
Amazon SageMaker Canvas Immersion Dayワークショップのエンドツーエンド機械学習の記録
Amazon SageMaker Canvas Immersion DayというAmazon SageMaker Canvasを試せるワークショップがあります。
その「エンドツーエンド機械学習」をやった記録です。
エンドツーエンドというだけあって、MLパイプラインをすべてSageMaker Canvasで実行するラボでした。
目次
環境
SageMakerドメインとユーザープロファイルは、すでに構築済みで使用していたものを使いました。
ほぼセルフペースド ラボに書かれている内容と同じような環境です。
データセットの前処理
ラボに用意されている定期預金データをローカルにダウンロードしました。
定期預金データは、定期預金を紹介するキャンペーンのマーケティングに関係するデータです。
最後のy列に定期預金に加入したかどうかがyes/noの値です。
新しいデータでこのyを予測するモデルを作成します。
CanvasでData Wranglerをクリックして、[Import and prepare]でTabularを選択しました。
データソースにLocal uploadを選択して、ダウンロードした定期預金データをアップロードしました。
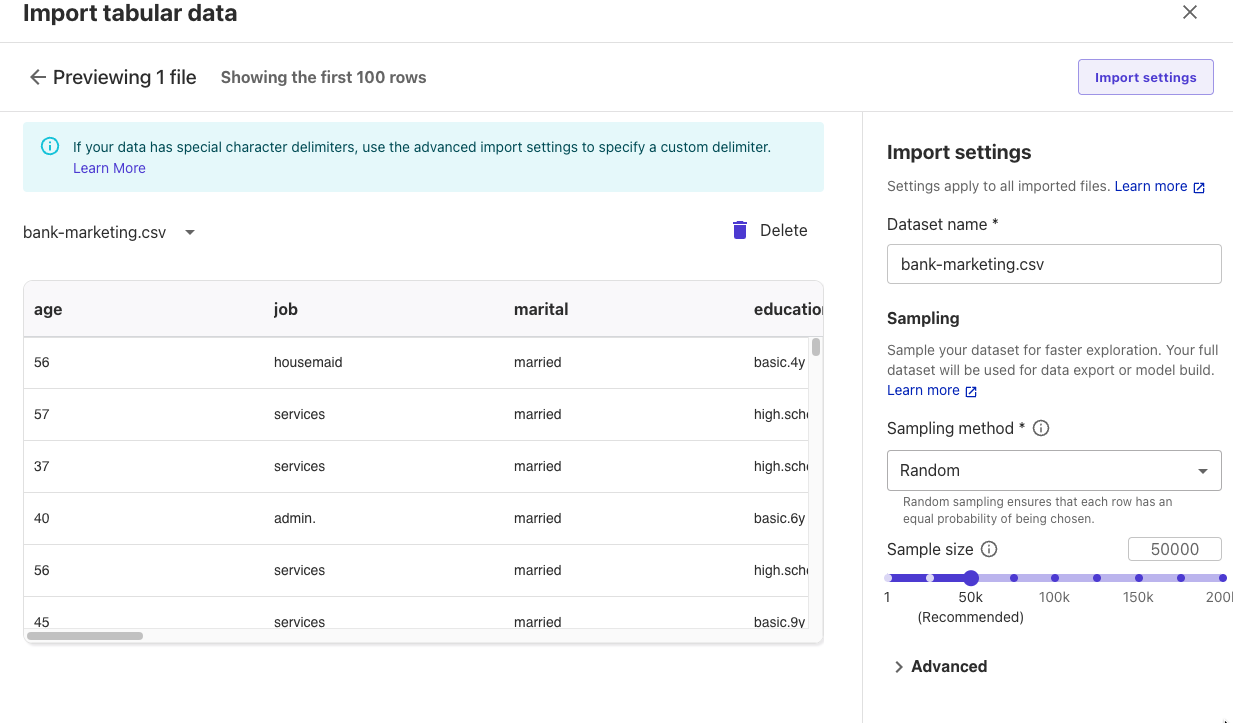
データプレビューが表示されましたので、[Import]をクリックしました。
