
「最小限のコードで機械学習のためのトレーニングデータを準備する」チュートリアル記録
2025/05/04
Amazon SageMaker Data Wranglerのチュートリアルをやりました。
目次
使用するデータと環境
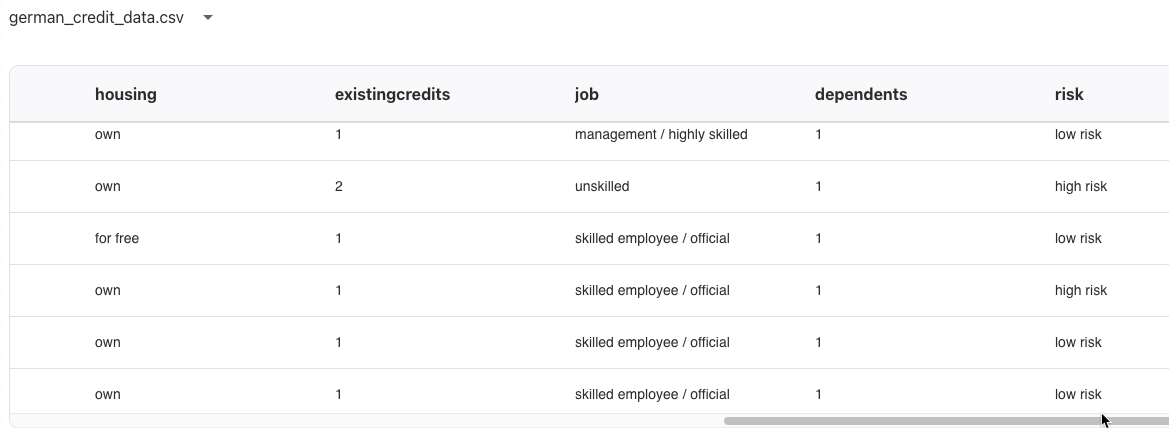
信用リスクモデルをトレーニングするためのデータを使用します。
人口統計、雇用の詳細、財務データなど、個人の情報を含む1,000のレコードから構成されていて、高、低とラベル付けされた信用リスクフィールドが含まれています。
リージョンはバージニア北部で、SageMakerドメインはクイックセットアップで作成しました。
SageMaker Studioを起動して、[Data]-[Data Wrangler]をクリックしました。
[Run in Canvas]をクリックして、Runningになったら[Open in Canvas]をクリックしました。
チュートリアルの手順がSageMaker Studio Classicのように思うので、メニューを探しながら進めました。
Data WranglerがCanvasに統合されて、一部の機能として使用できるのがわかるメニュー構成になっています。
[Import and prepare]-[Tabular]を選択しました。
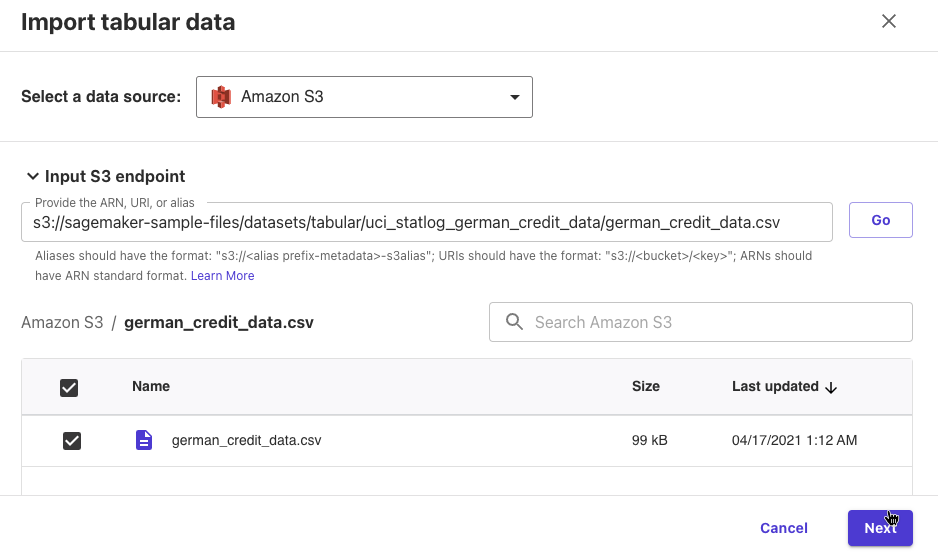
データソースにS3を選択して、S3 endpointに次のURIを入力して[Go]をクリックしました。
s3://sagemaker-sample-files/datasets/tabular/uci_statlog_german_credit_data/german_credit_data.csv
