
Amazon CloudSearchからAmazon Elasticsearch Serviceへ変えました

全文検索をする必要がありまして、本当はCloudSearchを使い続けたいのですが、今は小規模なので低いインスタンスを使いたくて、Amazon Elasticsearch Serviceに変えました。
データ移行はしていません。
データはソース元から入れ直しました。
変えた理由とAWS Lambda Python3.7でそれぞれに対してデータの追加、更新、検索の違いを記録しておこうと思います。
目次
何に使っているか
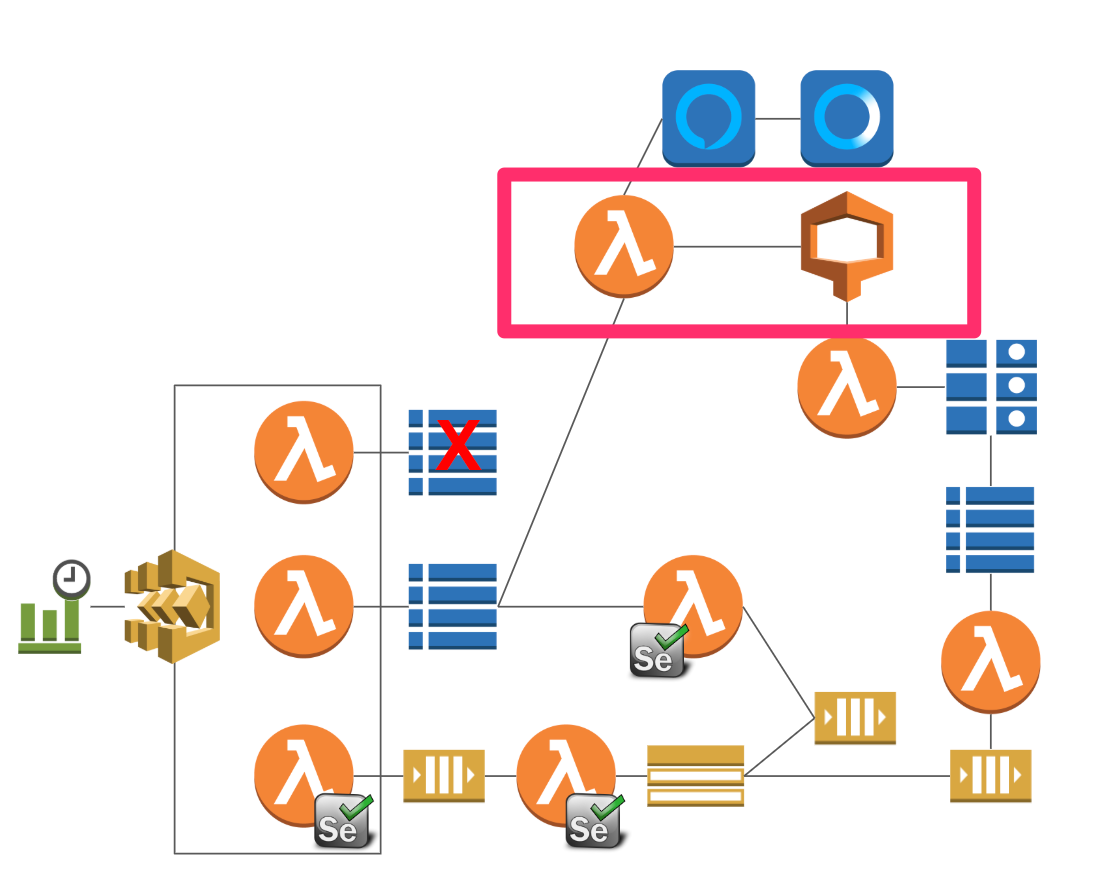
Alexaへのリクエストに対して、まずキーワードをマスターデータから全文検索しています。
その全文検索のために使用しています。
Amazon CloudSearchからAmazon Elasticsearch Serviceへ変えた理由
コストです。
アクセス数もまだまだ低いので最低限のコストにすることが目的です。
Amazon CloudSearchのコスト

2019年3月の課金結果です。
バージニア北部で一番低いsearch.m1.smallで$0.059 x 744時間で$43.9です。
Amazon Elasticsearch Serviceのコスト