まずGet data insightsをクリックしました。
Analysis type: Data quality and insights report
Analysis name: baseline
Probllemtype: Classification
Data size: Sampled dataset
上記の設定をして[Create]をクリックしました。
データ分析結果が表示されます。
ダウンロードボタンからレポートをダウンロードもできました。
警告が表示されていてわかりやすいです。
3点のMedium(中程度)の警告がありました。
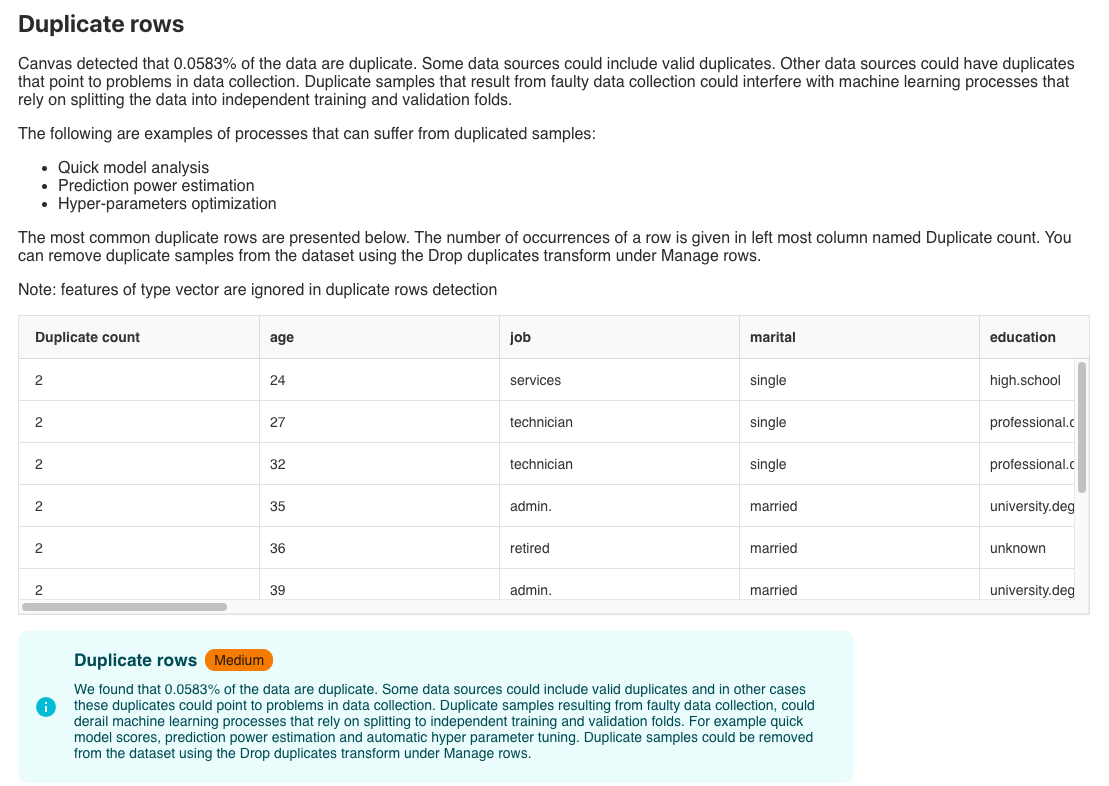
0.0583%の行の重複があるようです。
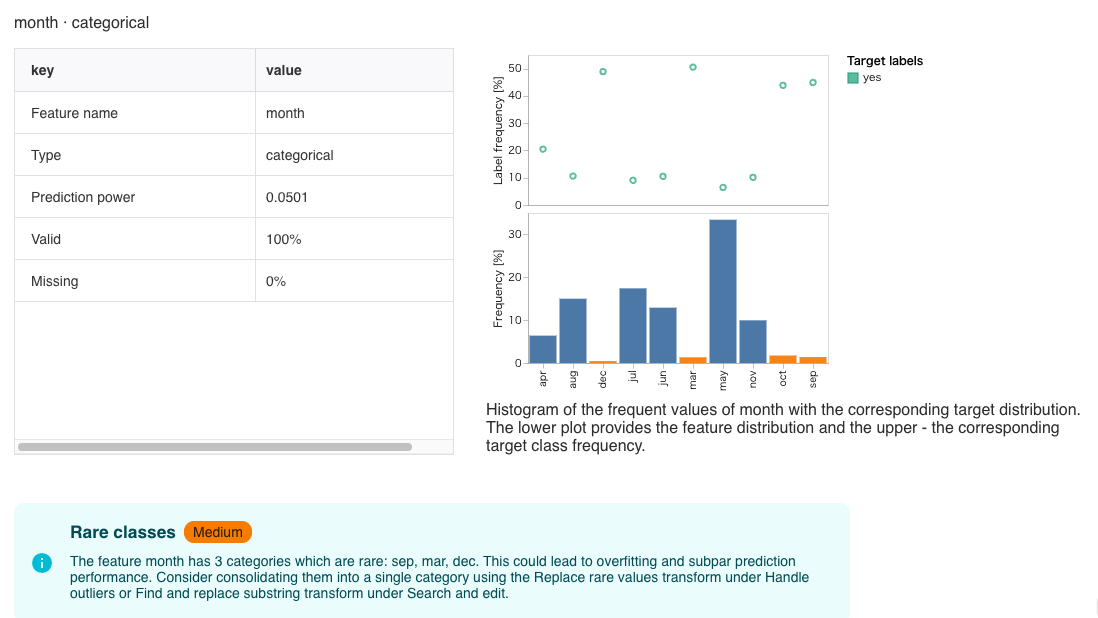
monthの3月、9月、12月がレアなカテゴリーになっている。
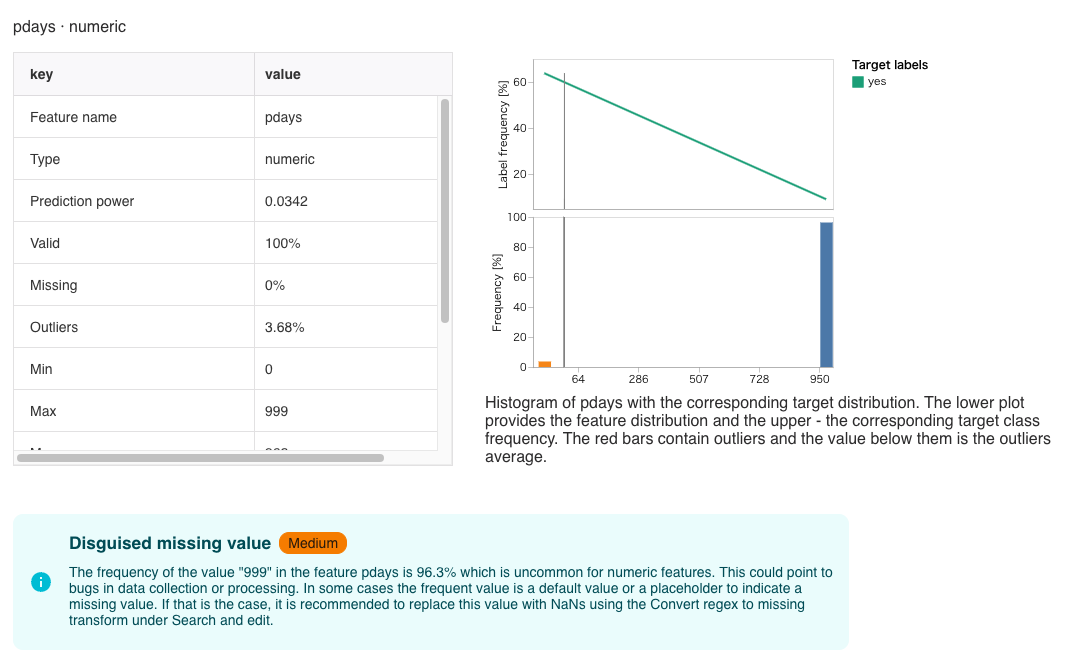
pdaysの999という値が全体の96.3%になっている。
このままモデルの学習をした場合に、モデルの推論結果によくない影響を及ぼす可能性があるものが、警告としてピックアップされました。
データの分析が終わったので、前処理を設定します。
Data flowに戻って、Add transformを選択しました。
[Add transform]-[Manage columns]を選択しました。
