
AWS Glueチュートリアル
2021/09/15

AWS Glueのマネジメントコンソールの左ペインの一番下にチュートリアルがあります。
やりましょう。
バージニア北部でやりました。
目次
クローラの追加
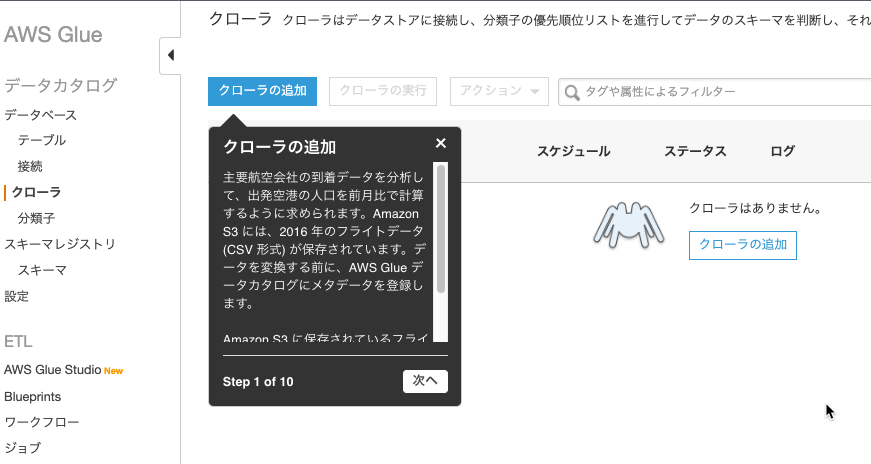
チュートリアルの[クローラの追加]を選択すると、[クローラの追加]画面に遷移してメッセージがナビゲートしてくれます。
[次へ]を押下したら、[クローラの追加]ボタンが押下されて画面遷移しました。
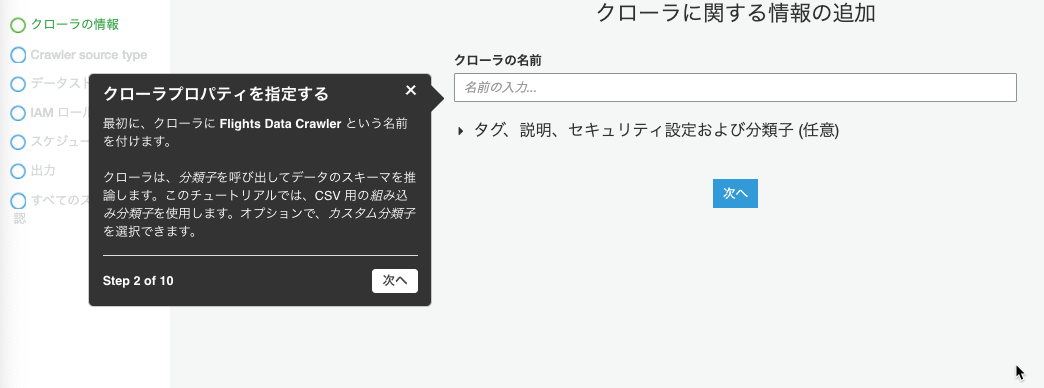