2019年4月の途中からElasticsearch Serviceに変更したので途中経過です。
上記のCloudSearchと同じ期間条件にしてみると、
バージニア北部t2.smallで $0.036 x 744時間で$26.78ぐらいです。
それとEBSは10GBにしているのでその料金が、$0.135 x 10GBで$1.35です。
両方あわせて、$28.13が見込まれます。
可用性を考えるとノードを複数作って専用マスターノードも作ったりするべきで、それを考えるとCloudSearchの方がコストは低くなりそうなのですが、今回は可用性はおいといてとにかくコスト重視にしています。
Amazon Elasticsearch Service
とにかく作ってみました。
ちなみにCloudSearchはこちらの「Amazon CloudSearchにAWS Lambda(Python)からデータをアップロードする」に書いています。

[新しいドメインの作成]から作成しました。
リザーブドインスタンスもあるのですね。将来的には検討したいです。
今回はオンデマンドにします。
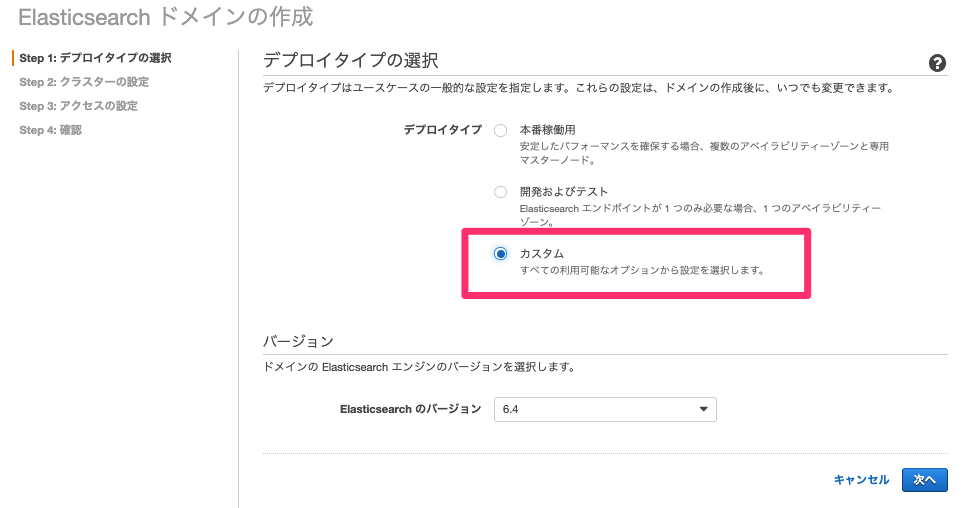
デプロイタイプはカスタムを選択しました。
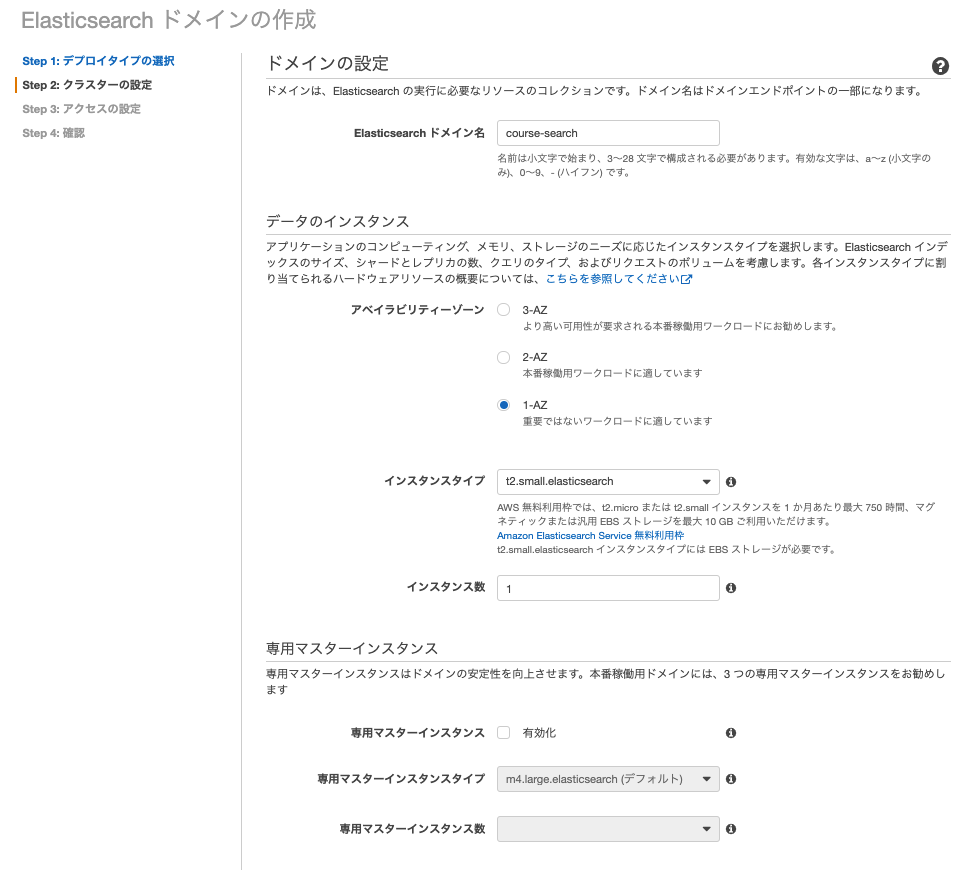
