
Backlogの実績工数をAmazon QuickSightでの可視化 – 仕組み編
Backlogの実績工数をAmazon QuickSightで可視化してわかったことに書きましたように、Backlogの実績工数を作業種別か期日別に集計してAmazon QuickSightで円グラフ、棒グラフで見えるようにしました。
次のような設計です。
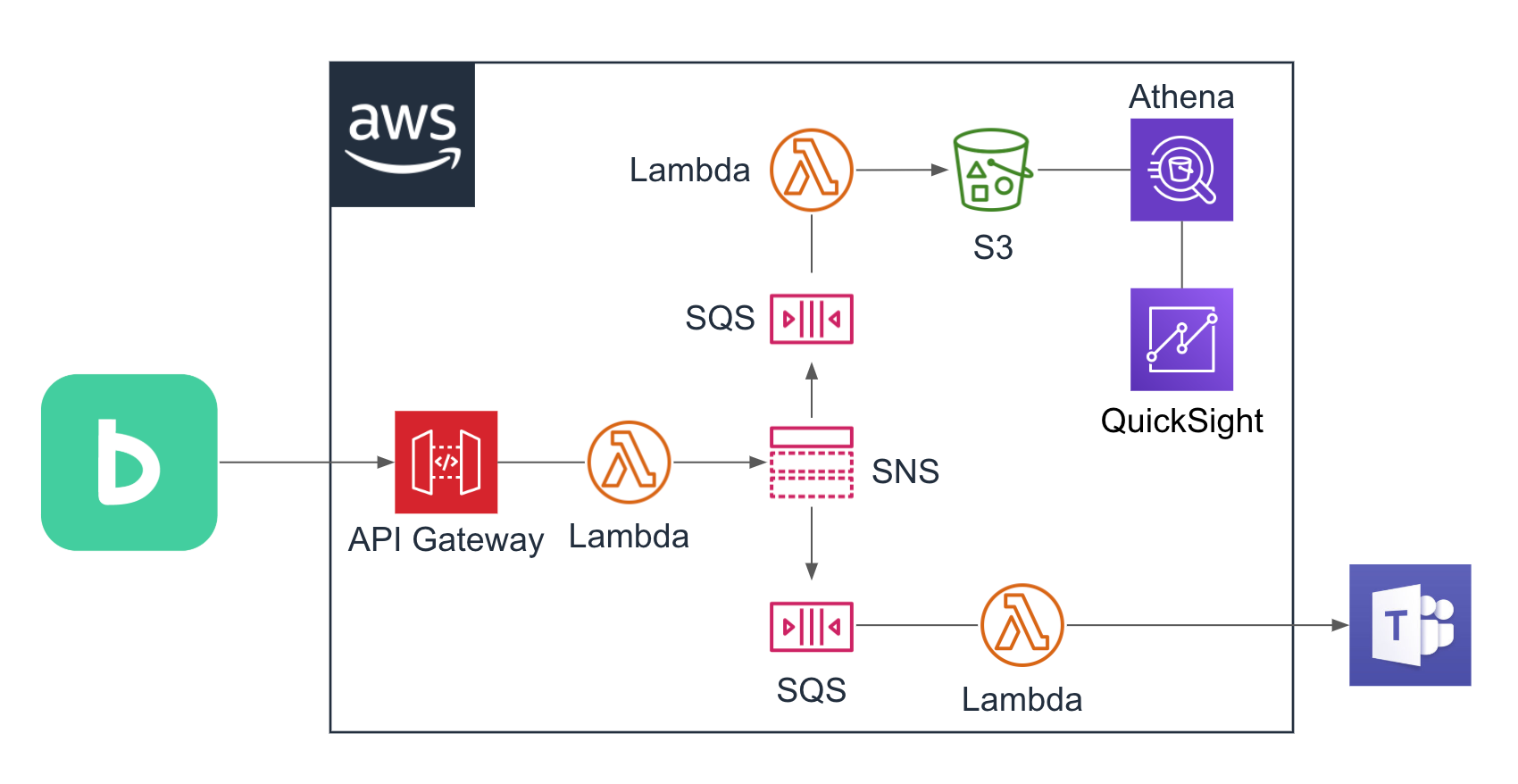
それぞれの設定内容を書き留めておきます。
目次
SQSキューの作成
backlog_s3と、backlog_teamsという2つのSQS標準キューとそれぞれのデッドレターキュー用のキューを作成しました。
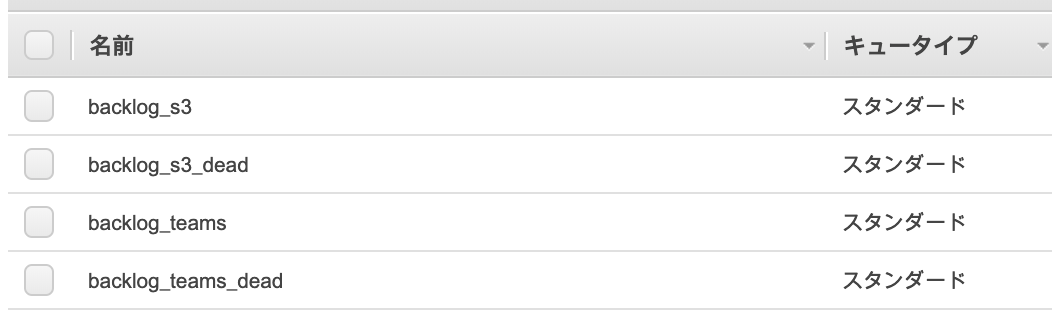
メッセージの保持期間を14日として、再処理ポリシーで最大受信数を10としてデッドレターキューを指定したくらいで他はデフォルトのまま作りました。
可視性タイムアウトも処理としては30秒あれば充分と思うのでデフォルトの30秒のままにしてます。
SNSトピックの作成
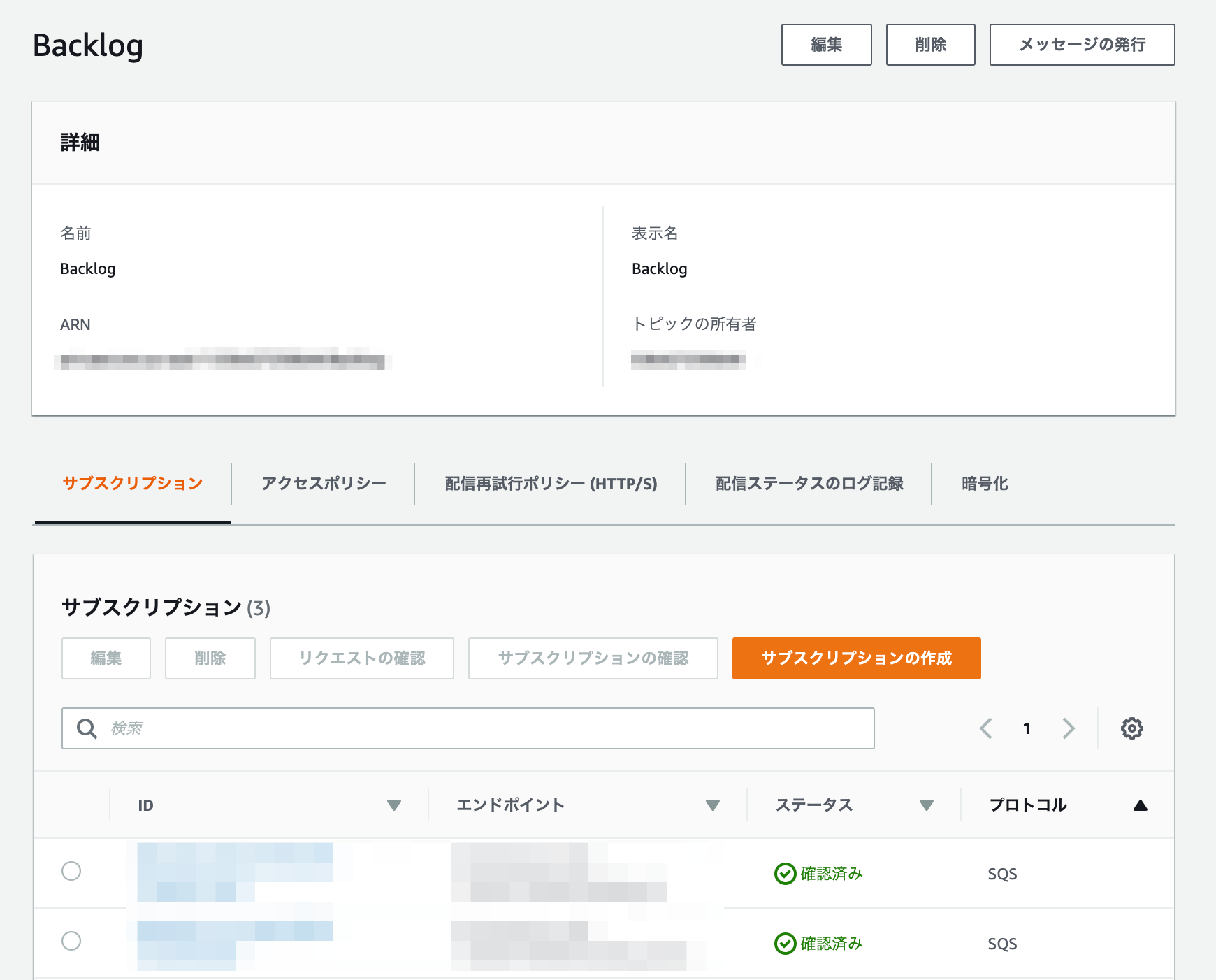
BacklogというSNSトピックを作成して、サブスクライバーにbacklog_s3と、backlog_teamsの2つのSQSキューを指定しました。
Backlogから更新情報をうけとって、SNSトピックへ通知するLambda関数
最初のLambdaはBacklogからWebhookで送信されたデータを受け取って、SNSトピックへメッセージとして送信しています。