german_credit_data.csvが表示されたので選択して、[Next]をクリックしました。
データのプレビューが表示されたので、[Import]をクリックしました。
データのプロファイリング
右のData typesのGet data insightsをクリックしました。
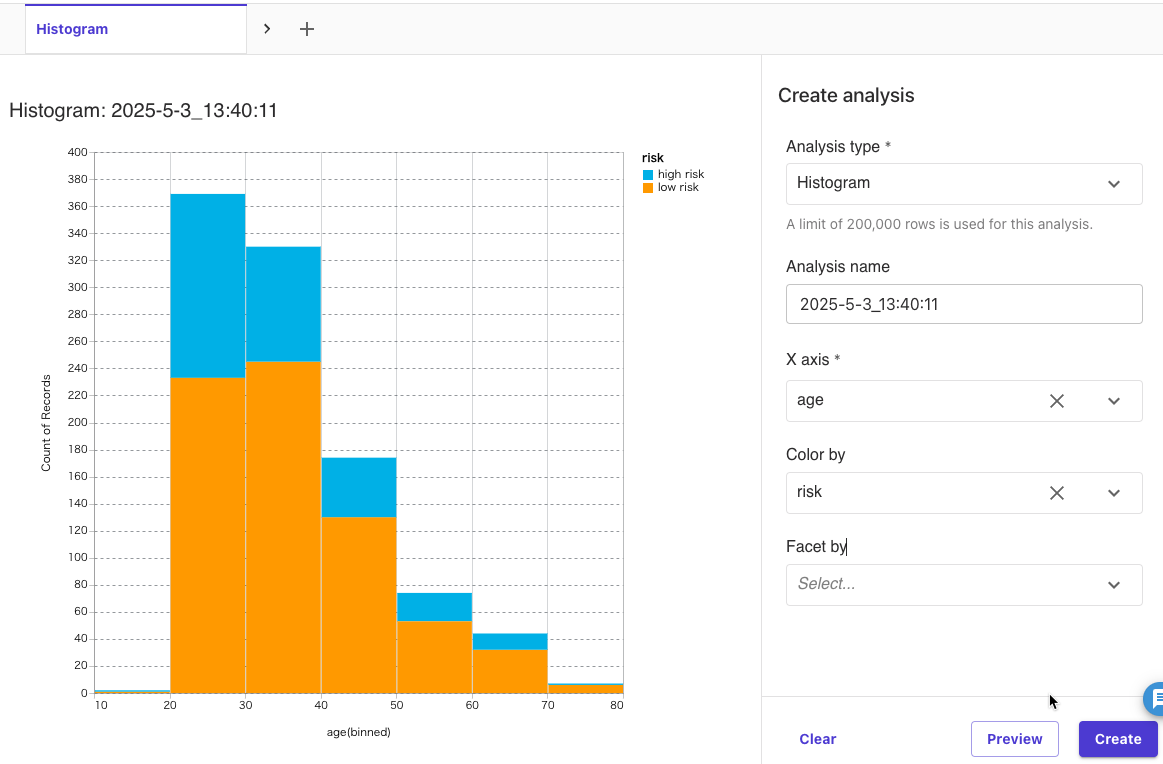
Analysis type: Histogram
X axis: age
Color by: risk
を選択して、[Preview]をクリックしました。
年代ごとに低リスクと高リスクの割合や、データ全体の年齢分布がわかりました。
[Create]をクリックしました。
画面上部にある + から次の分析を新規作成します。
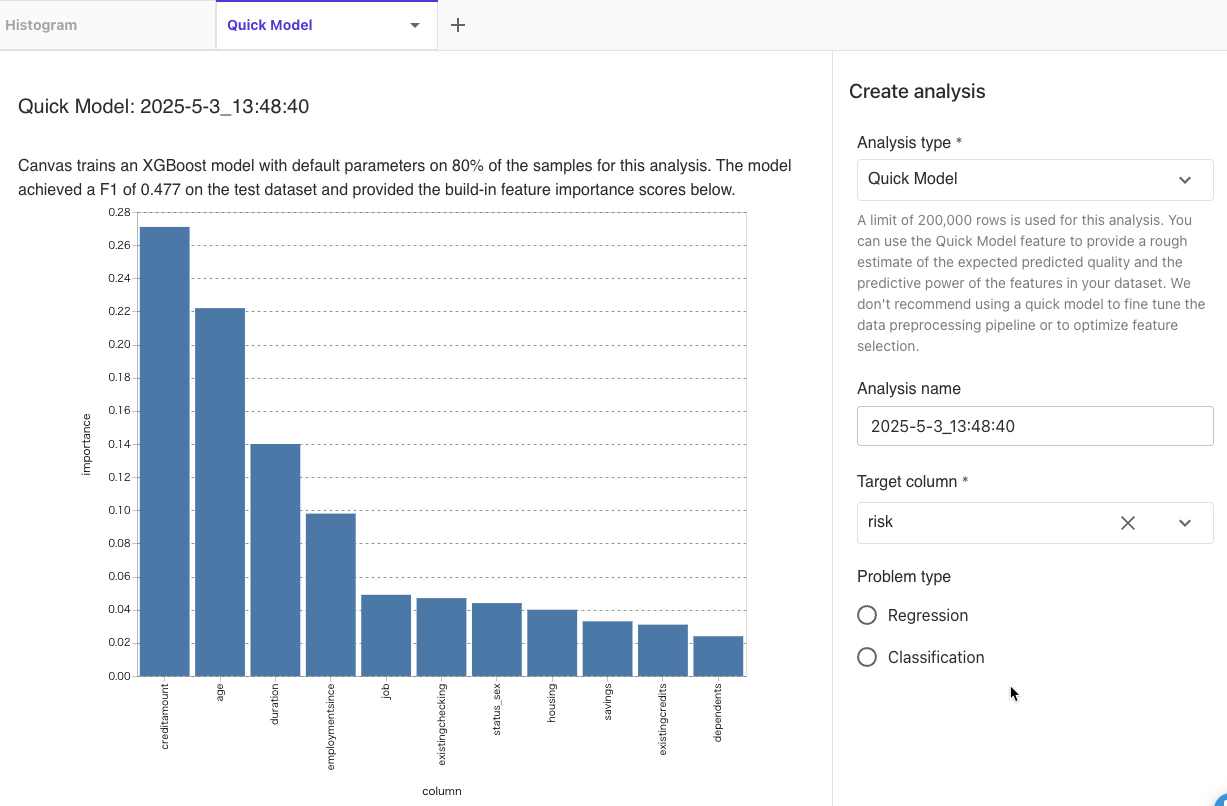
Analysis type: Quick Model
Target Column: risk
を選択して、[Preview]をクリックしました。
リスクが高いか低いかの分類問題なので、F1スコアで評価されて0.477でした。
特徴量はcreditamountが最も重要な属性で、次にageが重要なことがわかりました。
[Create]をクリックしました。

データフローに戻ると、作成したHistogramとQuick Modelが追加されています。
変換を追加する
データフローで、Add transformをクリックしました。
[Add transofrm]-[Search and edit]をクリックしました。