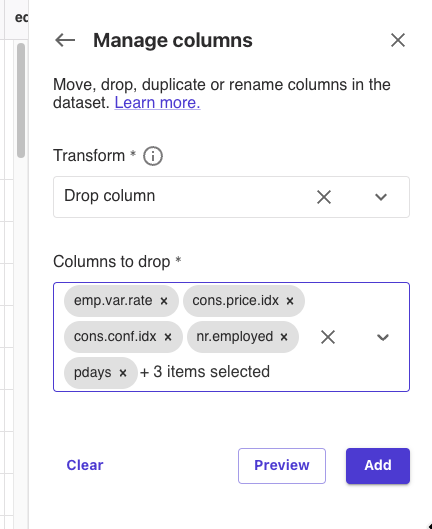
Transform: Drop column
Columns to drop: emp.var.rate, cons.price.idx, cons.conf.idx, nr.employed, pdays, previous, poutcome, euribor3m
上記の設定で[Add]をクリックしました。
モデルトレーニングに不要な列を削除しました。
次に自然言語でのデータ分析と変換適用を試します。
Data flowに戻って、Chat for data prepを選択しました。
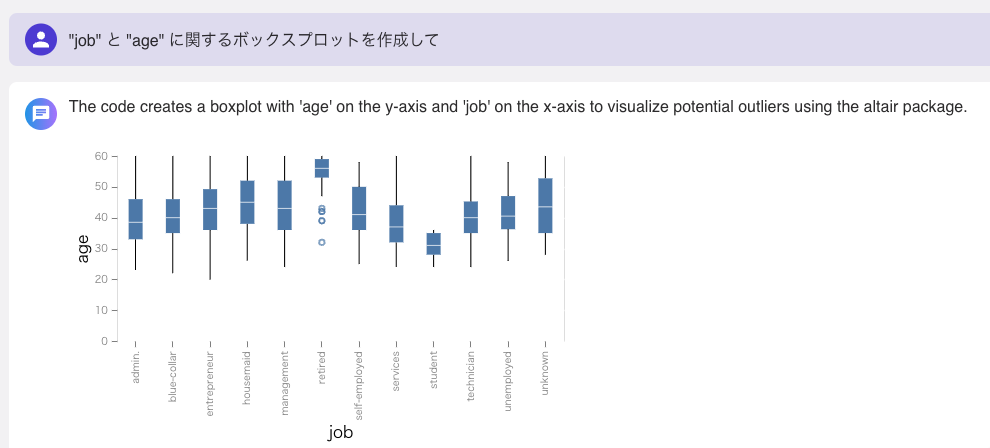
「”job” と “age” に関するボックスプロットを作成して」と入力して実行すると、ボックスプロットが表示されました。
職業別の年齢分布が表示されました。
retiredが高年齢ではあるが、いくつかのデータでは外れ値として、若い年齢のデータもあるようです。
studentは若い年齢層です。
ほかの職業はだいたい中ぐらいの年齢です。
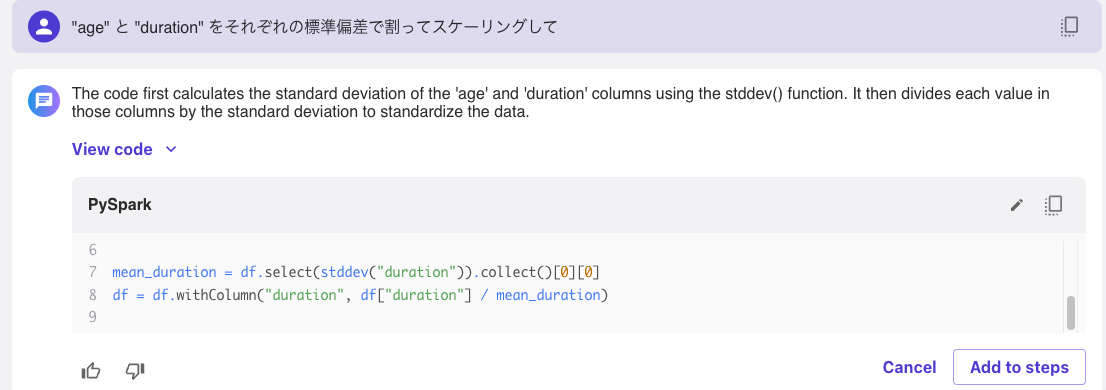
「”age” と “duration” をそれぞれの標準偏差で割ってスケーリングして」と入力して実行すると、データを変換するためのPythonコードを生成してくれました。
[Add to steps]でデータ前処理のステップに追加しました。