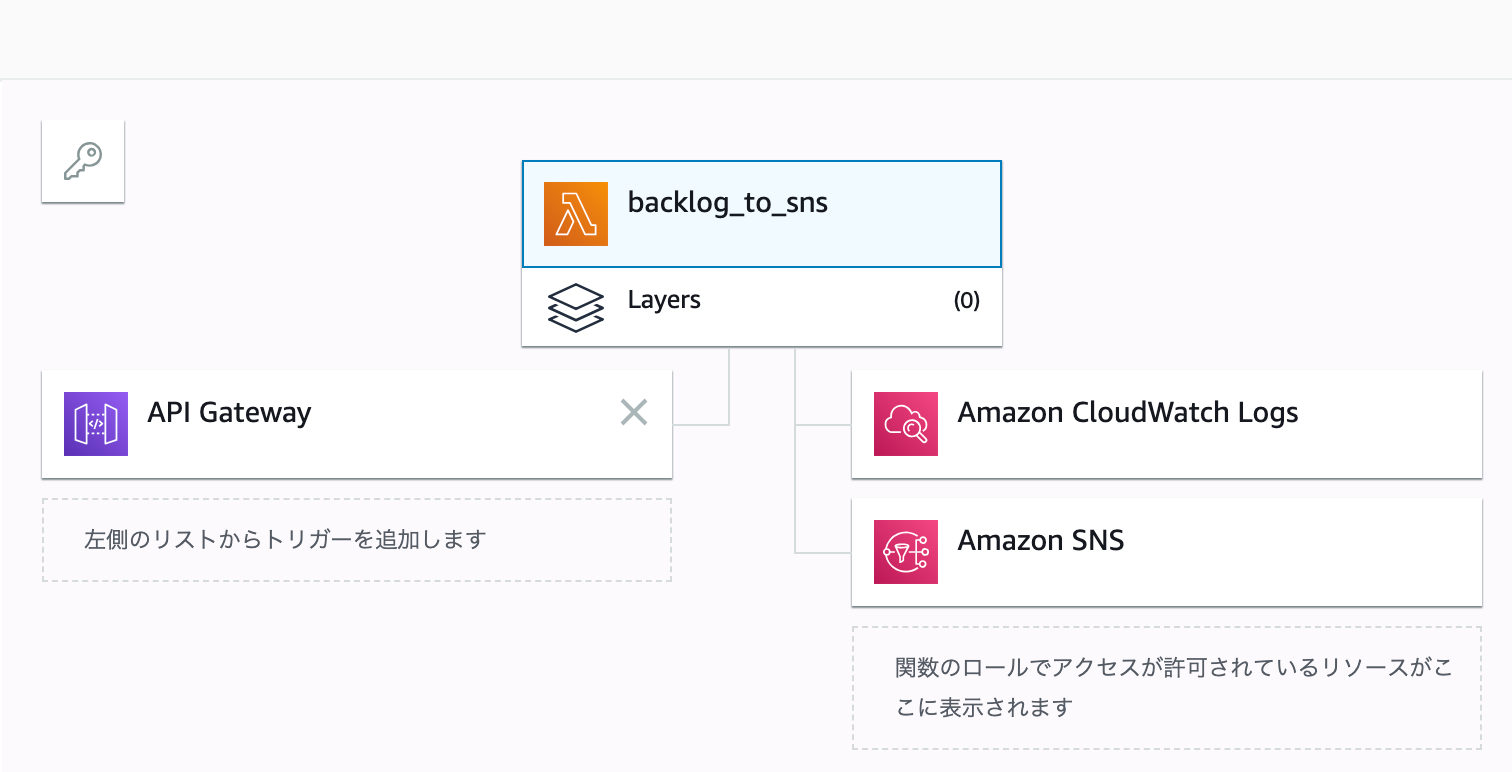
API Gatewayをトリガーにして(これはAPI Gatewayを作るときに設定しました)、SNSとログを書き出すためにCloudWatch Logsへの権限をIAMロールにアタッチするIAMポリシーで定義しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import logging import boto3 import traceback import json logger = logging.getLogger() logger.setLevel(logging.INFO) def lambda_handler(event, context): try: sns = boto3.client('sns') topic_name = 'Backlog' snsTopicArn = [t['TopicArn'] for t in sns.list_topics()['Topics'] if t['TopicArn'].endswith(':' + topic_name)][0] sns.publish( TopicArn=snsTopicArn, Message=json.dumps(event), Subject='backlog' ) except: logger.error(traceback.format_exc()) |