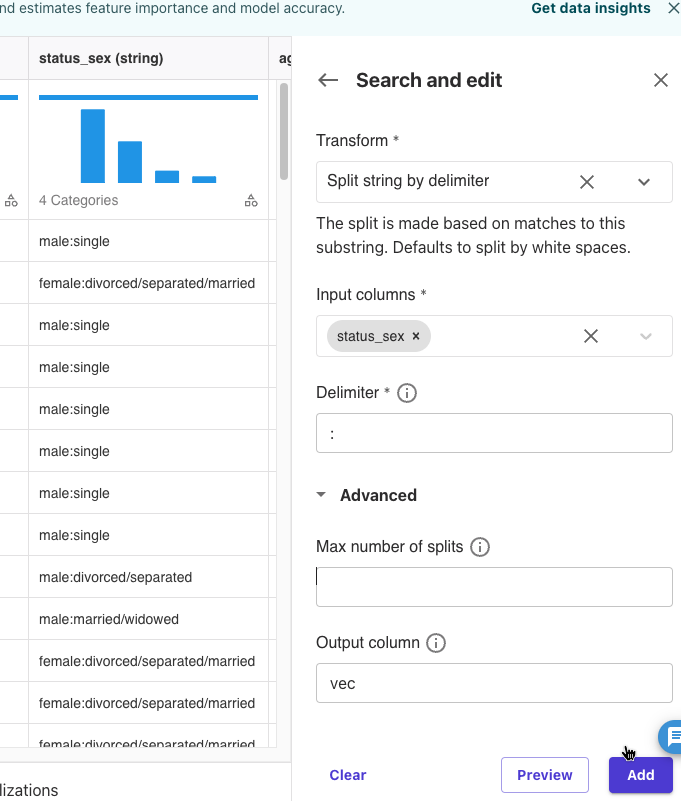
Transform: Spit string by delimiter
Input Columns: status_sex
Delimiter: :
Output column: vec
上記を設定して、[Preview]をクリックしました。
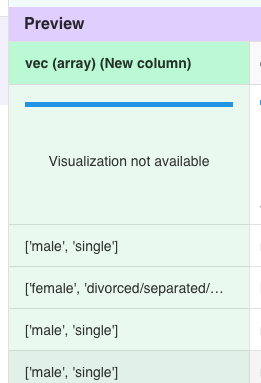
コロンで区切られた値を配列にしたvec列ができました。
[Add]をクリックしました。
[Add transofrm]-[Manage vectors]をクリックしました。
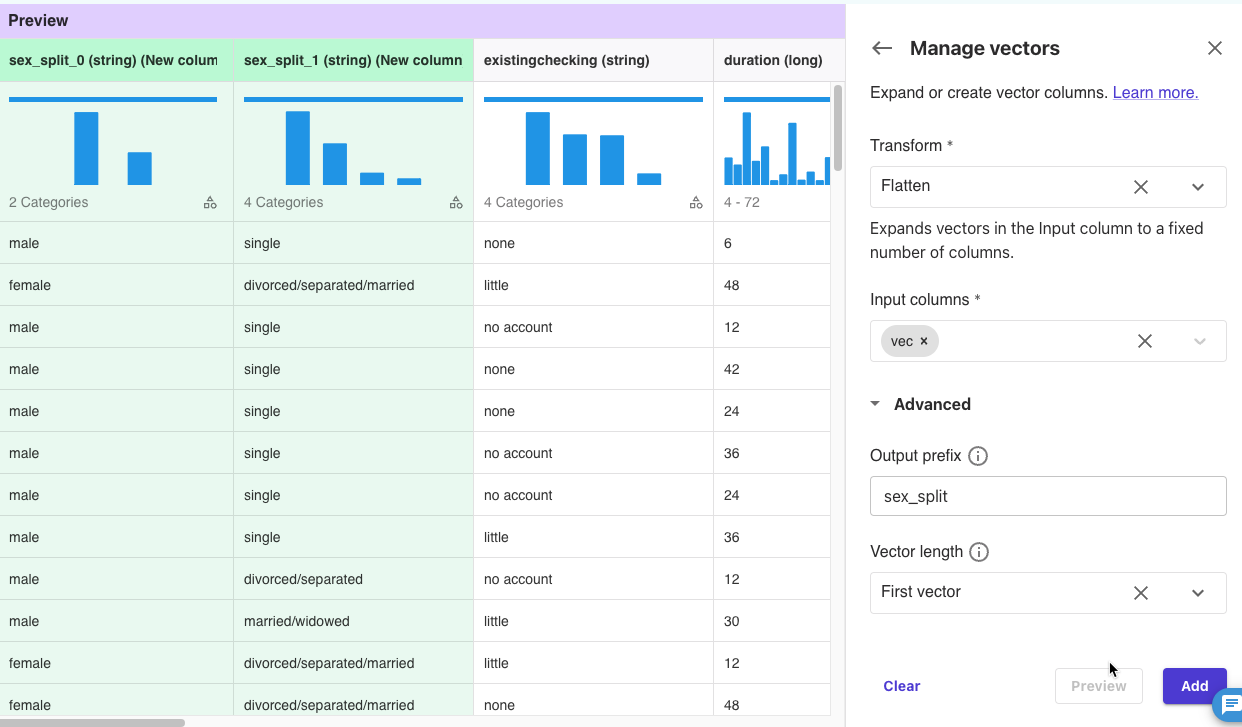
Transform: Flatten
Input columns: vec
Output prefix: sex_split
上記を設定して、[Preview]をクリックしました。
sex_split_0とsex_split_1列ができました。
[Add]をクリックしました。
[Add transofrm]-[Manage columns]をクリックしました。
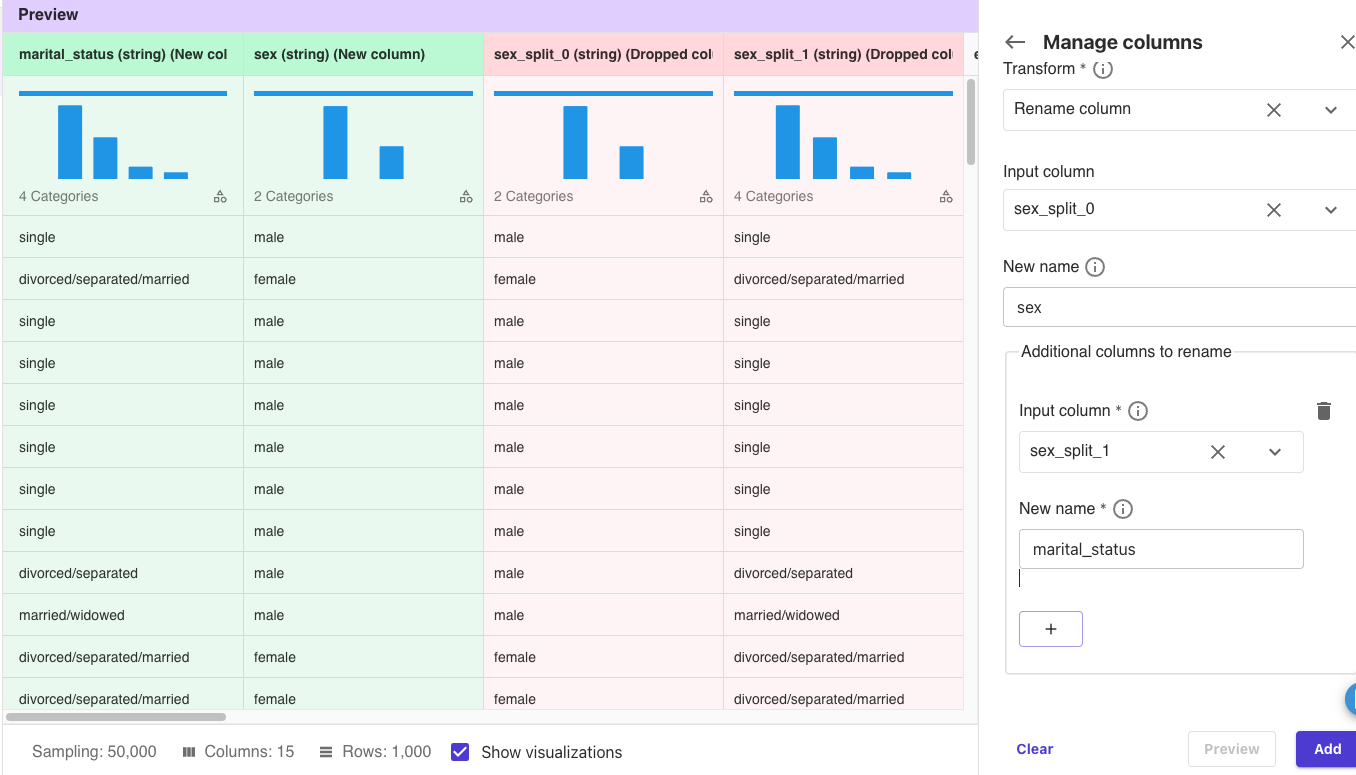
Transform: Rename column
Input column: sex_split_0
New name: sex
Input column: sex_split_1
New name: marital_status
上記を設定して、[Preview]をクリックしました。
列名を変更しました。
[Add]をクリックしました。
カテゴリカルエンコーディングの追加