クローラの名前に”Flights Data Crawler”と入力して[次へ]を押下しました。
次はクローラのソースタイプの指定で、Data storesかExisting catalog tablesから選べます。
チュートリアルではData storesを選択しました。
Repeat crawls of S3 data storesでは、Crawl all foldersかCrawl new folders onlyから選択できます。
Crawl all foldersを選択しました。
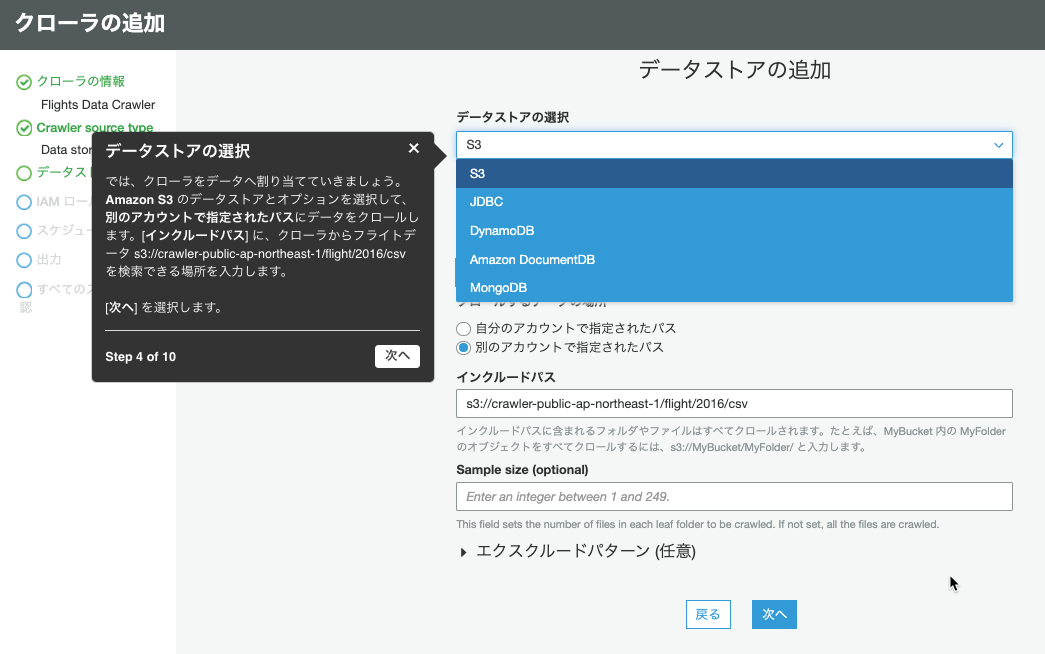