Backlogでチケットが更新されたときに、このLambdaに更新データを渡したいので、BacklogのWebhookを受けて、Lambdaにイベントデータを渡すAPI Gatewayを設定します。
BacklogのWebhookを受けるAPI Gateway

POSTにLambdaを指定してデプロイしただけです。
デプロイしてできたステージのURL呼び出しのAPIエンドポイントをBacklogのWebhookに設定します。
Backlog側の設定
次にBacklogでWebhookの設定をします。
プロジェクト管理者権限が必要です。
[プロジェクト設定] – [インテグレーション]でWebhookを設定して、作成済のAPI GatewayエンドポイントをWebHook URLに指定します。
Webhook名と説明は任意で、見て分かるものにしておきます。
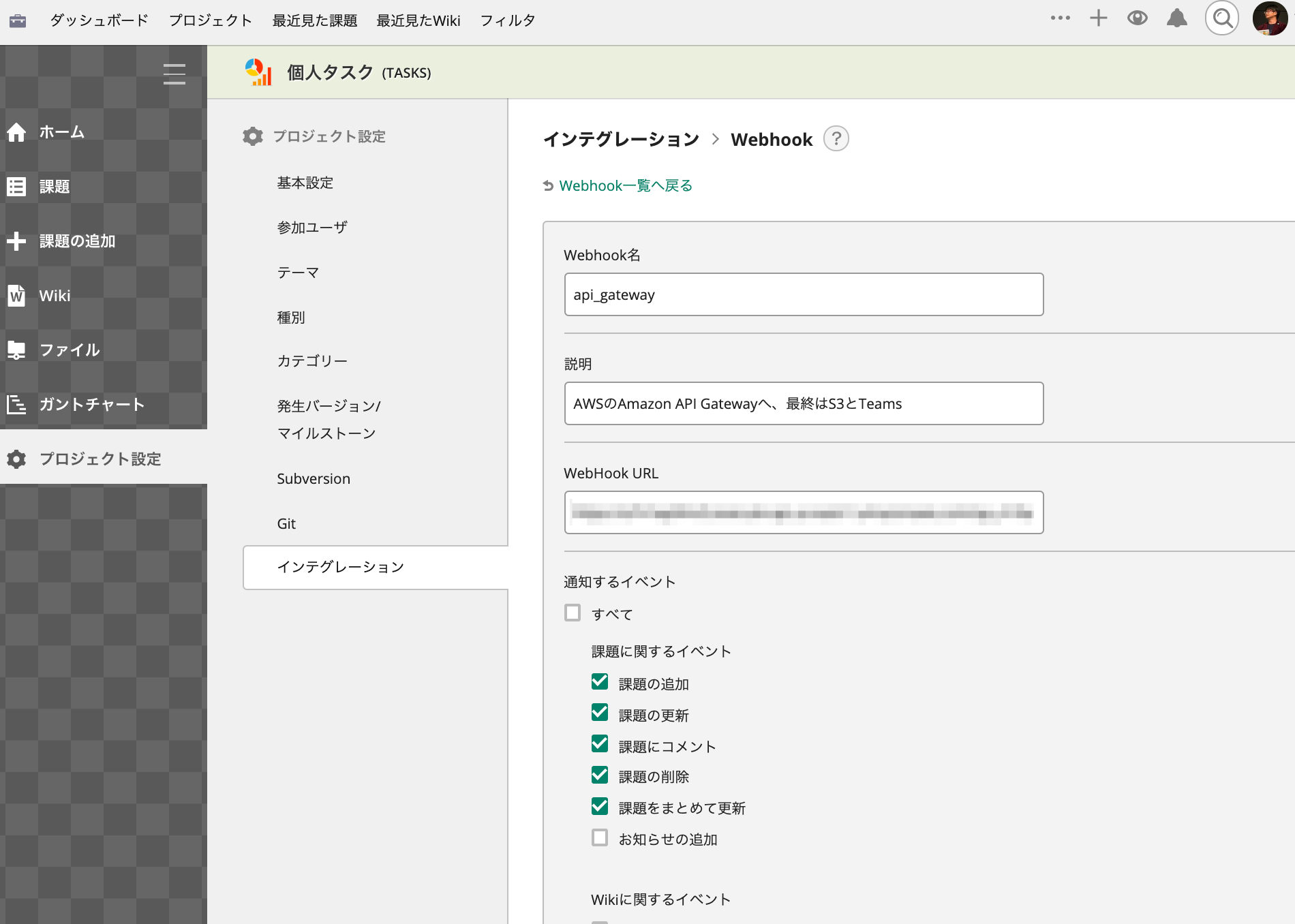
これで、Backlogでチケットが追加/更新されるごとに、SQSキューまでメッセージが届きます。
SQSのメッセージを受信してS3にデータを格納するLambda
コードはこちらです。
Lambdaで環境変数はS3のバケット名を設定しています。
Backlogのデータから必要なデータだけを取得してS3にjsonで書き出してます。
そのままでも良かったのですがデータ容量を抑えようというのと、扱いやすくするためです。
|
1 2 3 4 5 |
object_key = '{projectKey}-{key_id}.json'.format( projectKey=projectKey, key_id=key_id ) |