カテゴリカルエンコーディングは、文字列データタイプのカテゴリを数値ラベルに変換します。
[Add transofrm]-[Encode Categorical]をクリックしました。
transform: Ordinal encode
Input columns: risk
Output column: target
上記を設定して、[Preview]をクリックしました。
row riskが0、high riskが1になりました。
[Add]をクリックしました。
[Add transofrm]-[Custom transform]をクリックしました。
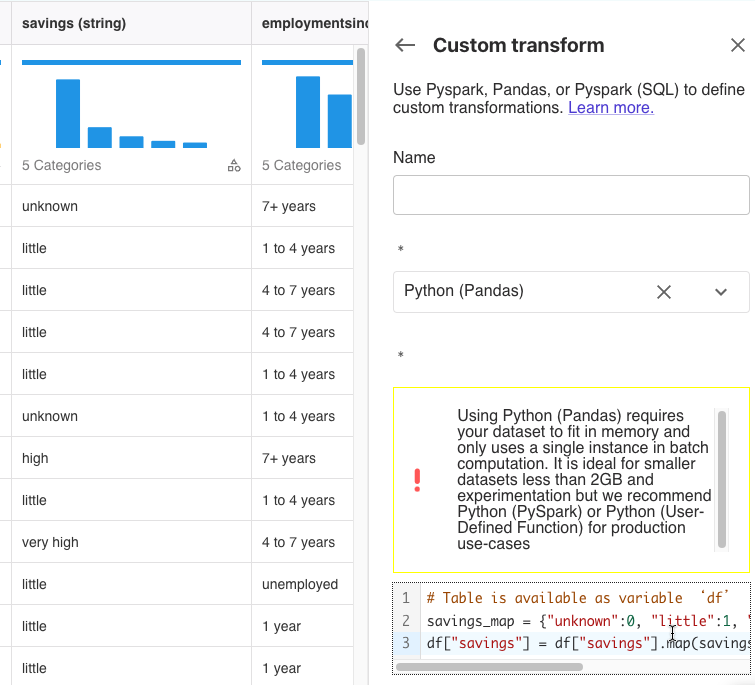
savings列には、unknown、little、high、very highなどの値があります。
Python(Pandas)を選択して次のスクリプトを貼り付けて[Preview]をクリックしました。
|
1 2 3 4 |
# Table is available as variable ‘df’ savings_map = {"unknown":0, "little":1, "moderate":2, "high":3, "very high":4} df["savings"] = df["savings"].map(savings_map).fillna(df["savings"]) |
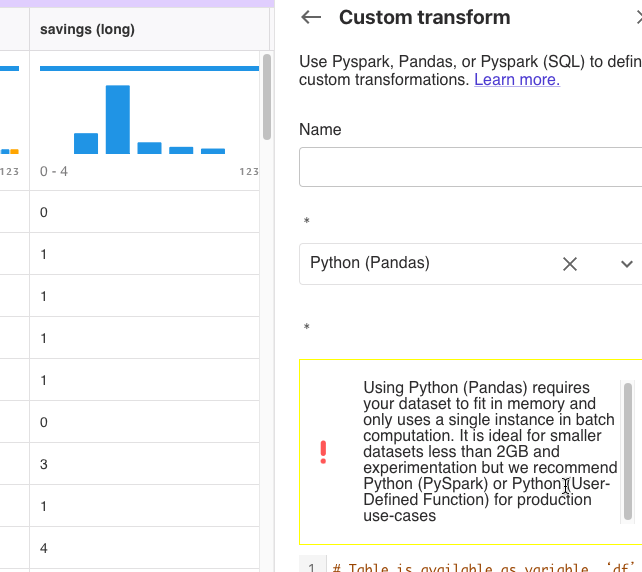
savings列がスクリプトの通りに数値に変換されました。
[Add]をクリックしました。
[Add transofrm]-[Encode categorical]をクリックしました。