モデルの学習
Data flowに戻って、Create modelを選択しました。
Dataset details: BankDataset
Model details: BankModel
Problem type: Predictive analysis
Target column: y
yがyesかnoかを予測するモデルを作成します。
[Export and create model]をクリックしました。
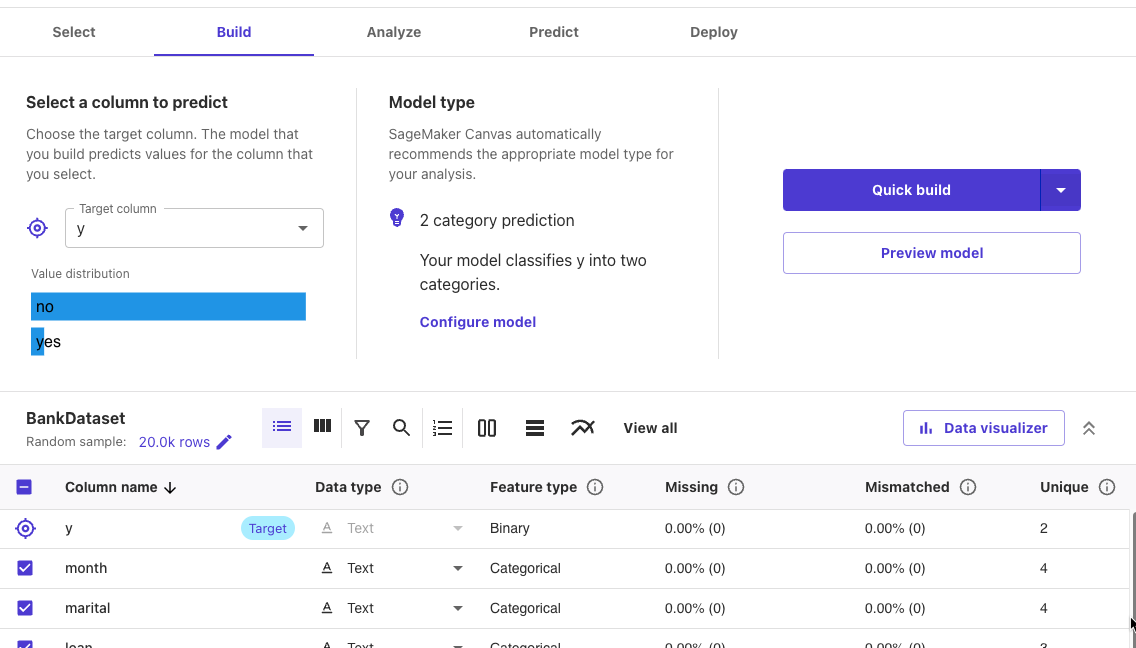
Buildタブに移動しました。
Targetになっているyではnoのデータが95.43%あるようです。
ここで、configure modelを選択しました。
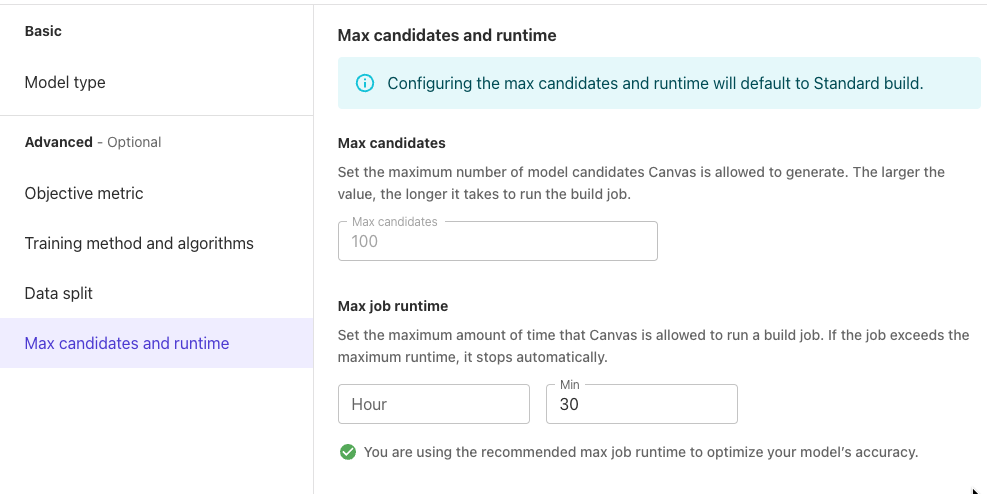
モデルの学習時間を30分にしました。

Standard buildをクリックしました。
モデルの学習が始まりました。
モデルの評価
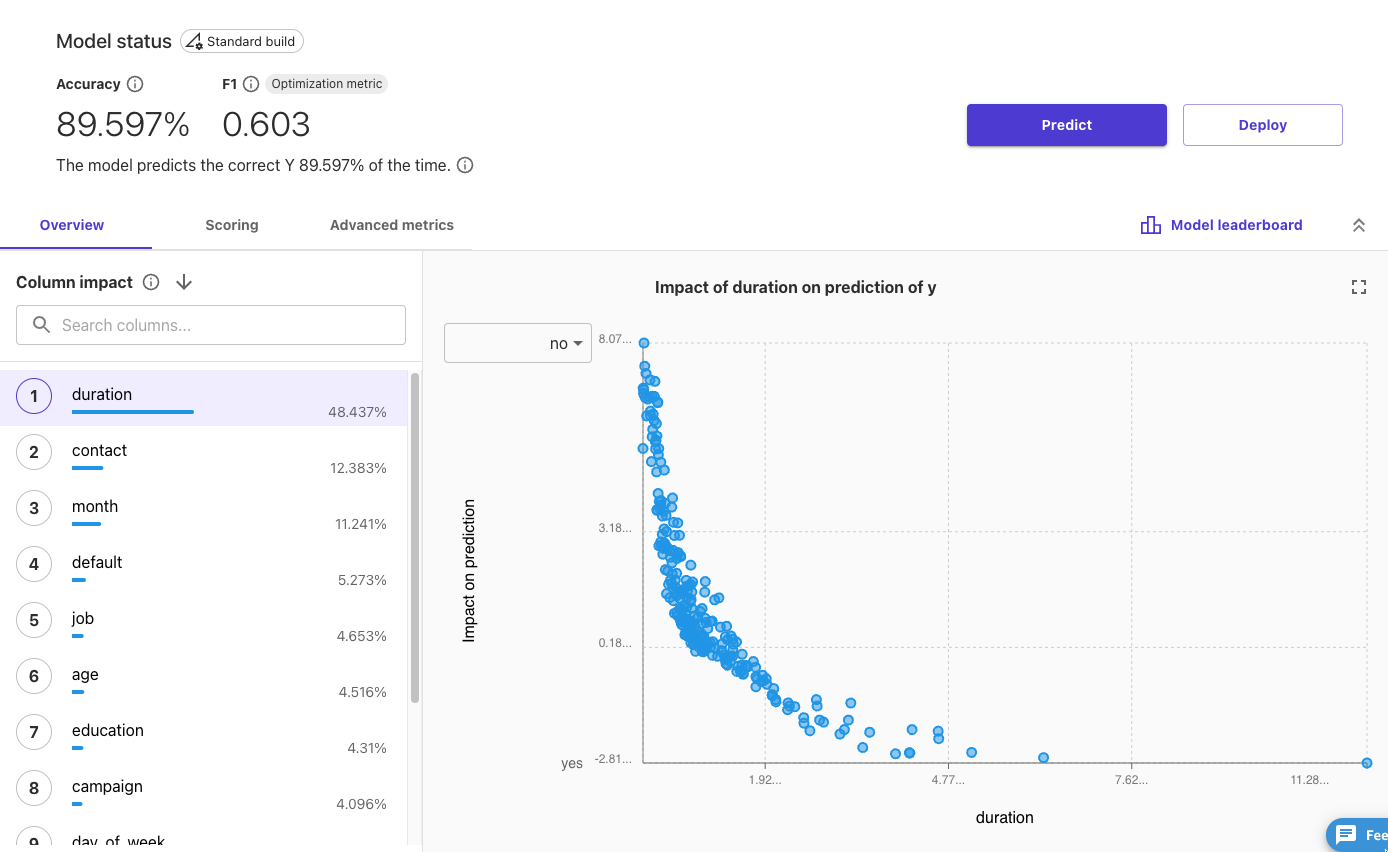
モデルの作成が完了すると、評価結果も表示されました。
89.597%の確率で正しく予測できるモデルになりました。
F1スコア(0-1、完璧なモデルは1)は0.603でした。
Column impactでは、予測にdurationが最も影響を与えていることがわかりました。
durationはキャンペーン電話の連絡秒数です。