データストアの追加では、S3、JDBC、DynamoDB、DocumentDB、MongoDBから選択できます。
S3を選択しました。
インクルードパスに、チュートリアル用のパス
s3://crawler-public-us-east-1/flight/2016/csv
を入力しました(画面とは違います)。
[次へ]を押下しました。
次の「別のデータストアの追加」画面では、1つのクローラーで複数のデータストアをクロールすることができるようです。
チュートリアルでは[いいえ]を選択しました。
次の「IAMロールの選択」では、新規のIAMロール作成を選択して、DefaultRoleと入力しました。
これでAWSGlueServiceRole-DefaultRoleというIAMロールが作成されます。

スケジュール設定で、周期的なスケジュールが設定できます。
オンデマンドにしました。
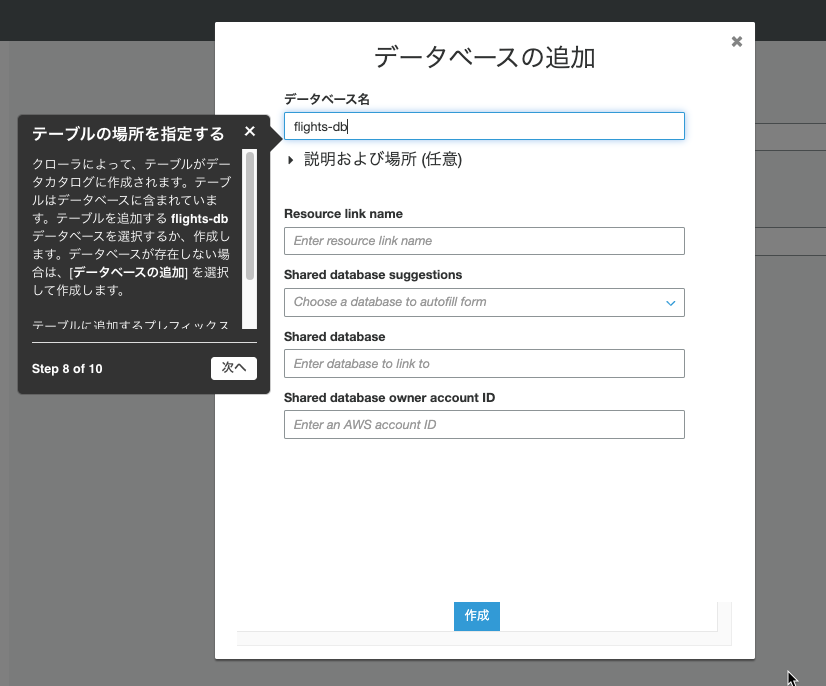
「クローラーの出力設定」では、flights-dbデータベースを追加しました。
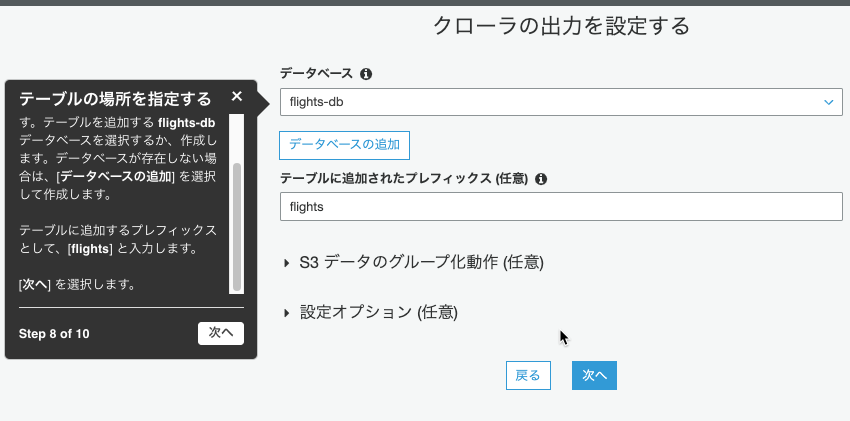
プレフィックスにflightsと入力しました。