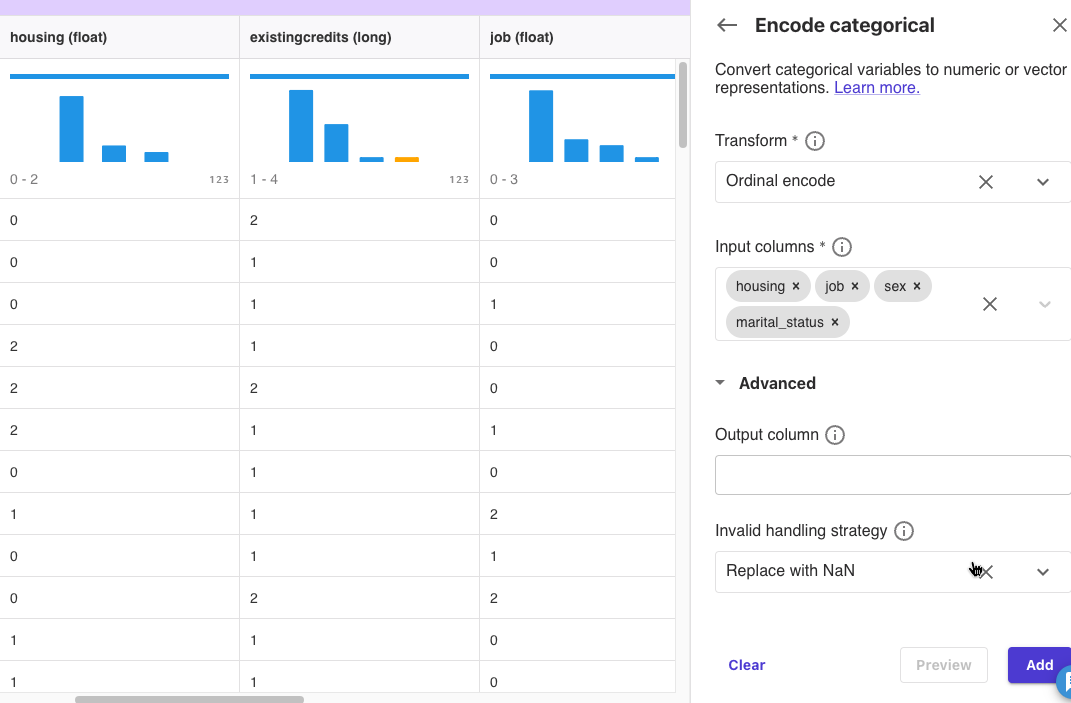
Input Columnsにhousing, job, sex, marital_statusを選択して[Preview]をクリックしました。
指定した列が数値に変換されました。
[Add]をクリックしました。
範囲の大きいデータにスケーラーを適用する
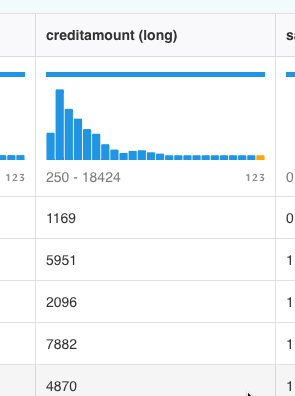
creditamountは現在250から18424の値範囲となっているため、機械学習モデルに不均衡な影響を与える可能性があります。
スケーラーを適用して適切な範囲にします。
[Add transofrm]-[Process numeric]をクリックしました。
Input columnsにcreditamountを設定して、[Preview]をクリックしました。
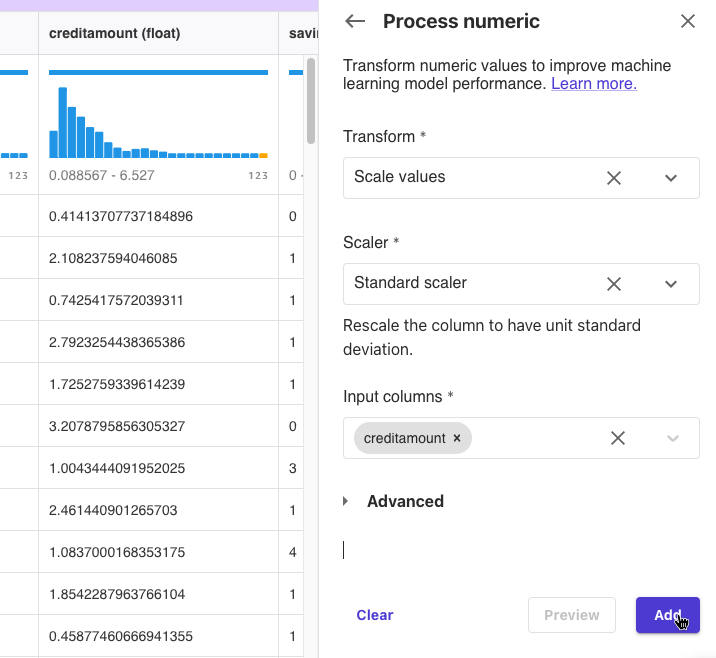
creditamountの値が変換されて、0.088567から6.527の範囲になりました。
[Add]をクリックしました。
変換前の列と不要列の削除
[Add transofrm]-[Manage Columns]をクリックしました。
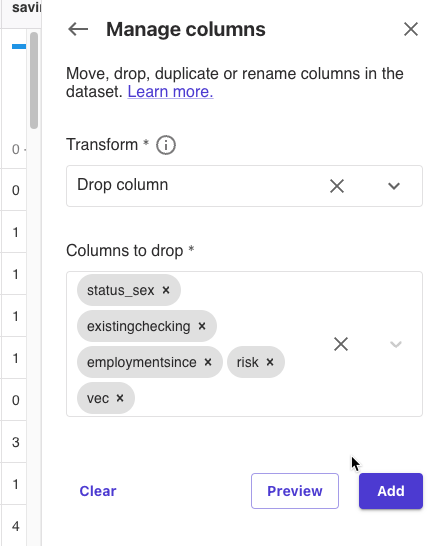
[Preview]をクリックして[Add]をクリックしました。
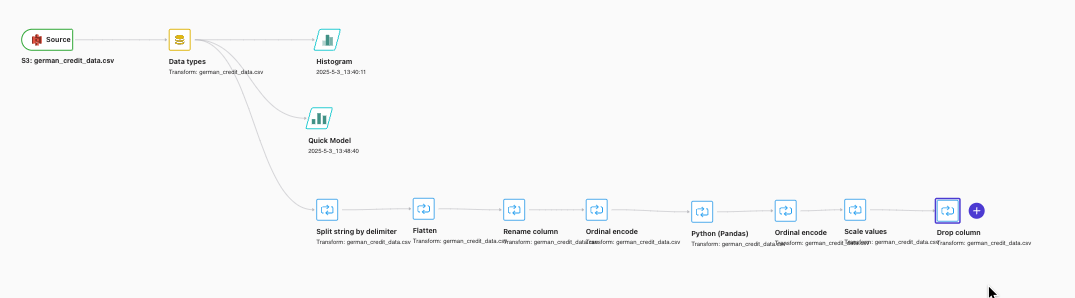
データフローに戻ると一連の変換処理が追加されています。
Amazon SageMaker Clarifyでデータのバイアスチェック