S3のオブジェクトキーは、BacklogのプロジェクトIDと課題チケットのキーにしてます。
こうすることで更新時に新しいデータを作るのではなく、S3側も更新してます。
いつ誰が何を更新したかという履歴は、今回はAWS側では要らないとしてます。
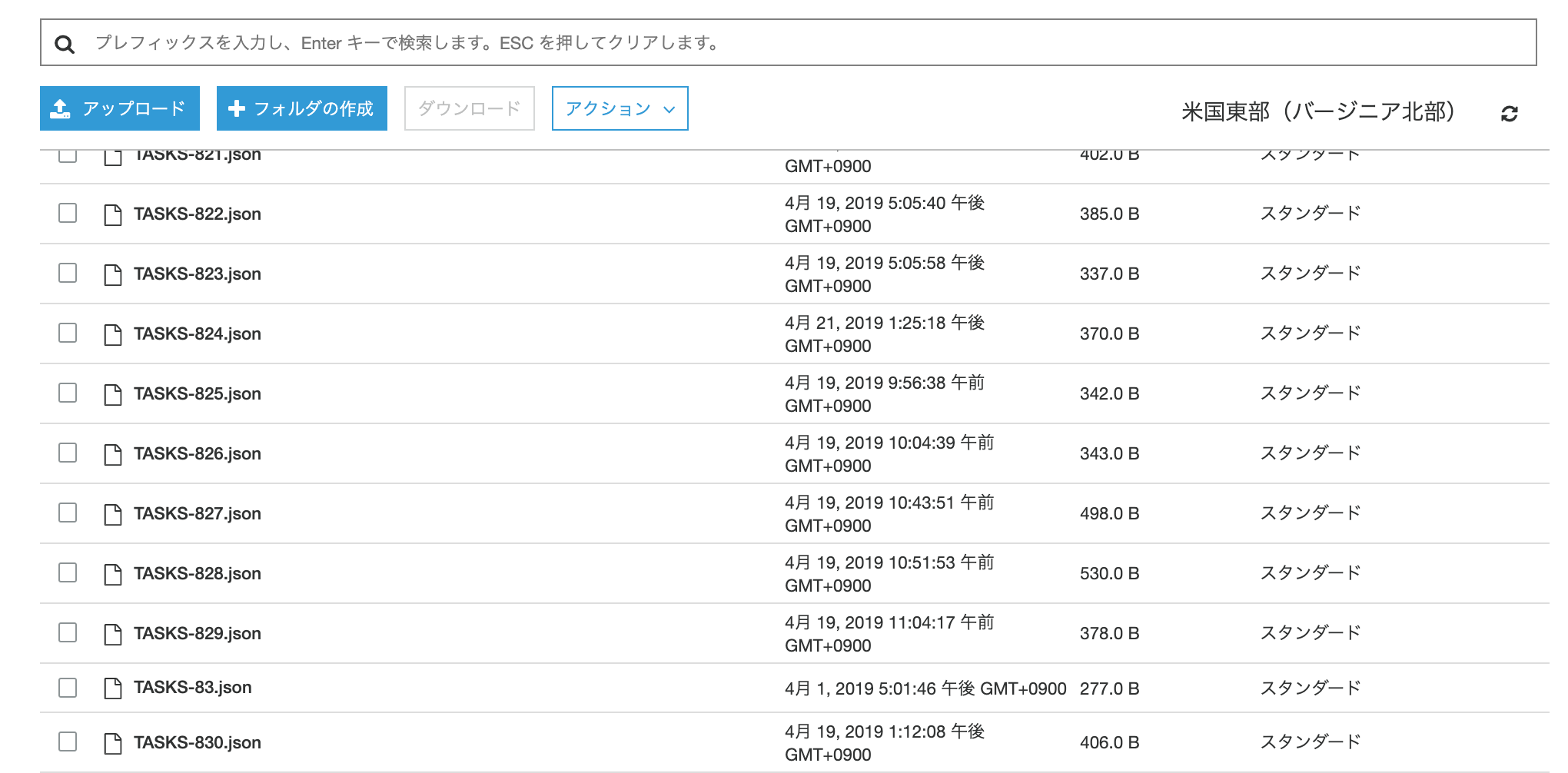
追加、更新された課題チケットのjsonデータはS3に格納されていきます。
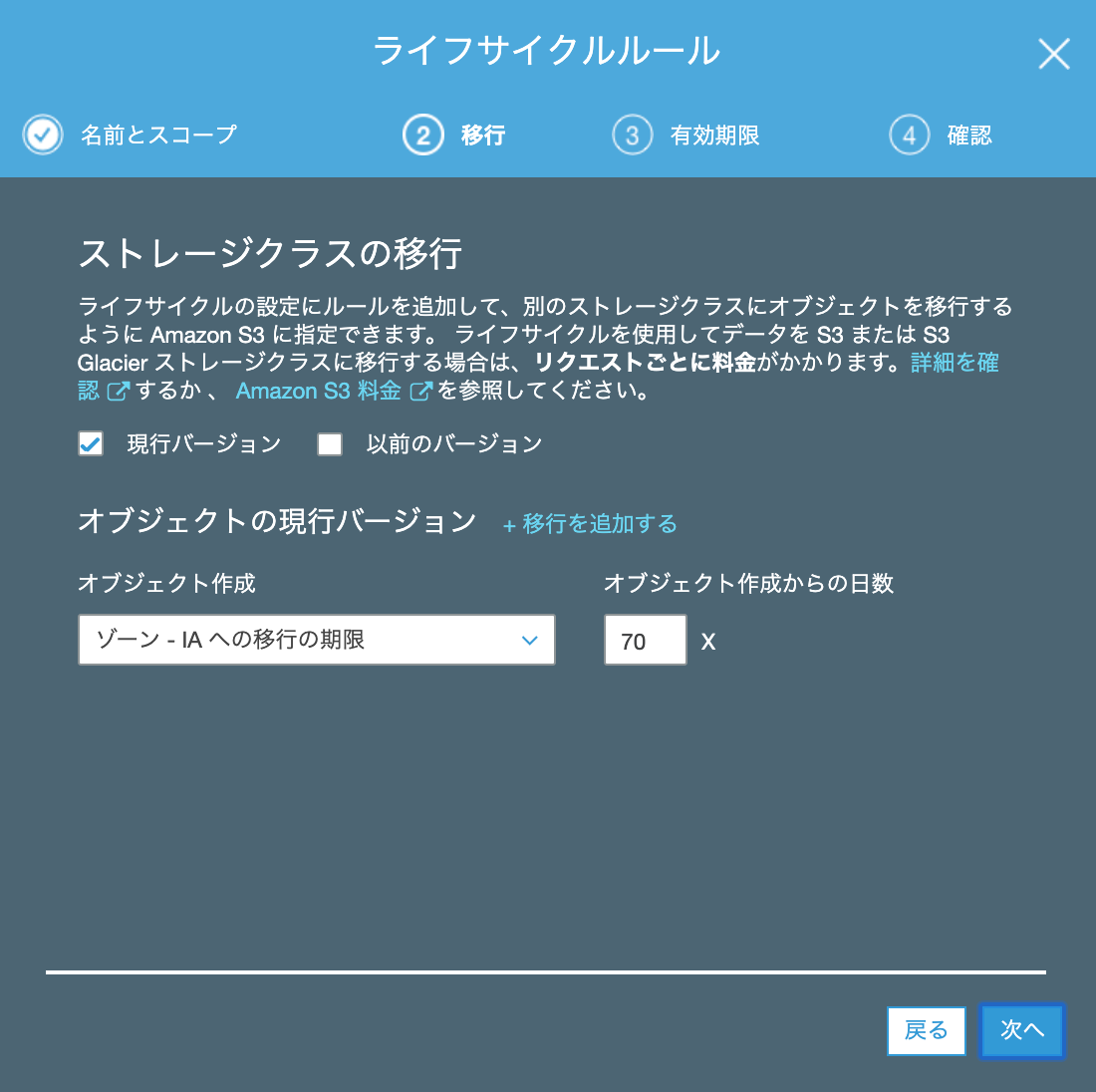
S3のライフサイクルルールでは、頻繁に見ても直近月か先月ぐらいまでだろうなあということで、70日経過した課題を1ゾーンIAストレージに移動してます。
なぜ、標準IA(低頻度アクセス)ストレージではなく、1ゾーンIAにしているかというと、元データはBacklogにあるので、万が一S3に置いているデータにアクセスできなくなったとしても、Backlog側から復旧ができるからです。
1ゾーンな分コストも下がります。
これでS3バケットにデータが溜まっていくようになりました。
次は可視化です。
S3バケットのデータをAthenaでテーブル構造に
AthenaのCREATE TABLE文はこちらです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE EXTERNAL TABLE IF NOT EXISTS backlog.ticket ( `milestone` string, `estimatedHours` double, `actualHours` double, `status` string, `assignee` string, `issueType` string, `startDate` string, `dueDate` string, `summary` string ) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' WITH SERDEPROPERTIES ( 'serialization.format' = '1' ) LOCATION 's3://trainocate-bl-data/' TBLPROPERTIES ('has_encrypted_data'='false'); |
これは、ゼロから書かなくても、マネジメントコンソールのAthenaで create tableメニューから、GUIで設定すれば、このCREATE TABLE文が生成されます。
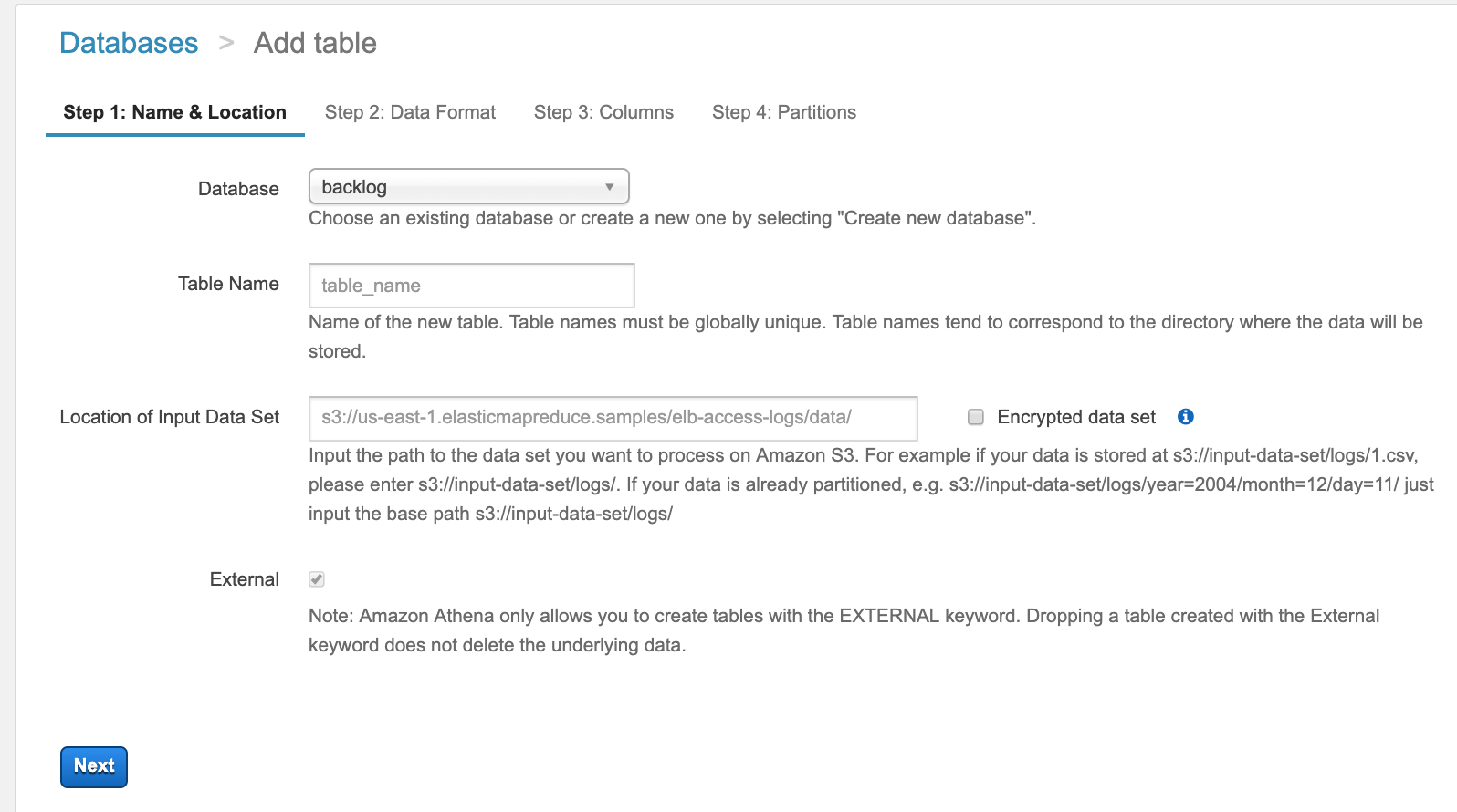
途中でもしも、カラムとかをポチポチやってるのが辛くなったら、途中まで設定してCREATE TABLE文を生成して、続きを書いてもいいと思います。
できたテーブルのレコードを確認してみます。
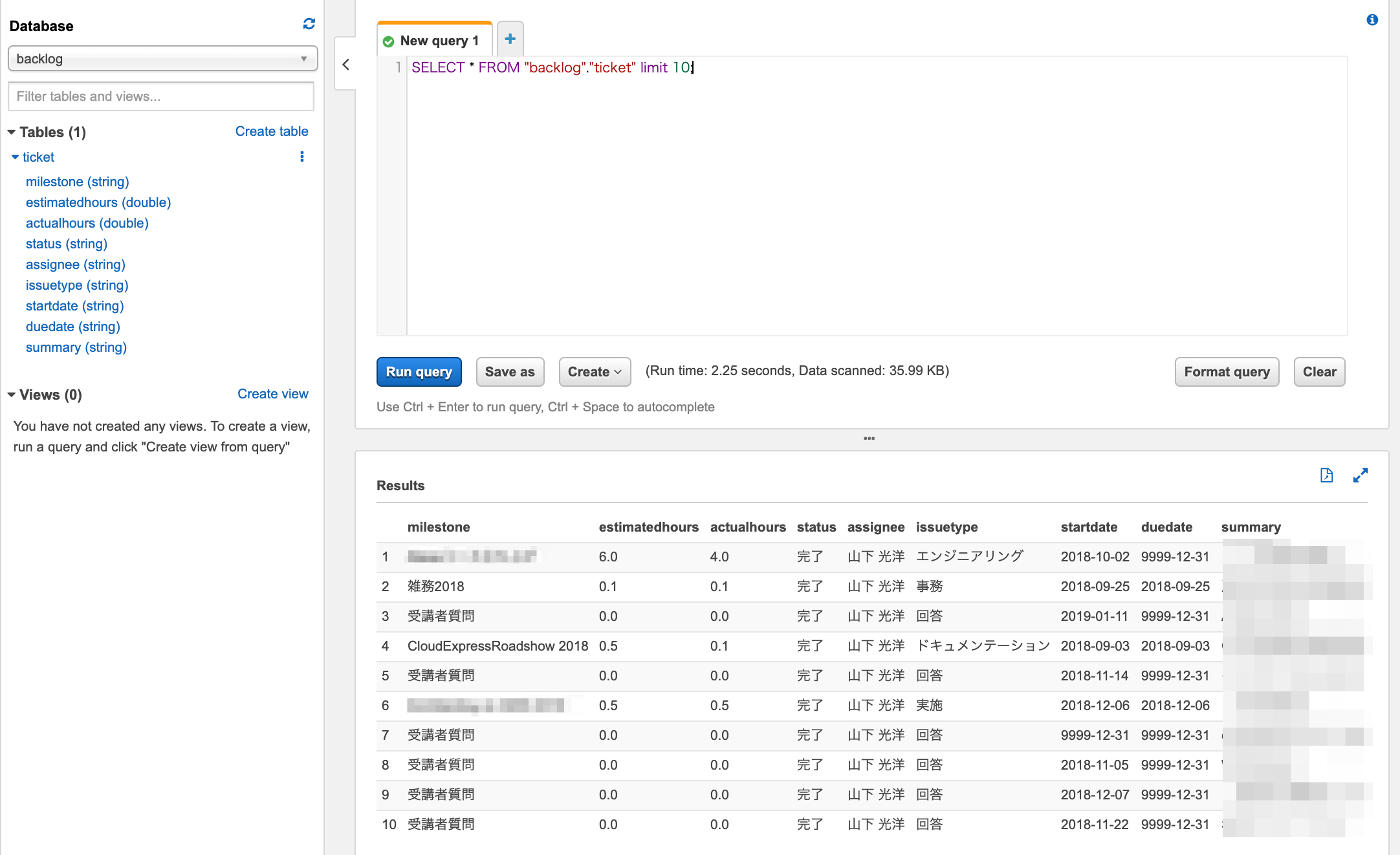
SELECTが実行できました。
次はいよいよ最後の手順の可視化です。
QuickSightでAthenaデータセットを可視化する
New Datasetで、Athenaを選択しました。