これで完了です。
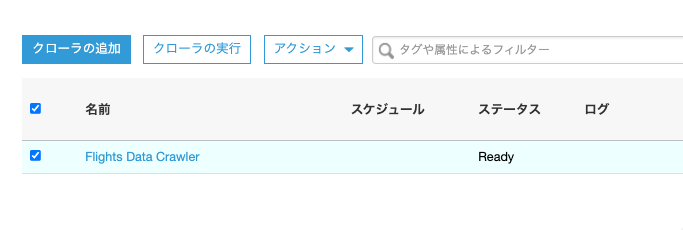
Flights Data Crawlerを選択して、[クローラの実行]を押下しました。
テーブルの確認
flightscsvテーブルが作成されています。
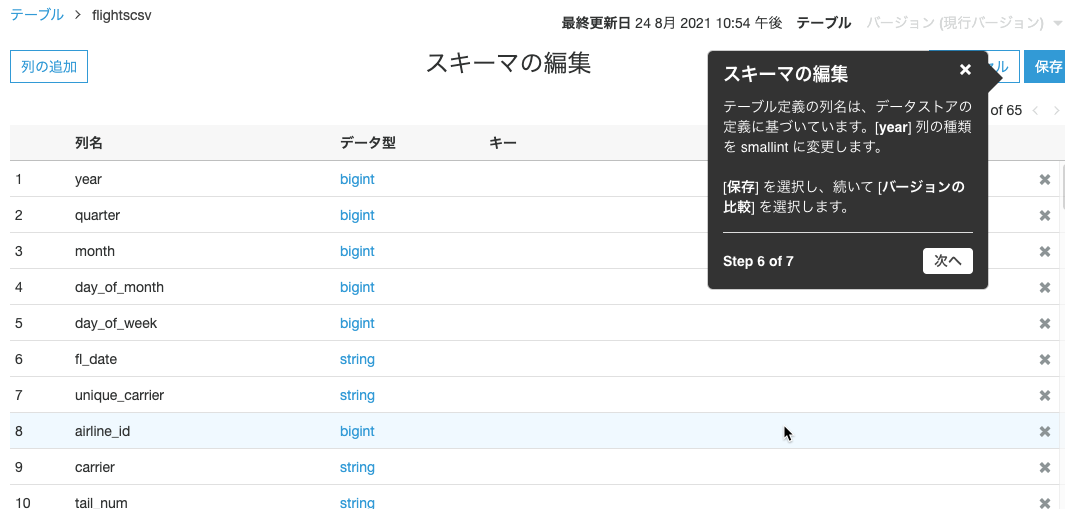
S3のCSVを読み取ってクローラが自動でスキーマを作成したのですね。
他に詳細情報の確認などを行いました。
ジョブの追加
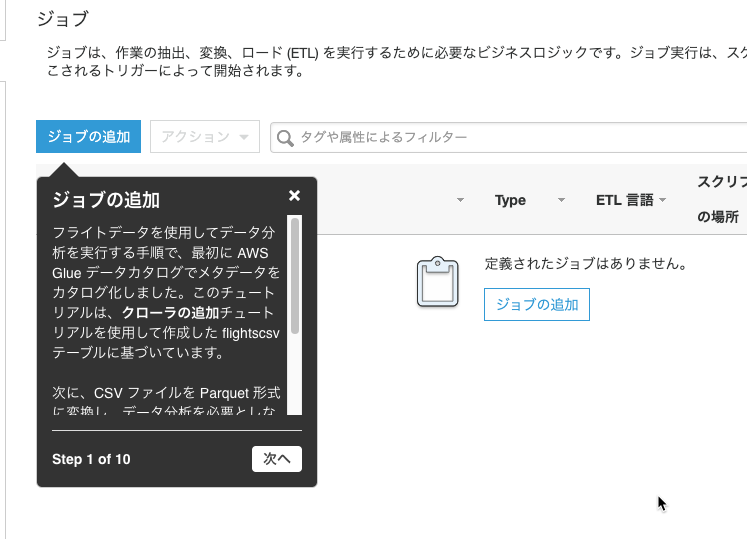