高リスク、低リスクと推論される際に性別が影響しない公平性があるかをチェックします。
Get data insightsを選択しました。
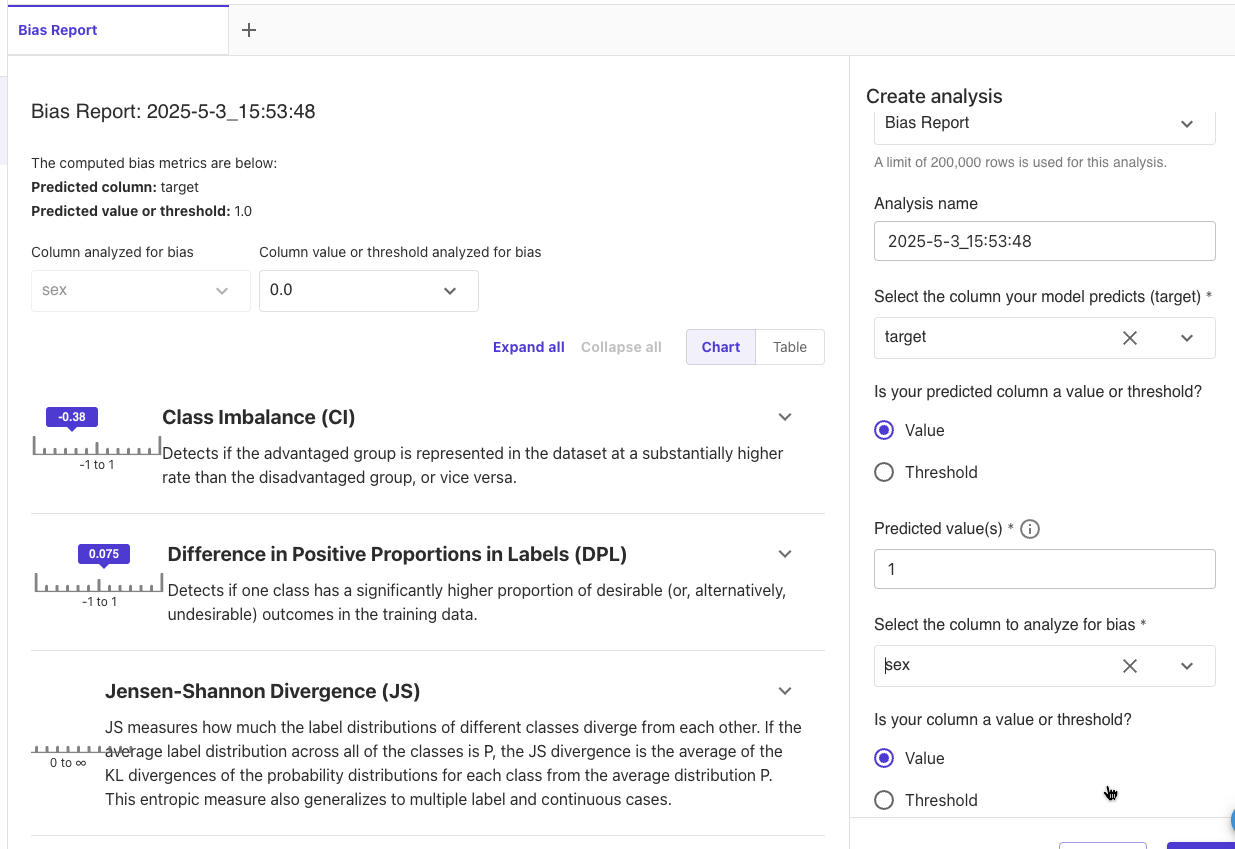
Analysis type: Bias Report
Select the column your model predicts: target
Predicted value: 1
Select the column to analyze for bias: sex
[Preview]をクリックしました。
分析が実行されて結果が表示されました。
CIは-0.38なので、女性のほうが低リスクになりやすい傾向にあり、不公平が存在する可能性があります。
DPLは0.075なので比較的小さいですが、完全に公平ではなく高リスクとなる割合が男性と女性で7.5%異なります。
ひとまず[Create]をクリックして先に進みます。
エクスポート
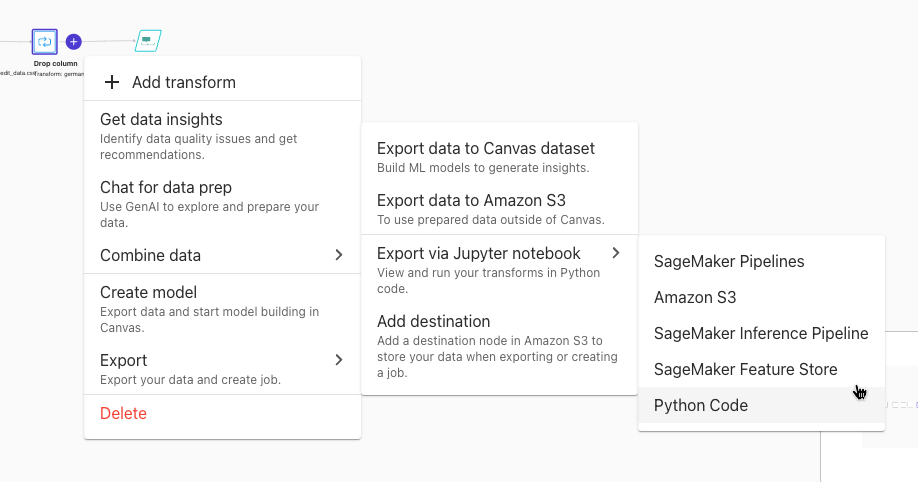
Export via Jupyter notebookを選択して、S3を選択しました。
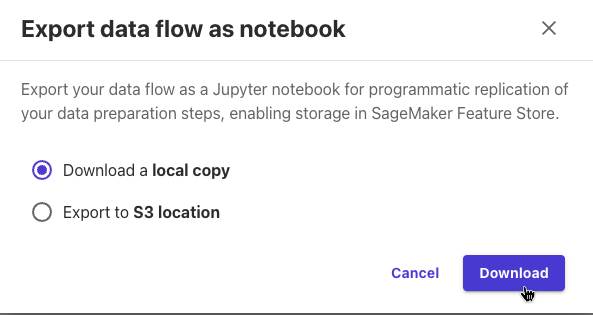
保存先をローカルにしました。
2つのファイルが保存されました。
- New data flow 2025-5-3 1/22/39 PM.flow
- New data flow 2025-5-3 1/22/39 PM.ipynb
ノートブックとデータフローの定義ファイルでした。
Data Wranglerはデータ変換を行うためのGUIデザイナーとして、ノートブックファイルのエクスポートもできるのですね。
