ROLE_ARN ) response = autoscaling_client.register_scalable_target( ServiceNamespace='dynamodb', ResourceId='table/{table_name}'.format( table_name=table_name ), ScalableDimension='dynamodb:table:WriteCapacityUnits', MinCapacity=1, MaxCapacity=100, RoleARN=ROLE_ARN ) |
オートスケーリングを設定するには、application-autoscaling クライアントが必要でした。
dynamodb:table:ReadCapacityUnits, dynamodb:table:WriteCapacityUnitsでそれぞれ設定します。
これで完了かと思うとそうではないのですね。
この段階ではスケールする枠だけが決まって、いつスケールするかの設定が入っていません。
そうです。スケーリングポリシーもCloudWatchアラームも設定されていません。
次にその設定をしていきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
percent_of_use_to_aim_for = 70.0 scale_out_cooldown_in_seconds = 60 scale_in_cooldown_in_seconds = 60 autoscaling_client.put_scaling_policy( ServiceNamespace='dynamodb', ResourceId='table/{table_name}'.format( table_name=table_name ), PolicyType='TargetTrackingScaling', PolicyName='{table_name}ReadCapacity'.format( table_name=table_name ), ScalableDimension='dynamodb:table:ReadCapacityUnits', TargetTrackingScalingPolicyConfiguration={ 'TargetValue': percent_of_use_to_aim_for, 'PredefinedMetricSpecification': { 'PredefinedMetricType': 'DynamoDBReadCapacityUtilization' }, 'ScaleOutCooldown': scale_out_cooldown_in_seconds, 'ScaleInCooldown': scale_in_cooldown_in_seconds } ) autoscaling_client.put_scaling_policy( ServiceNamespace='dynamodb', ResourceId='table/{table_name}'.format( table_name=table_name ), PolicyType='TargetTrackingScaling', PolicyName='{table_name}WriteCapacity'.format( table_name=table_name ), ScalableDimension='dynamodb:table:WriteCapacityUnits', TargetTrackingScalingPolicyConfiguration={ 'TargetValue': percent_of_use_to_aim_for, 'PredefinedMetricSpecification': { 'PredefinedMetricType': 'DynamoDBWriteCapacityUtilization' }, 'ScaleOutCooldown': scale_out_cooldown_in_seconds, 'ScaleInCooldown': scale_in_cooldown_in_seconds } ) |
application-autoscaling クライアントのput_scaling_policyを使いました。
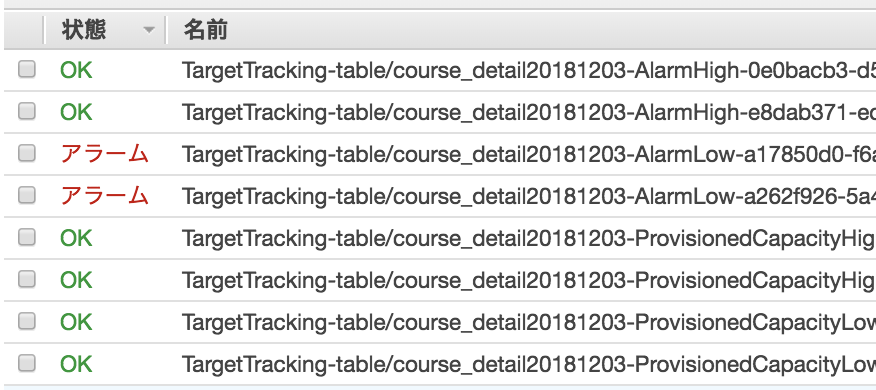
これでDynamoDBのオートスケーリングとCloudWatchのアラームも出来ました。
テーブル削除(CloudWatchアラームも削除)
次にテーブルを削除するコードを見ます。
DynamoDBのテーブルだけが削除されてアラームが残っていては余分なコストがかかってしまいます。
ですので、消し忘れのないようにCloudWatchアラームも削除します。
|
1 2 3 4 |
table_name = 'course_detail{yesterday}'.format( yesterday=(datetime.now() - timedelta(days=1)).strftime('%Y%m%d') ) |
テーブルは2日間は保持しておくので、昨日の日付のテーブルを削除しています。
|
1 2 3 4 5 |
dynamodb = boto3.client('dynamodb') response = dynamodb.delete_table( TableName=table_name ) |
テーブルを削除します。
テーブルに追加したスケーラブルターゲットもあわせて削除されました。
でもこれだけではCloudWatchアラームが残ります。
オートスケーリングポリシーを削除します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
autoscaling_client = boto3.client('application-autoscaling') response = autoscaling_client.delete_scaling_policy( PolicyName='{table_name}ReadCapacity'.format( table_name=table_name ), ServiceNamespace='dynamodb', ResourceId='table/{table_name}'.format( table_name=table_name ), ScalableDimension='dynamodb:table:ReadCapacityUnits' ) response = autoscaling_client.delete_scaling_policy( PolicyName='{table_name}WriteCapacity'.format( table_name=table_name ), ServiceNamespace='dynamodb', ResourceId='table/{table_name}'.format( table_name=table_name ), ScalableDimension='dynamodb:table:WriteCapacityUnits' ) |
これで掃除完了です。
最後までお読みいただきましてありがとうございました!
「AWS認定資格試験テキスト&問題集 AWS認定ソリューションアーキテクト - プロフェッショナル 改訂第2版」という本を書きました。