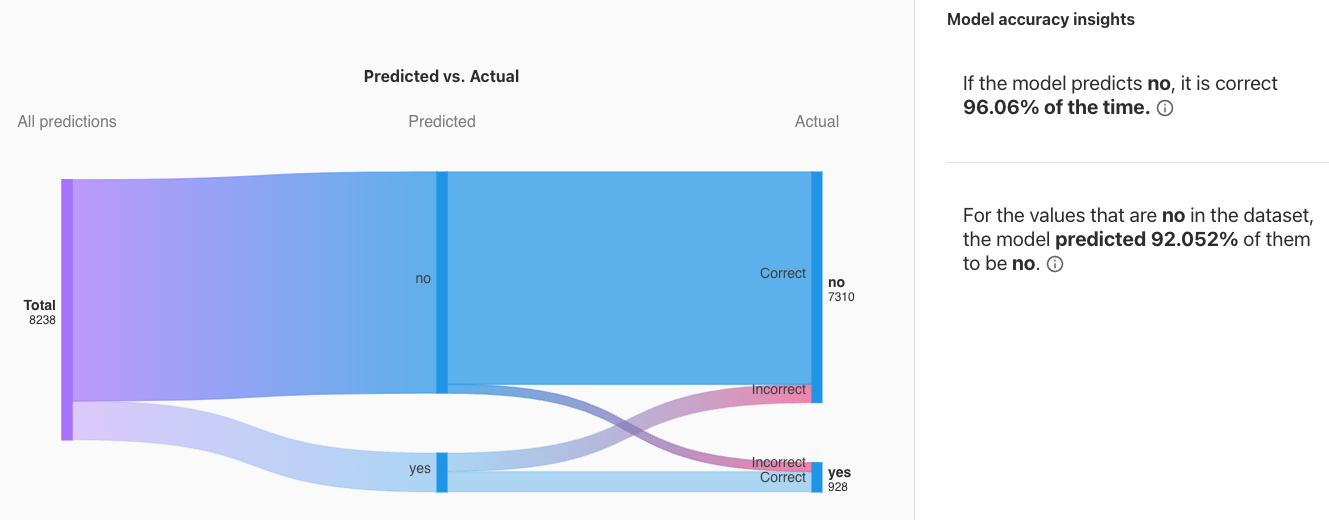
Scoringタブにはサンキーダイアグラムがありました。
検証データでどのようにモデルが予測できたかを視覚化しています。
モデルがNoと予測した場合、96.06%が正解していました。
Noが正解のデータに対しては、モデルは92.052%でNoと予測しています。
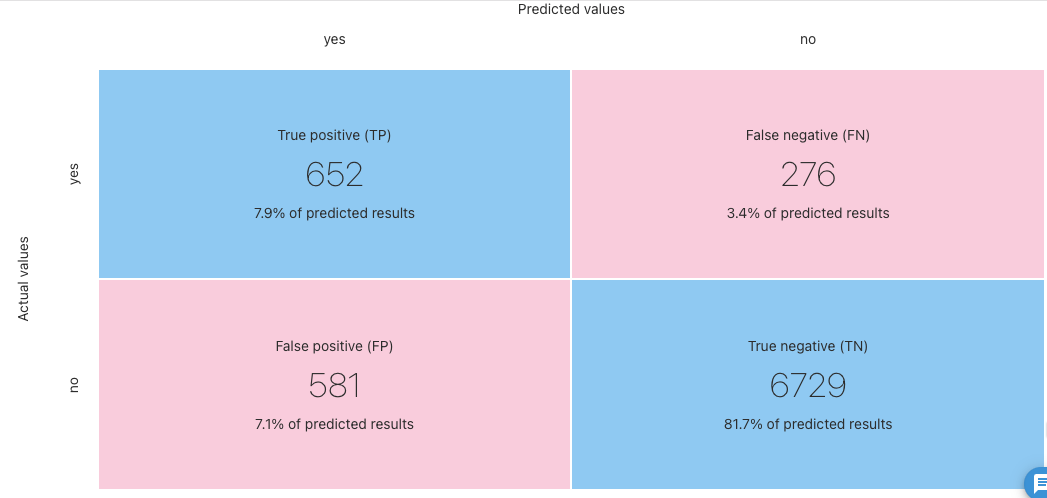
Advanced meticsには混同行列があります。
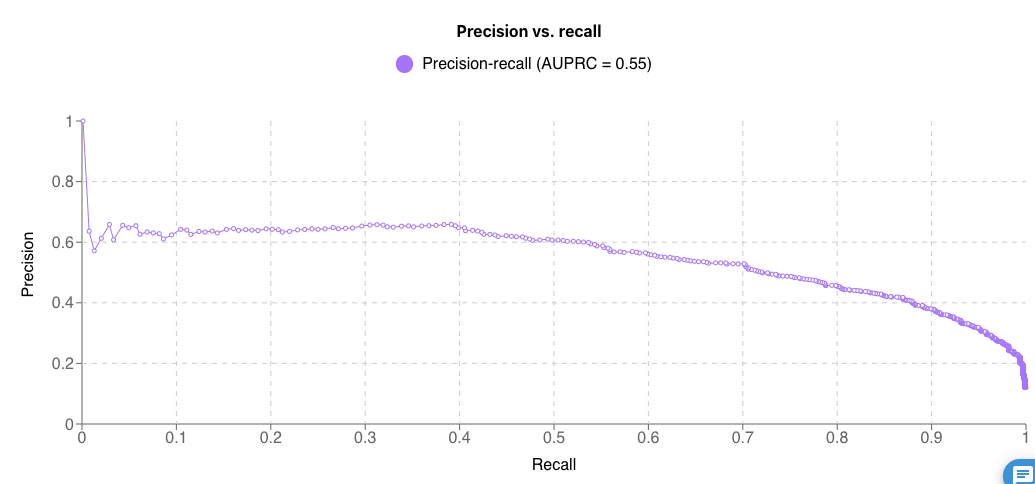
適合率(Precision)-再現率(Recall)曲線もあります。
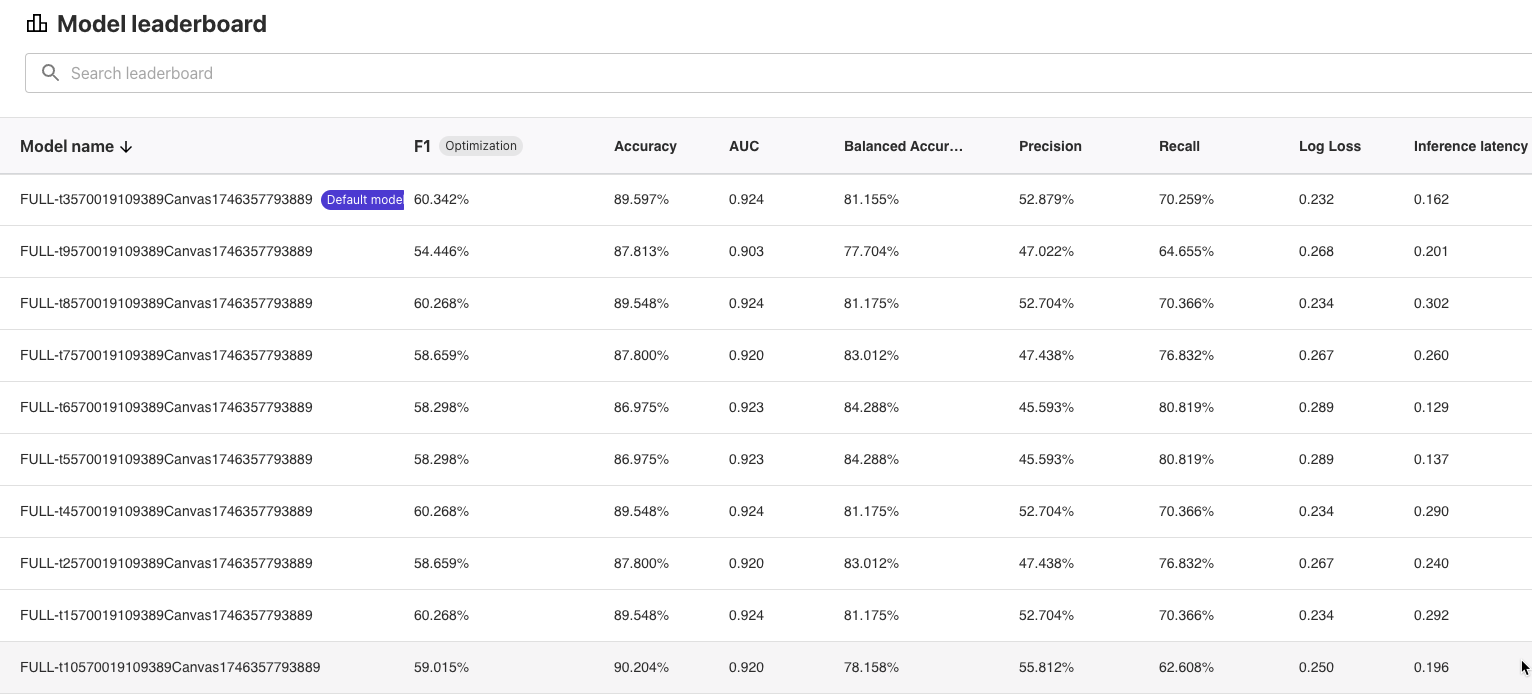
Model leaderboardでは複数の候補モデルの比較結果も表示できます。
推論の生成
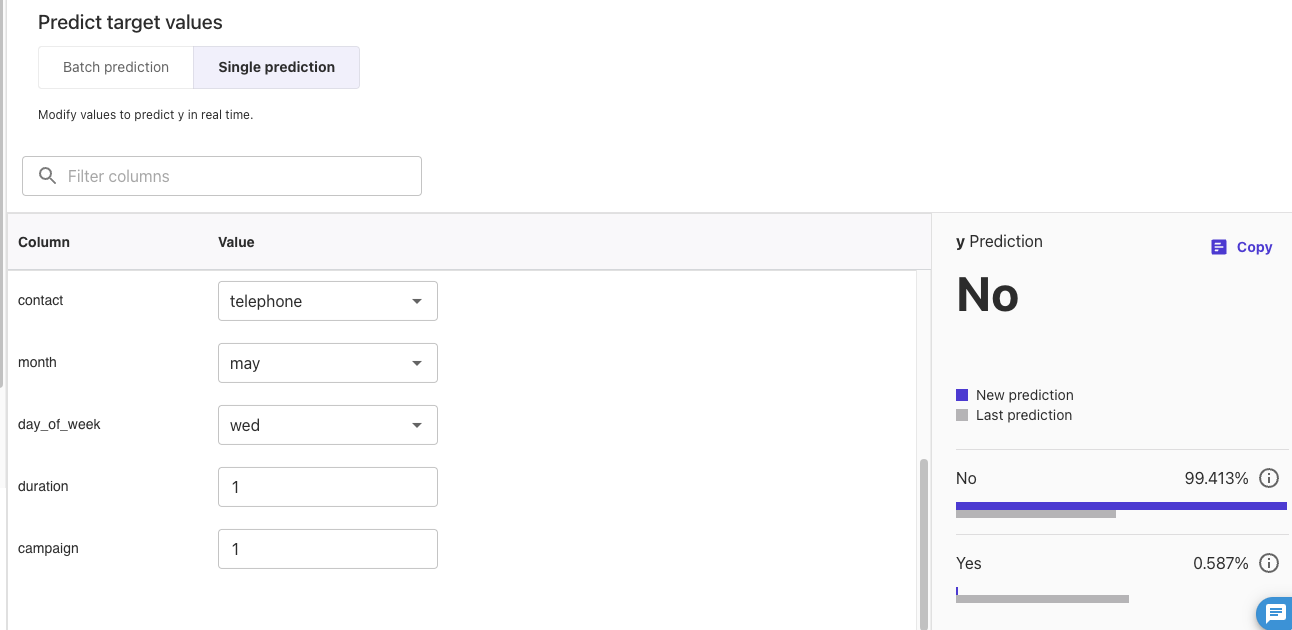
PredictタブでSingle predictionを選択すると、1つの推論に対しての予測結果を確認できます。
durationが1の場合、Noとなりました。
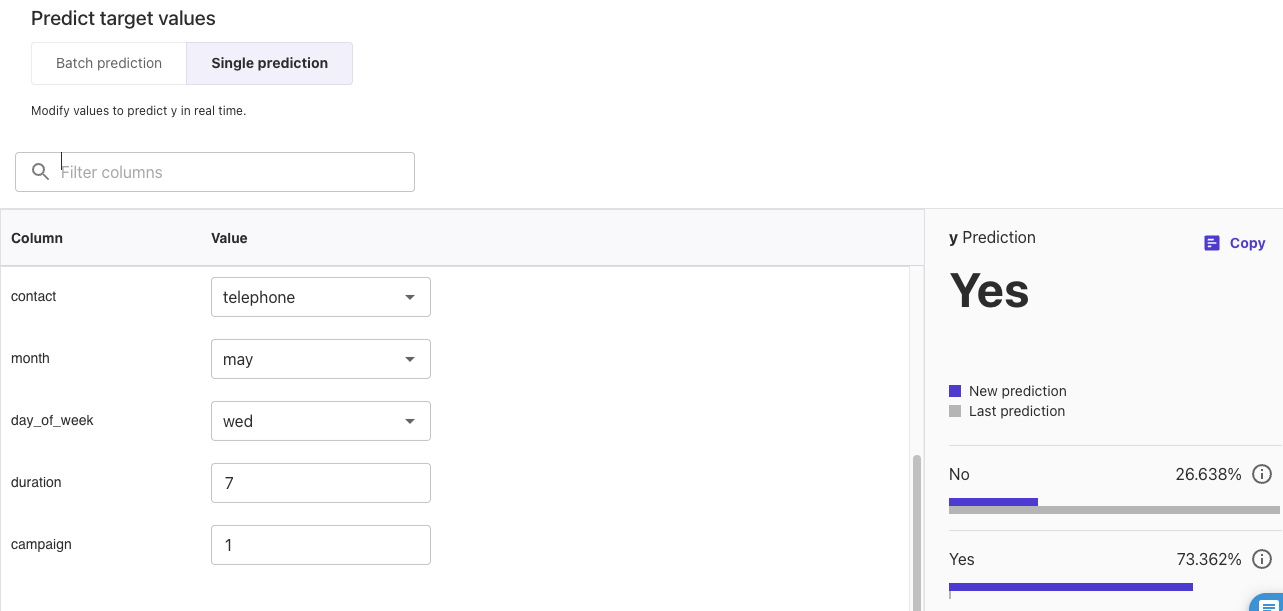
durationを7にすると、Yesとなりました。
Batch predictionメニューもあるので、テスト用のデータセットでまとめて推論を実行できます。
デプロイ