次に[ジョブの追加]を選択しました。
元のS3バケットのCSVをParquetに変換してくれるそうです。
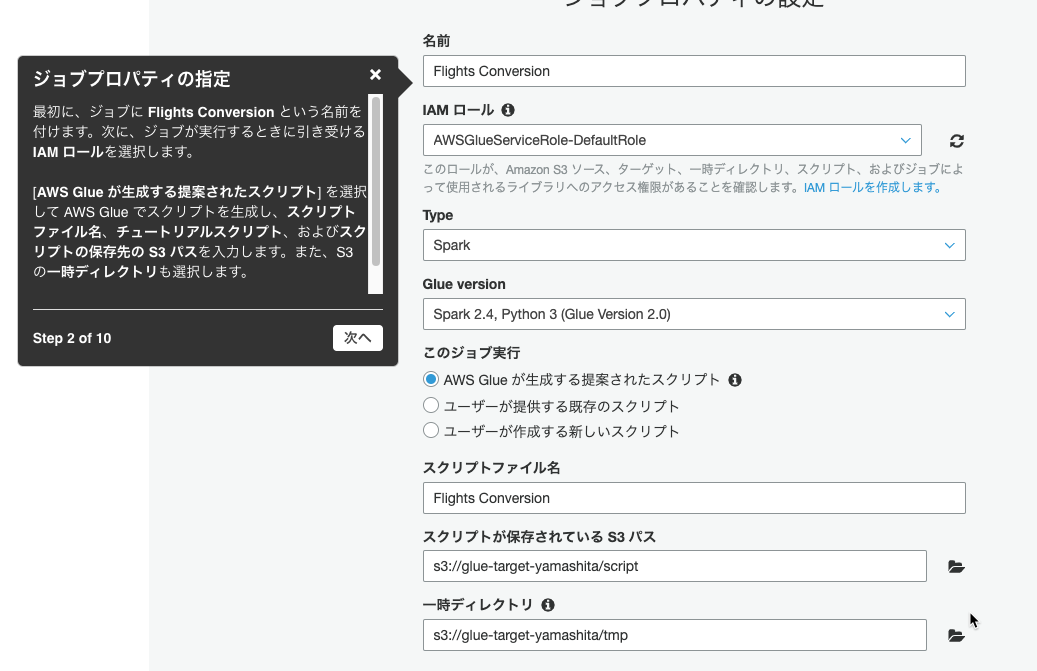
ジョブの名前、IAMロール、生成されるスクリプトの保存先などを指定しました。
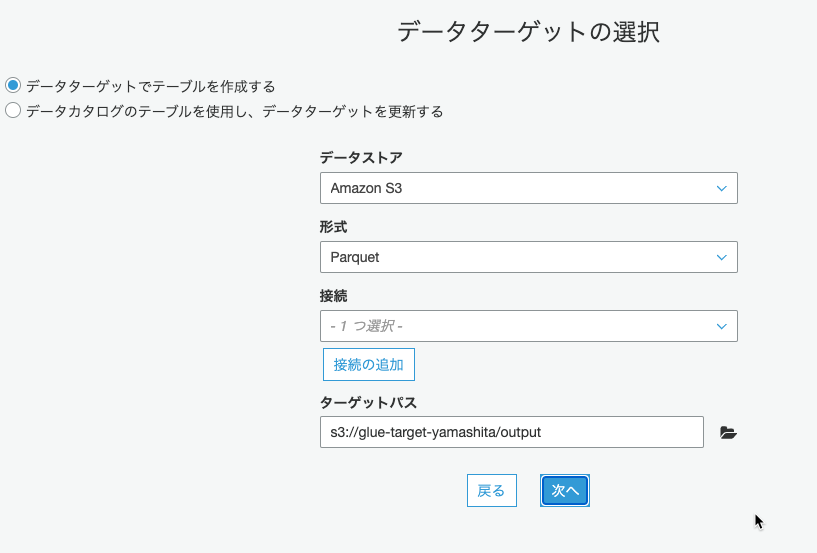
Parquet形式を指定して、出力先にS3バケットを指定しました。
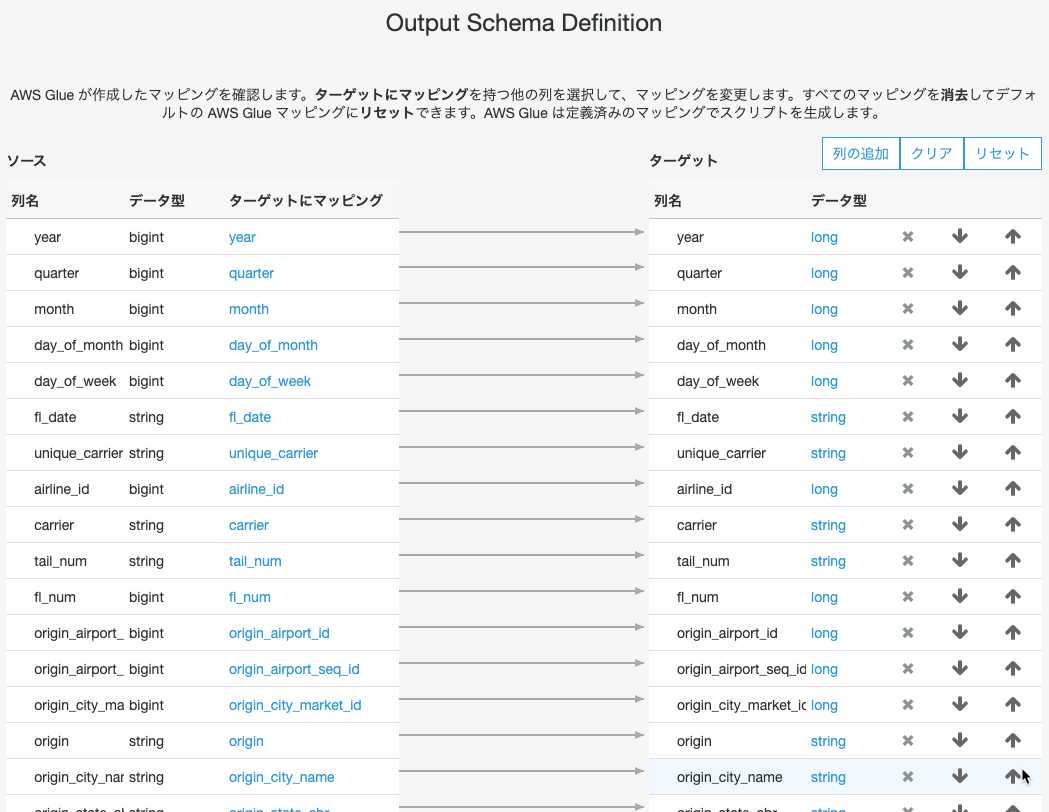
マッピングが表示されました。