最後までお読みいただきましてありがとうございました!
「AWS認定資格試験テキスト&問題集 AWS認定ソリューションアーキテクト - プロフェッショナル 改訂第2版」という本を書きました。

「AWS認定資格試験テキスト AWS認定クラウドプラクティショナー 改訂第3版」という本を書きました。

「AWS認定資格試験テキスト AWS認定AIプラクティショナー」という本を書きました。

「AWS教科書 AWS認定デベロッパーアソシエイト テキスト&問題集 」という本を書きました。

「要点整理から攻略するAWS認定ソリューションアーキテクト-アソシエイト」という本を書きました。

「AWSではじめるLinux入門ガイド」という本を書きました。

開発ベンダー5年、ユーザ企業システム部門通算9年、ITインストラクター5年目でプロトタイプビルダーもやりだしたSoftware Engineerです。
質問はコメントかSNSなどからお気軽にどうぞ。
出来る限りなるべく答えます。
このブログの内容/発言の一切は個人の見解であり、所属する組織とは関係ありません。
このブログは経験したことなどの共有を目的としており、手順や結果などを保証するものではありません。
ご参考にされる際は、読者様自身のご判断にてご対応をお願いいたします。
また、勉強会やイベントのレポートは自分が気になったことをメモしたり、聞いて思ったことを書いていますので、登壇者の意見や発表内容ではありません。
関連記事
-

-
CodeBuildで執筆原稿データをまとめた
今書いている原稿に対して編集者さんから、「できればで構わないのですが、章ごとにマ …
-
-
VPN接続先のADで管理されているドメインにEC2 Windowsインスタンスから参加する