ドメイン名を設定して、とにかくコスト重視で、1つのAZで1つのインスタンス、インスタンスタイプは最も低いt2.small.elasticsearch、専用マスターインスタンスはなしです。
ストレージはEBSです。
(t2.small.elasticsearchの場合はEBSのみでインスタンスストレージは選択できません。)
サイズは設定できる最小の10GBにしました。
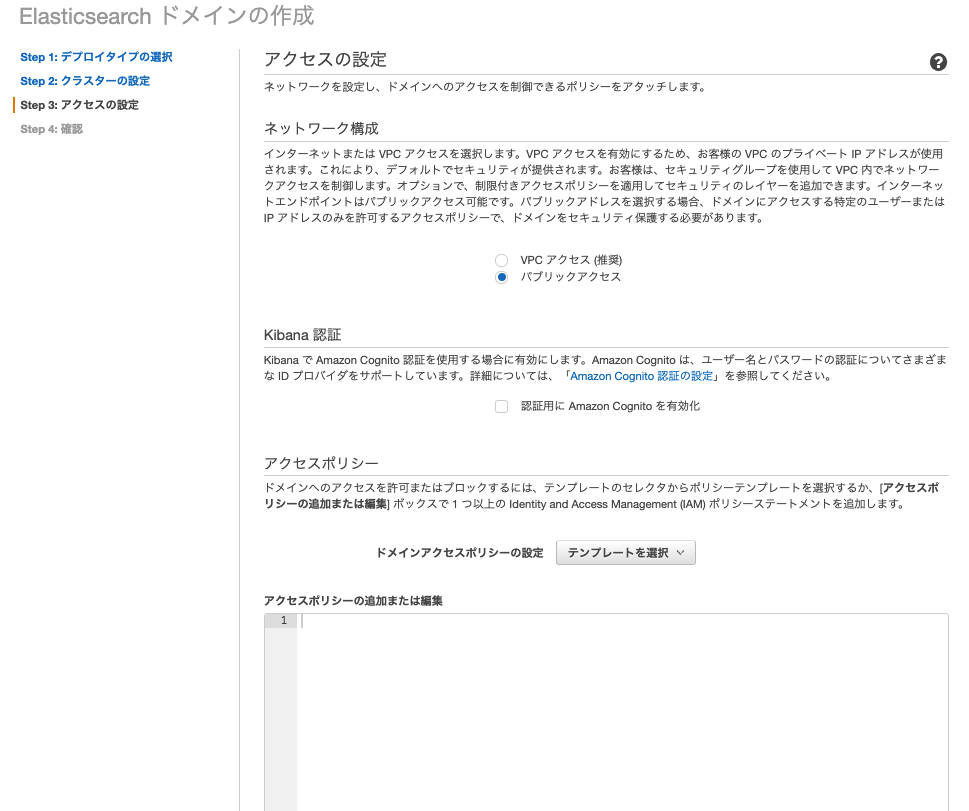
特に隠す必要のないデータですので、ネットワークはパブリックにしました。
ドメインポリシーは次のポリシーにしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:role/es_role" }, "Action": "es:*", "Resource": "arn:aws:es:us-east-1:123456789012:domain/course-search/*" } ] } |
特定のIAMロールからのアクセスだけを許可しています。
このIAMロールはLambdaで使用するIAMロールです。
あらかじめ作っておきます。
これでAmazon Elasticsearch Service側の設定は完了です。
AWS LambdaでAmazon Elasticsearch Serviceを使う
参考にさせていただいたサイト
ありがとうございます!!