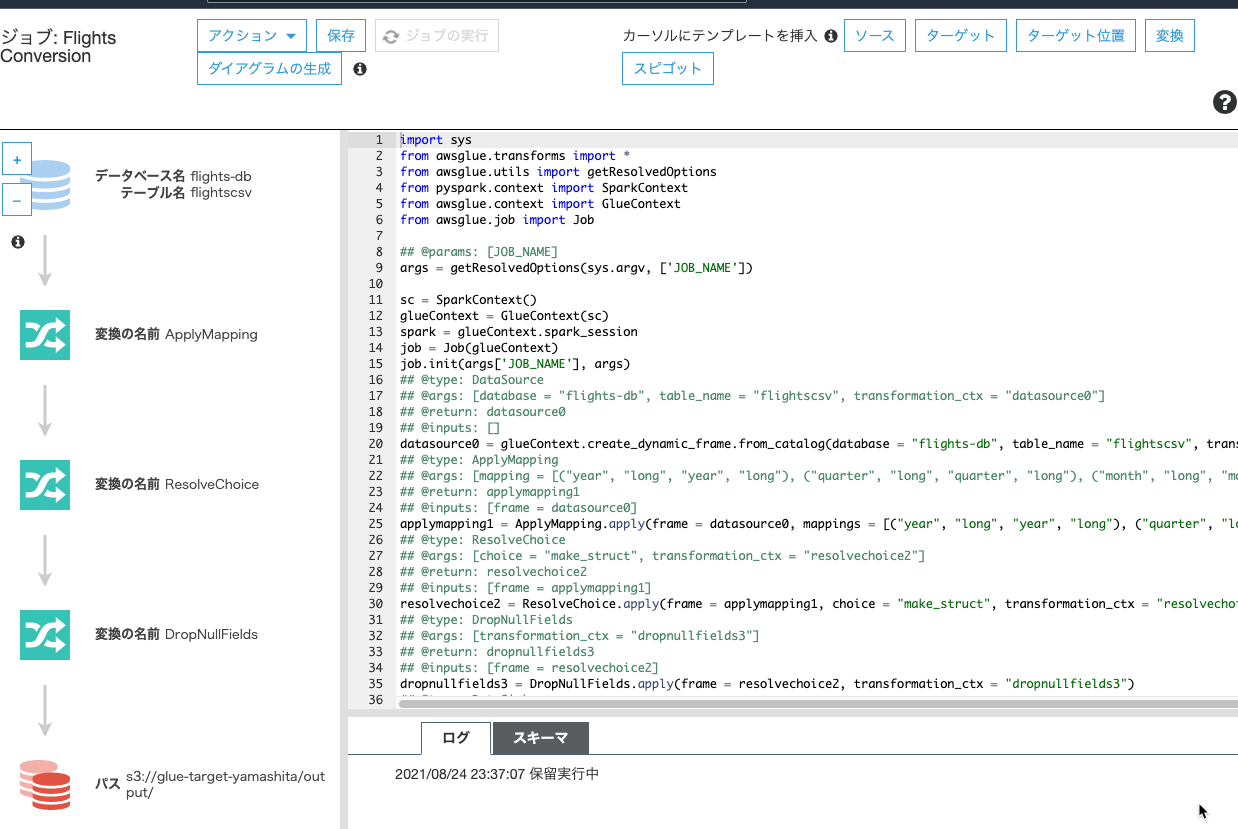
スクリプトエディタになりましたので、[ジョブの実行]を押下しました。
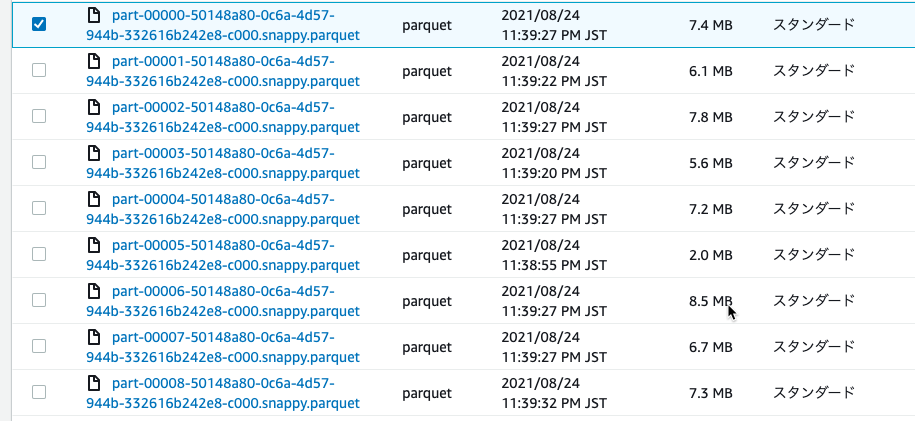
指定したS3バケットにParquetファイルが生成されていました。

オブジェクトアクションのS3 Selectで確認したら、Parquetで認識されてました。
CSV出力で確認してみます。
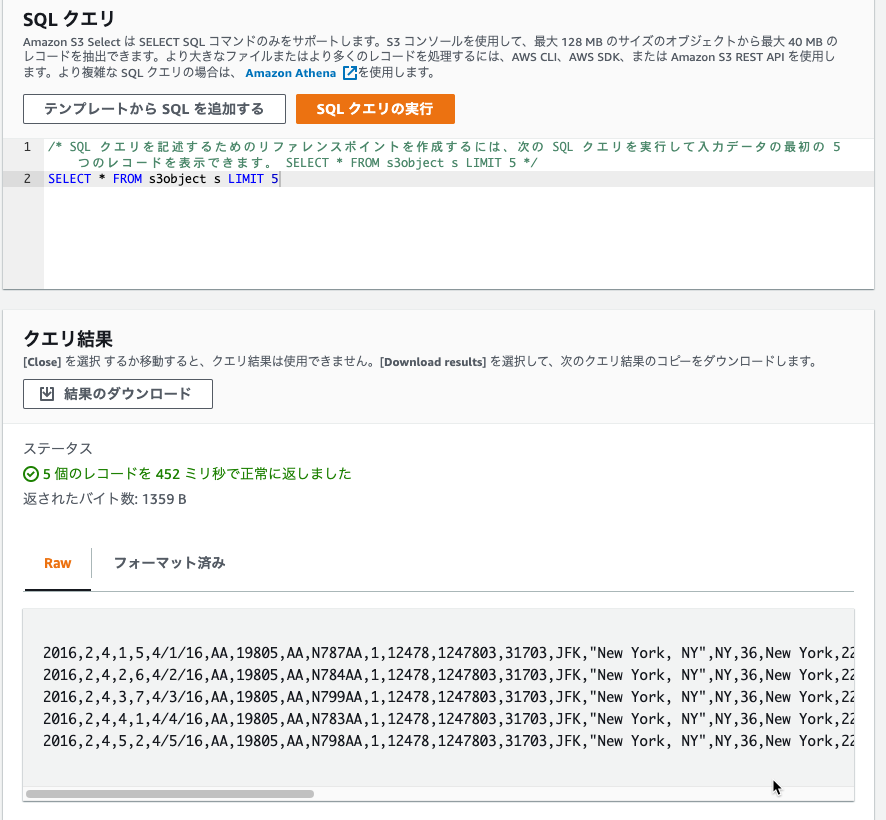
ちゃんとデータを確認できました。
最後までお読みいただきましてありがとうございました!