「AWS認定資格試験テキスト AWS認定クラウドプラクティショナー 改訂第3版」という本を書きました。

「AWS認定資格試験テキスト AWS認定AIプラクティショナー」という本を書きました。

「ポケットスタディ AWS認定 デベロッパーアソシエイト [DVA-C02対応] 」という本を書きました。

「要点整理から攻略するAWS認定ソリューションアーキテクト-アソシエイト」という本を書きました。

「AWSではじめるLinux入門ガイド」という本を書きました。

開発ベンダー5年、ユーザ企業システム部門通算9年、ITインストラクター5年目でプロトタイプビルダーもやりだしたSoftware Engineerです。
質問はコメントかSNSなどからお気軽にどうぞ。
出来る限りなるべく答えます。
このブログの内容/発言の一切は個人の見解であり、所属する組織とは関係ありません。
このブログは経験したことなどの共有を目的としており、手順や結果などを保証するものではありません。
ご参考にされる際は、読者様自身のご判断にてご対応をお願いいたします。
また、勉強会やイベントのレポートは自分が気になったことをメモしたり、聞いて思ったことを書いていますので、登壇者の意見や発表内容ではありません。
関連記事
-

-
Amazon CloudWatch RUMはじめました
新機能 – Amazon CloudWatch RUM をご紹介 2021年12 …
-
-
Well-Architected Tool レンズヴァージョンアップ
当ブログのWell-Architectedレビューを久しぶりにやろうと思い、We …
-
-
S3バケットポリシーで特定のVPCエンドポイント以外からのリクエストを拒否しつつメンテナンスはしたい
特定のVPCで実行されているEC2のアプリケーションからのリクエストだけを許可し …
-
-
RDS ProxyをAurora MySQLで
Lambda関数をたくさん同時実行してMySQLにアクセスしても大丈夫なようにR …
-
-
Lambda関数で自分自身の環境変数を更新する
Twitterでツイート検索するAPIを試してみるでツイートの取得を重複させない …
-
-
Amazon SageMaker Canvas Immersion Dayワークショップのエンドツーエンド機械学習の記録
Amazon SageMaker Canvas Immersion Dayという …
-
-
Amazon SESでメール受信
Amazon SES(Simple Email Service)にメールドメイン …
-
-
Amazon SESの受信ルールでSNSトピックを追加
SESの受信ルールにSNSトピックを設定してみました。 [View Active …
-
-
Transit GatewayポリシーテーブルでCloud WANのコアネットワークに接続しました
「ポリシーテーブルってなんですか?」のご質問をいただいたので設定してみました。 …
-
-
EKS「現在の IAM プリンシパルは、このクラスター上の Kubernetes オブジェクトにアクセスできません」
マネジメントコンソールでクラスターのオブジェクトを見ようと、リソースの名前空間や …