- AWS LambdaからElasticsearch Serviceに接続するときに、IAM Roleを使う
- Lambda から elasticsearch service に何かする
- requests-aws4auth 0.9
- Python Elasticsearch Client
モジュール(requests-aws4auth, Elasticsearch Client)の準備
私はMacで作業しました。
pythonというディレクトリを作成して、そこにpipでインストールでしました。
|
1 2 3 |
$ pip install requests-aws4auth -t . $ pip install elasticsearch -t . |
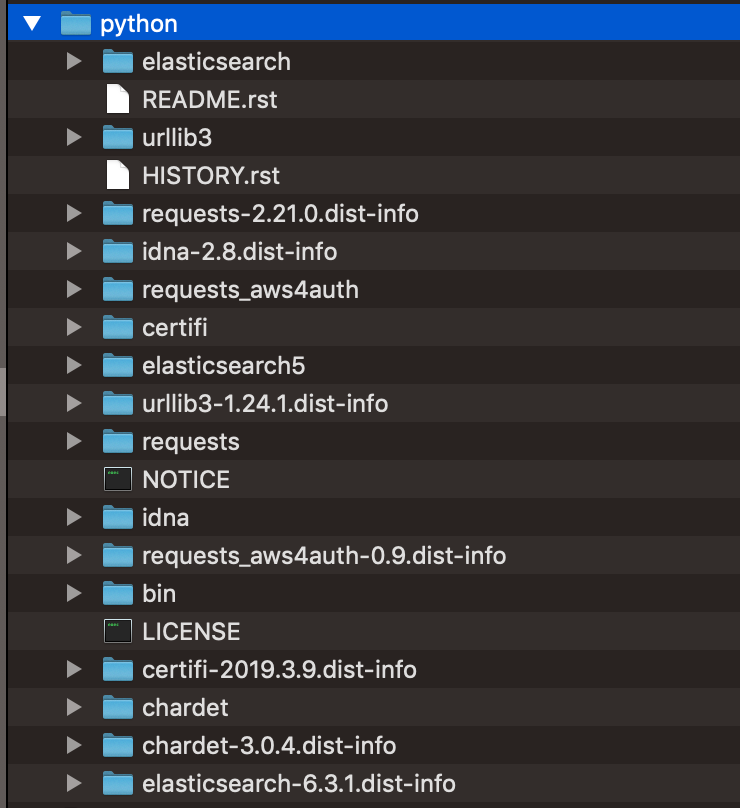
pythonディレクトリごとzipにしました。
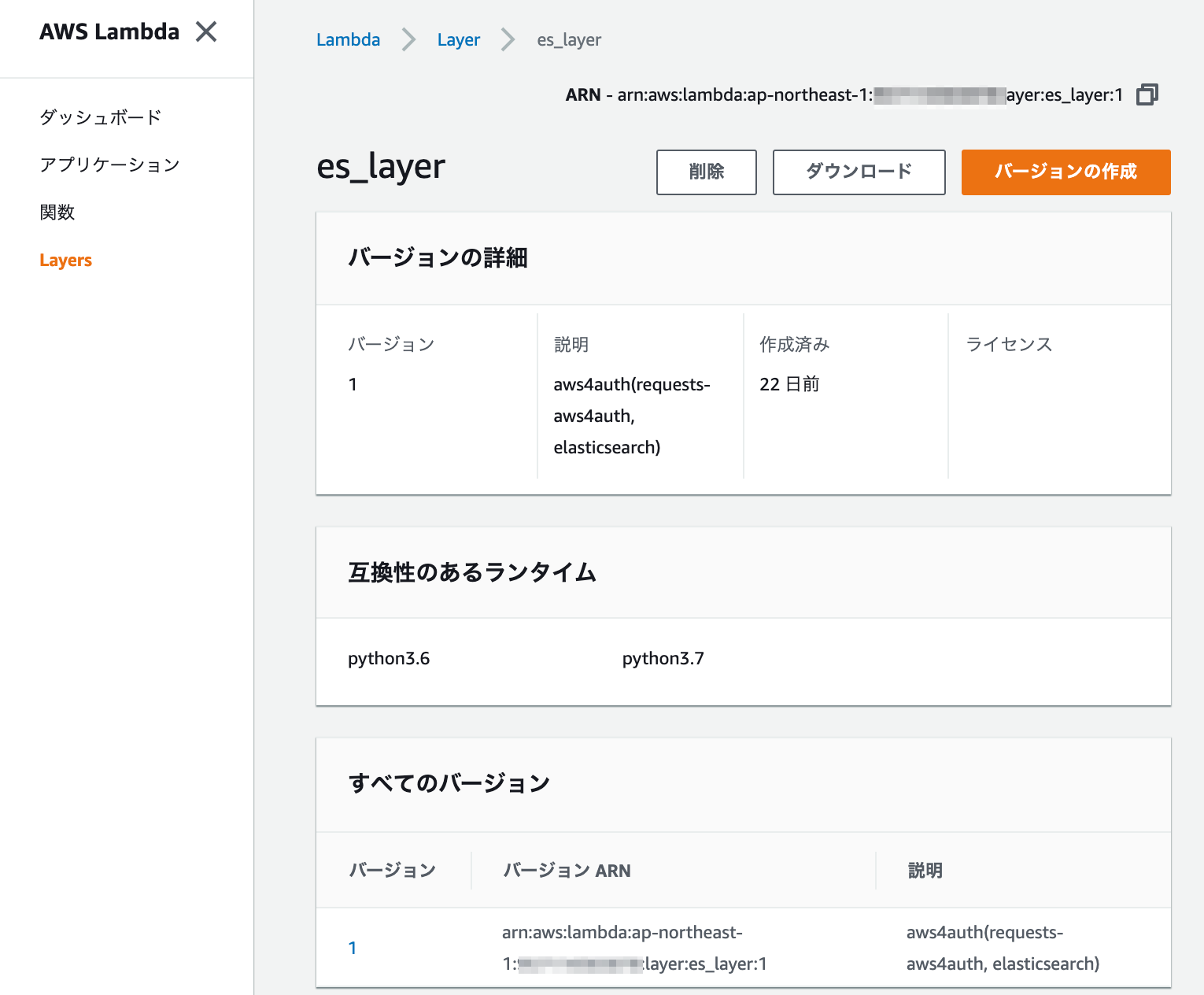
zipファイルをアップロードしてAWS Layersを作成しました。
AWS Lambdaの設定
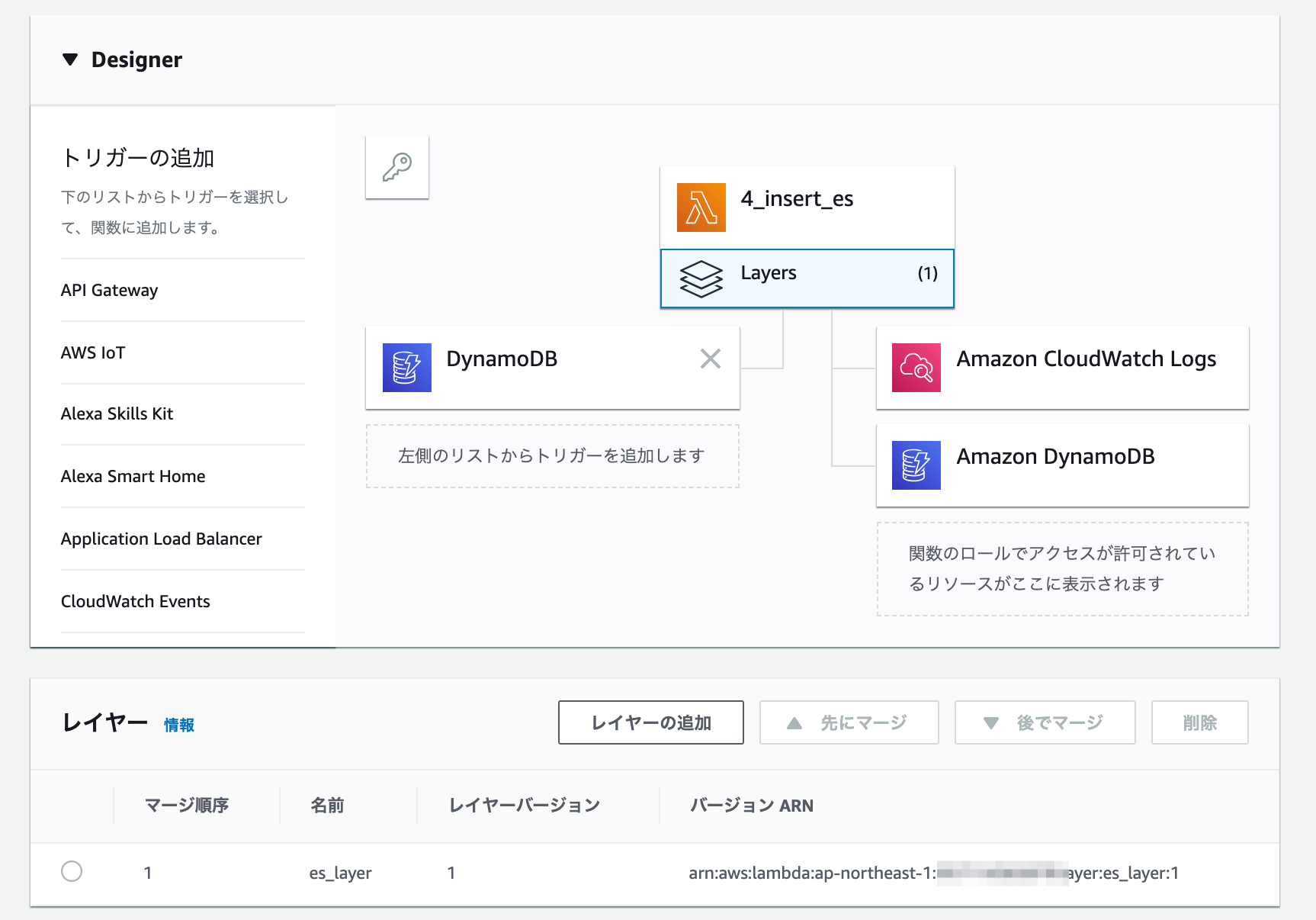
作成したLayersを設定しておきます。
IAMロールは、Elasticsearch Serviceドメインにアクセス許可したIAMロールを設定しています。
アクセス権限はCloudWatch Logsへのログの書き込みと、このLambdaがDynamoDB StreamsトリガーなのでStreamを読める権限を与えています。
ElasticSearch Serviceへのデータの読み書きはAWSのAPIではなく、ElasticSearchクライアントからのアクセスになるので、IAMロールの権限には含めません。
環境変数
- ENDPOINT
Elasticsearch Serviceのエンドポイントを指定しました。 -
REGION
Elasticsearch Serviceのリージョン。 -
TZ
Asia/Tokyoを指定しました。
データを登録するAWS Lambdaのコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
import traceback, os, logging.config from elasticsearch import Elasticsearch, RequestsHttpConnection, helpers from requests_aws4auth import AWS4Auth logger = logging.getLogger() logger.setLevel(logging.INFO) ENDPOINT = os.environ.get('ENDPOINT', '') REGION = os.environ.get('REGION', '') def lambda_handler(event, context): try: awsauth = AWS4Auth( os.environ.get('AWS_ACCESS_KEY_ID', ''), os.environ.get('AWS_SECRET_ACCESS_KEY', ''), REGION, 'es', session_token=os.environ['AWS_SESSION_TOKEN'] ) es = Elasticsearch( hosts=[{ 'host': ENDPOINT, 'port': 443 }], http_auth=awsauth, use_ssl=True, verify_certs=True, connection_class=RequestsHttpConnection, timeout=1500 ) actions = [] for record in event['Records']: if record['eventName'] == 'REMOVE': continue course_code = record['dynamodb']['NewImage']['course_code']['S'] course_name = record['dynamodb']['NewImage']['course_name']['S'] document = {'name': course_name} actions.append({ '_index': 'course_index', '_type': 'course', '_id': course_code, '_source': document }) if len(actions) == 0: return response = helpers.bulk(es, actions) logger.info(response) except: logger.error(traceback.format_exc()) raise Exception(traceback.format_exc()) |
IAMロールを設定することにより、環境変数にAWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, AWS_SESSION_TOKENを取得できます。
これをAWS4Authに設定しまして、Elasticsearchクライアントを作成しました。
複数のインデックス作成なので、actionsの配列にインデックスを作成するアクションを追加していきます。
helpers.bulkで配列化したアクションを実行して複数のインデックスを作成しました。
‘_id’に一意となるキーを指定して、’name’が更新されたときにインデックスが更新できるようにしました。
全文検索するAWS Lambdaのコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