オンプレミスに見立てたオハイオリージョンにVyOSインスタンスを起動して東京リー …
-
-
Amazon ECS Workshop for AWS Summit Online
INTRODUCTION TO AMAZON ECSに手順や必要なリンクがありま …
-
-
ALBにWAFを関連付けて特定のヘッダー以外はブロックする
おかげさまで、ブログのアクセスも増えてきて、t3.nano EC2インスタンス単 …
-
-
試そうとしてたらSavings Plans買っちゃいました
Savings Plansの購入画面を確認していました。 画面遷移も確認しようと …
-
-
WordPressの年ごとのブログ投稿数を調べるSQL
毎年年末に使いそうなのでメモです。 [crayon-6a6ffa17a136d8 …
-
-
AWS Transfer Family S3向けのSFTP対応サーバーをVPCで作成してEIPをアタッチ
EIPの作成 同じリージョンでEIPを作成しておきます。 SFTP対応サーバーの …
-
-
EC2インスタンスWindowsでセッションマネージャーを使う
WindowsのEC2インスタンスでセッションマネージャーを使ってみたことがない …
-
-
GoogleフォームからAPI Gatewayで作成したREST APIにPOSTリクエストする
「API GatewayからLambdaを介さずにSNSトピックへ送信」の続きで …
-
-
GoogleForm,GASからAPI Gateway, Lambdaで入力情報をDynamoDBに格納する
vol.26 AWS認定試験テキスト認定クラウドプラクティショナーのデモ(Dyn …