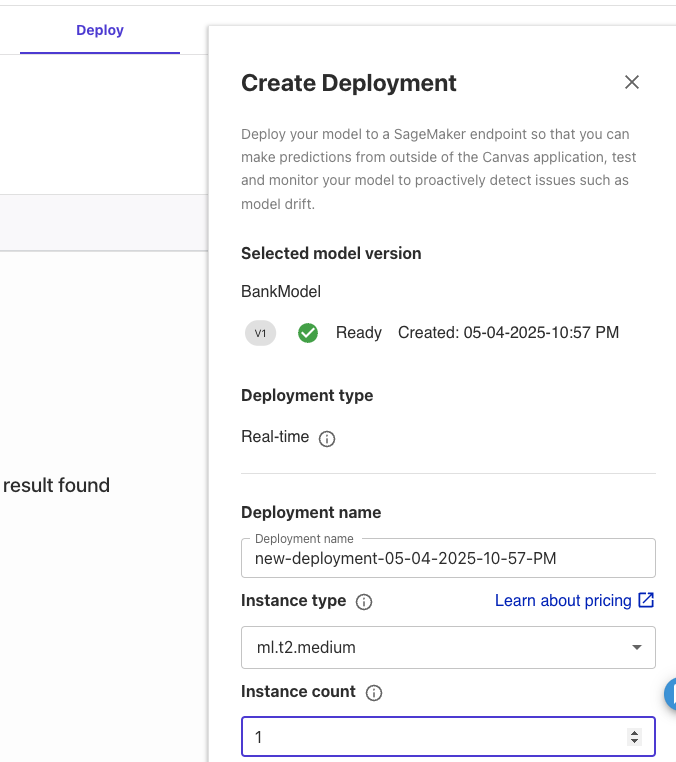
Deployタブで[+ Create Deployment]ボタンをクリックすると、インスタンスタイプやインスタンス数を選択してエンドポイントをデプロイできます。
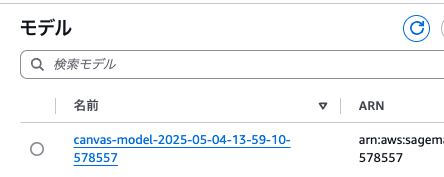

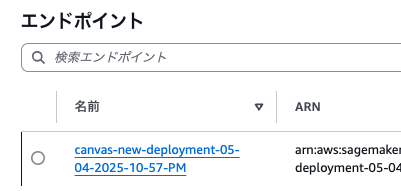
デプロイすると、モデル、エンドポイント設定、エンドポイントが作成されました。
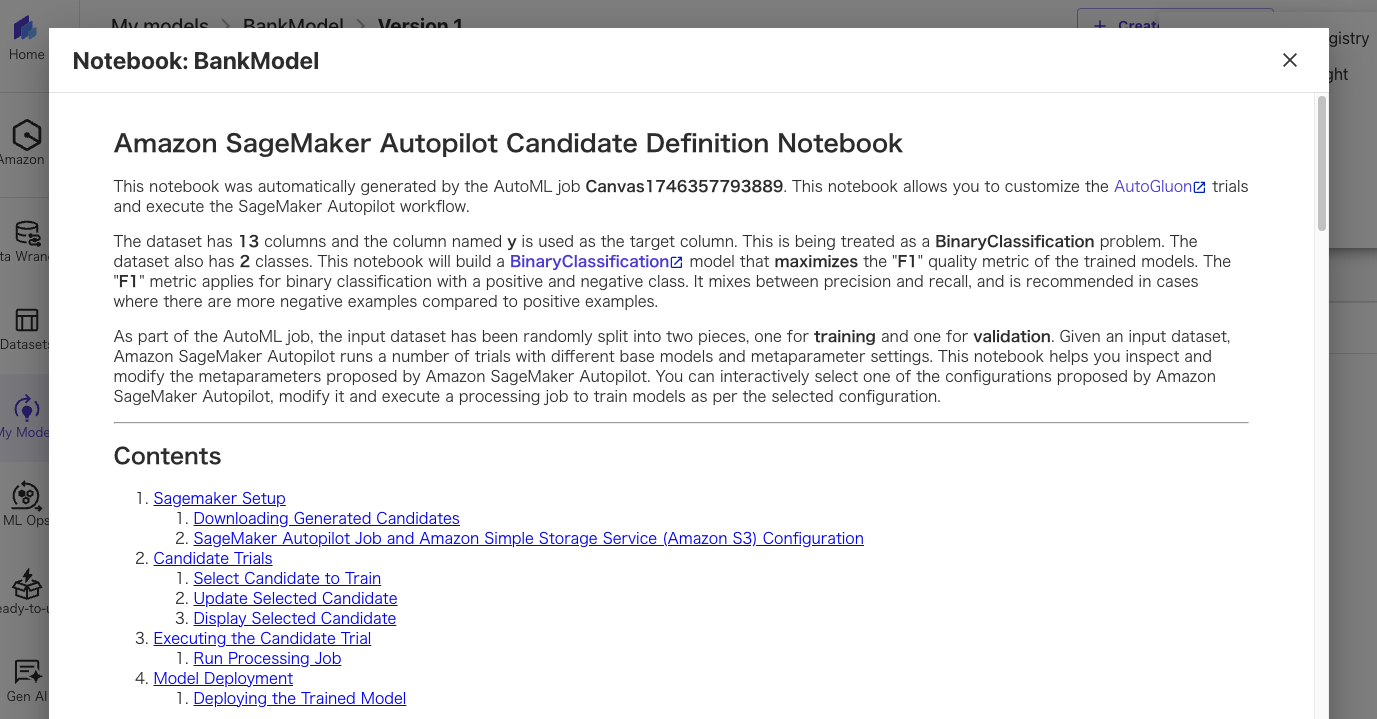
右上のメニューからView Notebookを選択すると、ノートブックが確認できます。
ダウンロードして実行することもできます。
まさにエンドツーエンドの機械学習モデル作成を、ノーコードでできました。
最後までお読みいただきましてありがとうございました!
「AWS認定資格試験テキスト&問題集 AWS認定ソリューションアーキテクト - プロフェッショナル 改訂第2版」という本を書きました。

「AWS認定資格試験テキスト AWS認定クラウドプラクティショナー 改訂第3版」という本を書きました。

「AWS認定資格試験テキスト AWS認定AIプラクティショナー」という本を書きました。

「ポケットスタディ AWS認定 デベロッパーアソシエイト [DVA-C02対応] 」という本を書きました。

「要点整理から攻略するAWS認定ソリューションアーキテクト-アソシエイト」という本を書きました。