import traceback, logging.config, os from elasticsearch import Elasticsearch, RequestsHttpConnection, helpers from requests_aws4auth import AWS4Auth logger = logging.getLogger() logger.setLevel(logging.INFO) ENDPOINT = os.environ.get('ENDPOINT', '') REGION = os.environ.get('REGION', '') def lambda_handler(event, context): try: logger.info(event) awsauth = AWS4Auth( os.environ.get('AWS_ACCESS_KEY_ID', ''), os.environ.get('AWS_SECRET_ACCESS_KEY', ''), REGION, 'es', session_token=os.environ['AWS_SESSION_TOKEN'] ) es = Elasticsearch( hosts=[{ 'host': ENDPOINT, 'port': 443 }], http_auth=awsauth, use_ssl=True, verify_certs=True, connection_class=RequestsHttpConnection, timeout=1500 ) response = es.search( index="course_index", body={ "query": { "match": { 'name': event['query'] } } } ) logger.info(response) return response except: logger.error(traceback.format_exc()) raise Exception(traceback.format_exc()) |
このAWS Lambdaは今はAPI Gatewayトリガーにしていてチャットボットからのリクエストに対応しています。
リクエストは’query’パラメータで受けています。
‘query’パラメータにはキーワードが与えられるのでそれで検索をしています。
例 : {‘query’: ‘aws’}
ここで作ったAPIに対してのチャットボットからのリクエストが例えば次のようなコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
def course_search_master(search_text): payload = { "query": search_text } response = requests.get( api_endpoint, data=json.dumps(payload) ) data = response.json() return_text = '' if data['hits']['total'] > 0: hits_records = data['hits']['hits'] for record in hits_records: return_text += record['_id'] + ':' return_text += record['_source']['name'] + '\n\n' return return_text |