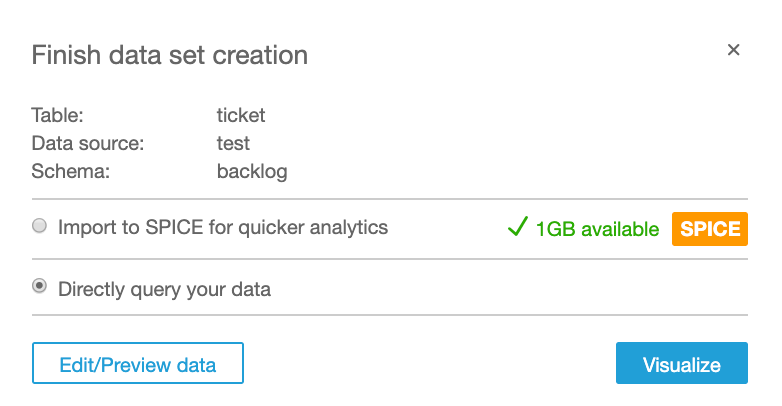
今回はSPICEは使わずにダイレクト検索にしました。
理由は後述します。
ビジュアライズを作っていきますが、ここはドラッグ & ドロップで直感的に作成できます。
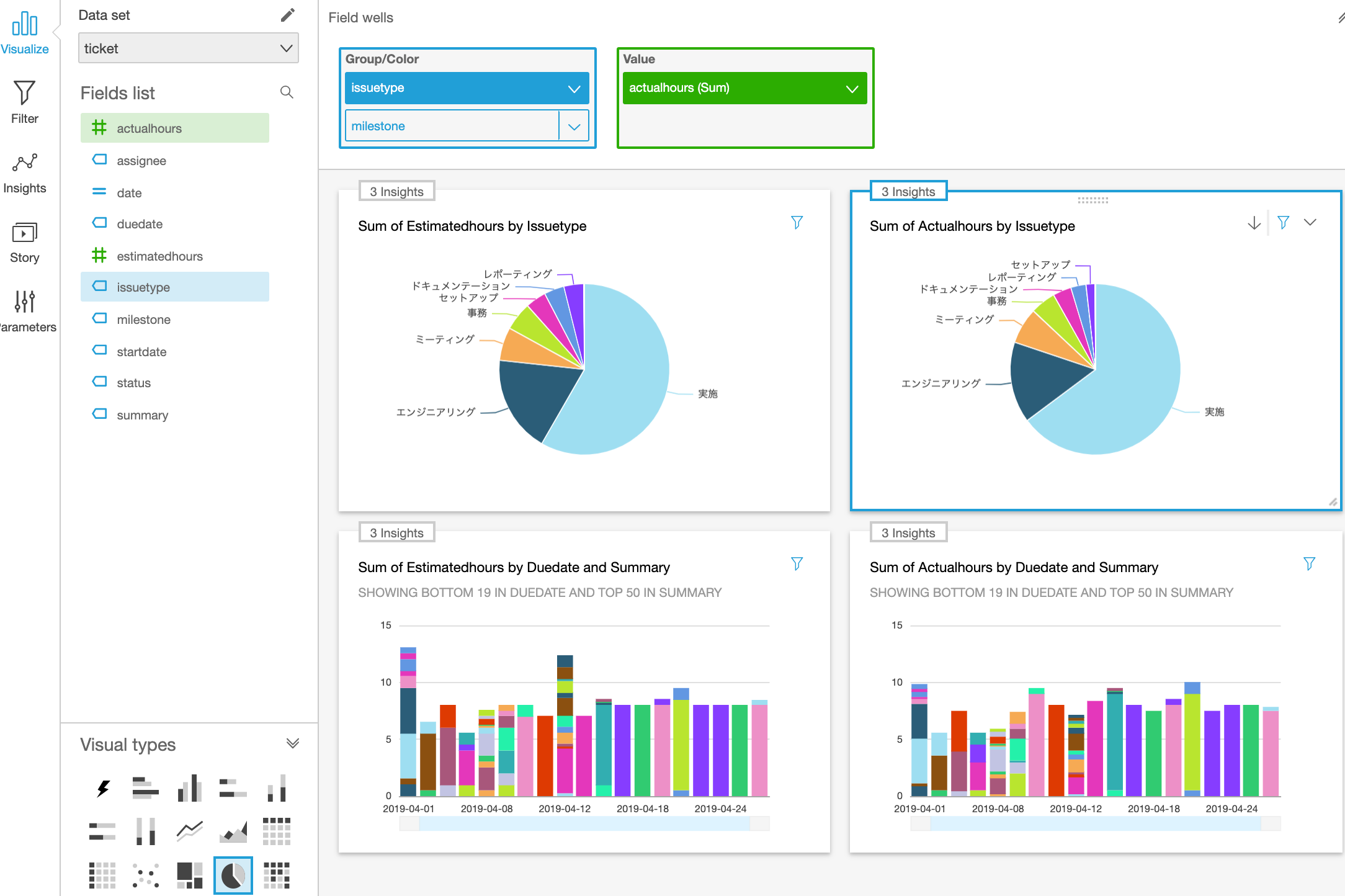
フィルターでは、日付と担当者のフィルターを追加しました。
この日付ですが、S3バケットでも、Athenaでも文字列として扱っていたのですね。
このままではQuickSightで文字列になってしまうので、範囲や大小で比較検索ができないです。
Athenaでビューを作って日付に変換してそれをQuickSightでデータセットにしても良さそうです。
今回はQuickSight側でCalculation Fieldを使いました。
このCalculation Fieldの関数がSPICEでは使えないものがあって、今回のparseDateがそうです。
ですので、ダイレクト検索にしています。
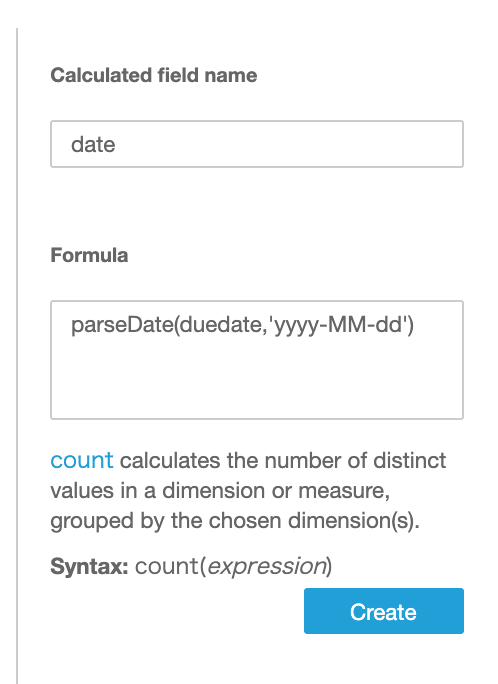
文字列の日付を parseDate(日付フィールド, ‘フォーマット’)で変換しています。
これで可視化ができました〜。
分析して仕事の効率化を進めます!
(長くなりましたのでTeamsへの通知は別エントリに書きます)
最後までお読みいただきましてありがとうございました!
「AWS認定資格試験テキスト&問題集 AWS認定ソリューションアーキテクト - プロフェッショナル 改訂第2版」という本を書きました。