「AWS認定資格試験テキスト&問題集 AWS認定ソリューションアーキテクト - プロフェッショナル 改訂第2版」という本を書きました。

「AWS認定資格試験テキスト AWS認定クラウドプラクティショナー 改訂第3版」という本を書きました。

「ポケットスタディ AWS認定 デベロッパーアソシエイト [DVA-C02対応] 」という本を書きました。

「要点整理から攻略するAWS認定ソリューションアーキテクト-アソシエイト」という本を書きました。

「AWSではじめるLinux入門ガイド」という本を書きました。

開発ベンダー5年、ユーザ企業システム部門通算9年、ITインストラクター5年目でプロトタイプビルダーもやりだしたSoftware Engineerです。
質問はコメントかSNSなどからお気軽にどうぞ。
出来る限りなるべく答えます。
このブログの内容/発言の一切は個人の見解であり、所属する組織とは関係ありません。
このブログは経験したことなどの共有を目的としており、手順や結果などを保証するものではありません。
ご参考にされる際は、読者様自身のご判断にてご対応をお願いいたします。
また、勉強会やイベントのレポートは自分が気になったことをメモしたり、聞いて思ったことを書いていますので、登壇者の意見や発表内容ではありません。
ad
ad
関連記事
-

-
WordPressをAmazon CloudFrontで配信してついでにACM(AWS Certificate Manager)を使って常時SSL化する
当サイトの500と502の発生状況がドイヒーであるとの苦情をいただきまして、Am …
-
-
AWS Systems Manager Run CommandでEC2 Linuxのユーザーとカレントディレクトリを確認
AWS Systems Manager Run CommandからEC2 Lin …
-
-
Route 53サブドメインホストゾーンを作成したら、元のホストゾーンにNSレコードを作成する自動化
ハンズオン環境でRoute 53のホストゾーンを触ってほしい際に、サブドメインを …
-
-
AWS Expert Online at JAWS-UG首都圏エリアに参加して「Amazon EC2 スポットインスタンス再入門」を聞いてきた
AWS Expert Onlineという勉強会がありまして、AWS ソリューショ …
-
-
EC2 Ubuntu DesktopにRDP
Ubuntu Desktopが必要になりましたので、こちらのAWS EC2でデス …
-
-
AWS WAF Web ACLとルールをv1(Classic)からv2に自動移行しました
新しいものは、課題が解決されていたり、機能追加されたりするのでいいものです。 長 …
-
-
webフォームからの問い合わせをRedmineに自動登録して対応状況を管理する(API Gateway + Lambda)
先日、検証目的で作成したRedmineの冗長化の一機能として、webフォームから …
-
-
Amazon LinuxのNginx+RDS MySQLにレンタルWebサーバーからWordPressを移設する(失敗、手戻りそのまま記載版)
勉強のためブログサイトを長らくお世話になったロリポップさんから、AWSに移設する …
-
-
スポットインスタンスの削減額情報を見ました
なんだこれ?と思って、検索してみたら、2018年11月からあったのですね。 Am …
-
-
RDSの拡張モニタリングを有効にしました
RDS for MySQLです。 変更メニューで、[拡張モニタリングを有効にする …