Elasticsearch Serviceのレスポンスの[hits][total]に結果が何件あったかがありますので、結果があったかを判定して、[‘hits’][‘hits’][‘_source’]から値を取得できました。
[参考]CloudSearchで全文検索するAWS Lambdaのコード
CloudSearchでデータのアップロードをするコードは「Amazon CloudSearchにAWS Lambda(Python)からデータをアップロードする」に書いていますのでそちらをご参照ください。
CloudSearchで全文検索するコードは次のようなコードを使っていました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import traceback, logging.config, json, os,boto3 logger = logging.getLogger() logger.setLevel(logging.INFO) ENDPOINT = os.environ.get('ENDPOINT', '') def lambda_handler(event, context): try: logger.info(event) domain = boto3.client( 'cloudsearchdomain', endpoint_url=ENDPOINT, region_name='us-east-1' ) response = domain.search( query=event['query'] ) logger.info(response) return response except: logger.error(traceback.format_exc()) raise Exception(traceback.format_exc()) |
チャットボットからのリクエストは次のようなコードです。
ElasticSearchと若干レスポンスが異なっています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
def course_search_master(search_text): payload = { "query": search_text } response = requests.get( api_endpoint, data=json.dumps(payload) ) data = response.json() return_text = '' if data['hits']['found'] > 0: hits_records = data['hits']['hit'] for record in hits_records: return_text += record['fields']['course_code'][0] + ':' return_text += record['fields']['course_name'][0] + '\n\n' return return_text |
最後までお読みいただきましてありがとうございました!