「AWS認定資格試験テキスト AWS認定クラウドプラクティショナー 改訂第3版」という本を書きました。

「AWS認定資格試験テキスト AWS認定AIプラクティショナー」という本を書きました。

「ポケットスタディ AWS認定 デベロッパーアソシエイト [DVA-C02対応] 」という本を書きました。

「要点整理から攻略するAWS認定ソリューションアーキテクト-アソシエイト」という本を書きました。

「AWSではじめるLinux入門ガイド」という本を書きました。

開発ベンダー5年、ユーザ企業システム部門通算9年、ITインストラクター5年目でプロトタイプビルダーもやりだしたSoftware Engineerです。
質問はコメントかSNSなどからお気軽にどうぞ。
出来る限りなるべく答えます。
このブログの内容/発言の一切は個人の見解であり、所属する組織とは関係ありません。
このブログは経験したことなどの共有を目的としており、手順や結果などを保証するものではありません。
ご参考にされる際は、読者様自身のご判断にてご対応をお願いいたします。
また、勉強会やイベントのレポートは自分が気になったことをメモしたり、聞いて思ったことを書いていますので、登壇者の意見や発表内容ではありません。
関連記事
-

-
Amazon EC2 インスタンスメタデータサービス(IMDS) v2のみにしました
今さらながらですが、EC2 インスタンスメタデータサービス(IMDS) v2を確 …
-
-
DynamoDB IAMポリシーで特定属性だけを許可する
検証記録です。 対象テーブル 書籍のサンプルで作ったこちらです。 所属バンドの楽 …