「AWSではじめるLinux入門ガイド」という本を書きました。

開発ベンダー5年、ユーザ企業システム部門通算9年、ITインストラクター5年目でプロトタイプビルダーもやりだしたSoftware Engineerです。
質問はコメントかSNSなどからお気軽にどうぞ。
出来る限りなるべく答えます。
このブログの内容/発言の一切は個人の見解であり、所属する組織とは関係ありません。
このブログは経験したことなどの共有を目的としており、手順や結果などを保証するものではありません。
ご参考にされる際は、読者様自身のご判断にてご対応をお願いいたします。
また、勉強会やイベントのレポートは自分が気になったことをメモしたり、聞いて思ったことを書いていますので、登壇者の意見や発表内容ではありません。
関連記事
-

-
Rocket.ChatのOutGoingWebhookからのAPI GatewayからのDynamoDB
少し前に、Rocket.ChatからOut Going Webhookを設定して …
-
-
ある意味マネジメントコンソールで生成された署名付きURL
マネジメントコンソールにS3オブジェクトの[開く]というボタンがいつのまにか出来 …
-
-
Amazon Aurora Serverless のログをCloudWatch Logsに出力する
WordPress W3 Total Cache のDatabaseCacheを …
-
-
Elastic BeanstalkでflaskアプリケーションデプロイのチュートリアルをCloud9で
Elastic Beanstalk への flask アプリケーションのデプロイ …
-
-
AWS Service Catalogポートフォリオを他のアカウントと共有する
AWS Service Catalogチュートリアルで作成したポートフォリオの他 …
-
-
CloudWatch LogsをIPv6アドレスを使用して送信する
このブログの構成からパブリックIPv4を減らすように設計変更しています。 もとも …
-
-
RDSのスナップショットをS3へエクスポートが日本語マネジメントコンソールでもできるようになってました
RDSスナップショットをS3にエクスポートする新機能を試そうかと思ったのときは、 …
-
-
RocketChatの匿名登録時のtoo many requestsエラー対応
匿名ユーザー登録時のtoo many requestsエラー RocketCha …
-
-
CloudFormationで起動テンプレートのバージョン更新をした際にAuto ScalingのEC2インスタンスを置き換える
やりたいこと タイトルのとおり、起動テンプレートのバージョン変更(AMIの置換) …
-
-
EKS「現在の IAM プリンシパルは、このクラスター上の Kubernetes オブジェクトにアクセスできません」
マネジメントコンソールでクラスターのオブジェクトを見ようと、リソースの名前空間や …