「AWS認定資格試験テキスト&問題集 AWS認定ソリューションアーキテクト - プロフェッショナル 改訂第2版」という本を書きました。

「AWS認定資格試験テキスト AWS認定クラウドプラクティショナー 改訂第3版」という本を書きました。

「AWS認定資格試験テキスト AWS認定AIプラクティショナー」という本を書きました。

「AWS教科書 AWS認定デベロッパーアソシエイト テキスト&問題集 」という本を書きました。

「要点整理から攻略するAWS認定ソリューションアーキテクト-アソシエイト」という本を書きました。

「AWSではじめるLinux入門ガイド」という本を書きました。

開発ベンダー5年、ユーザ企業システム部門通算9年、ITインストラクター5年目でプロトタイプビルダーもやりだしたSoftware Engineerです。
質問はコメントかSNSなどからお気軽にどうぞ。
出来る限りなるべく答えます。
このブログの内容/発言の一切は個人の見解であり、所属する組織とは関係ありません。
このブログは経験したことなどの共有を目的としており、手順や結果などを保証するものではありません。
ご参考にされる際は、読者様自身のご判断にてご対応をお願いいたします。
また、勉強会やイベントのレポートは自分が気になったことをメモしたり、聞いて思ったことを書いていますので、登壇者の意見や発表内容ではありません。
関連記事
-

-
cfn-initでEC2インスタンスにPHPをインストールしWebサーバーを起動する
AWS CloudFormation による Amazon EC2 へのアプリケ …
-
-
EC2インスタンスWindowsでセッションマネージャーを使う
WindowsのEC2インスタンスでセッションマネージャーを使ってみたことがない …
-
-
AWS Client VPNのクライアント接続ハンドラを試してみました
AWS Client VPNを設定しましたで証明書とかせっかく作ったので、いろい …
-
-
Amazon Augmented AI (Amazon A2I) のチュートリアル
Amazon Augmented AI (Amazon A2I)を使ったことがあ …
-
-
AtomエディタでEC2のファイルを直接編集する
Webページを編集していてEC2のファイルをvimエディタでさわったりしています …
-
-
Amazon LinuxにRedmine をインストールする(手順整理版)
Amazon LinuxにRedmineをインストールしました手順を記載します。 …
-
-
AWS GlueでAurora JDBC接続でS3へのジョブを実行
Aurora Serverless v1のMySQLタイプデータベースからS3へ …
-
-
EC2 セッションマネージャにEC2インスタンスの一覧から接続できるようになりました
EC2に接続する時に、どうしてもSSHクライアントから接続しないといけない場合を …
-
-
GoogleForm,GASからAPI Gateway, Lambdaで入力情報をDynamoDBに格納する
vol.26 AWS認定試験テキスト認定クラウドプラクティショナーのデモ(Dyn …
-
-
S3 Intelligent-Tieringのオブジェクトの階層移動をCloudWatchメトリクスで確認
CloudWatchメトリクスの保存期間は現時点で15ヶ月(455日)なのでそろ …