-
-
EC2とRDSのMySQLを他のAWSアカウントへ移設する
他のAWSアカウントへシステムごと移設した場合の手順です。 構成はEC2とRDS …
-
-
AlexaにAWSの最新Feedを読み上げてもらう(Lambda Python)
年末にAmazon Echo Dotを購入しましたので、練習がてらAlexaスキ …
-
-
Active Directory認証でAWSマネジメントコンソールにSSO
こちらの2つのサイトを参考にすすめました。 Active Directory資産 …
-
-
CentOS 6.5にTeX Liveをインストールする
CentOS 6.5にTeX Liveをインストールする TeX Wikiを参考 …
-
-
AWS KMSのキーポリシーとアイデンティティベースポリシー
AWS KMSのCMKを作成する際に、管理者とキーユーザーを選択することで、以下 …
-
-
CloudFormationで起動テンプレートのバージョン更新をした際にAuto ScalingのEC2インスタンスを置き換える
やりたいこと タイトルのとおり、起動テンプレートのバージョン変更(AMIの置換) …
-
-
Amazon Timestreamのサンプルデータベースを起動しました
マネジメントコンソールTimestreamにアクセスして、[データベースを作成] …
-
-
Amazon Location Service入門ワークショップ-ジオコーディング
ジオコーディングにより住所を緯度経度に変換したり、逆に緯度経度から住所を求めたり …