
Amazon CloudSearchにAWS Lambda(Python)からデータをアップロードする
このブログはゆるっとアドベントカレンダー Advent Calendar 2018に参加しました。
Alexaスキルを作るにあたって全文検索できたほうがいいかなあと思いまして、実装してみました。
でも、全文検索だと戻る量が多くなってしまうので、DyanmoDBのソートキーを使って前方一致のほうが望ましいかと思い直しているところです。
せっかくやってみたので書き残しておきます。
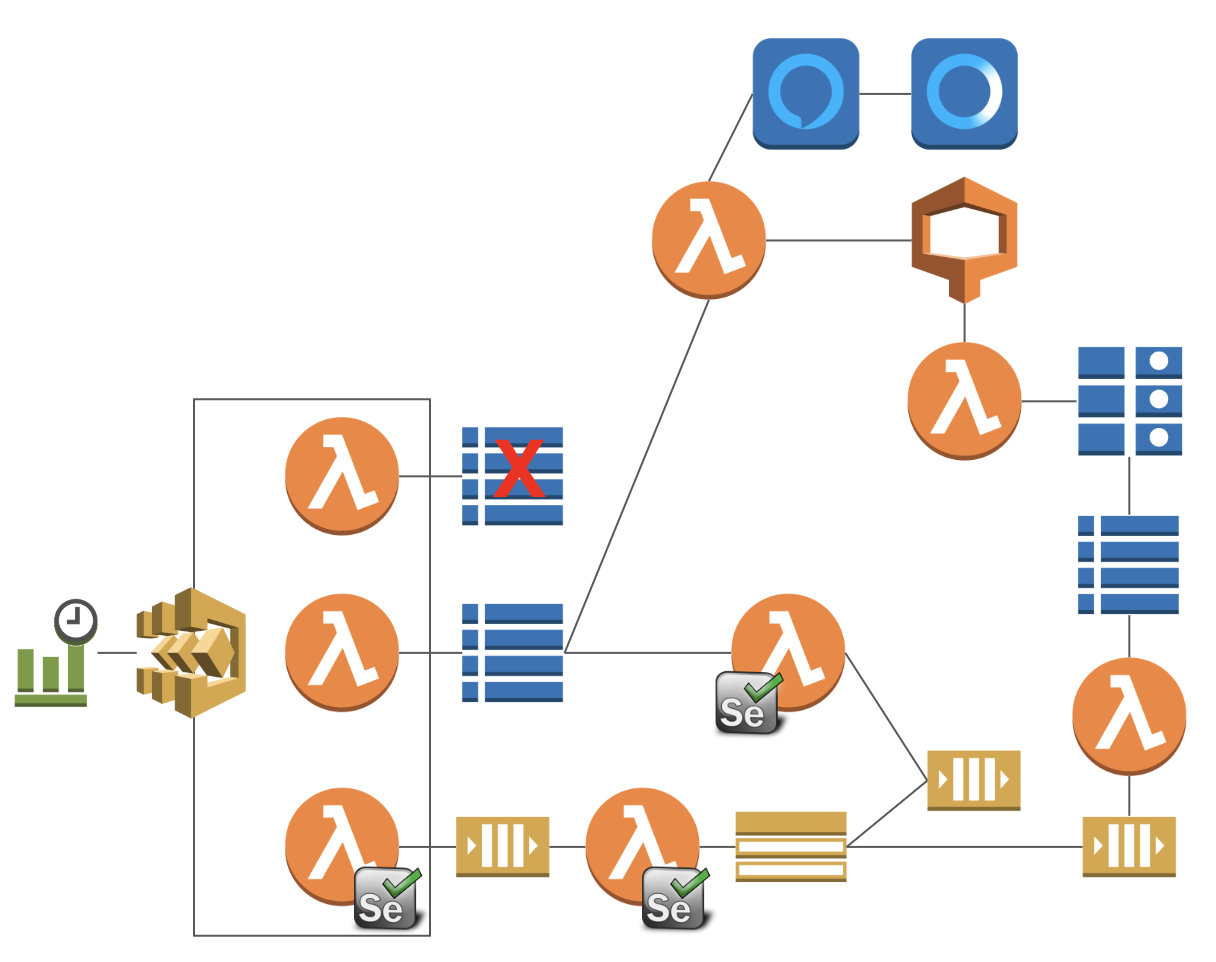
構成はこちらの日次でCloudSearchにデータをアップロードしているところです。
目次
Amazon CloudSearch
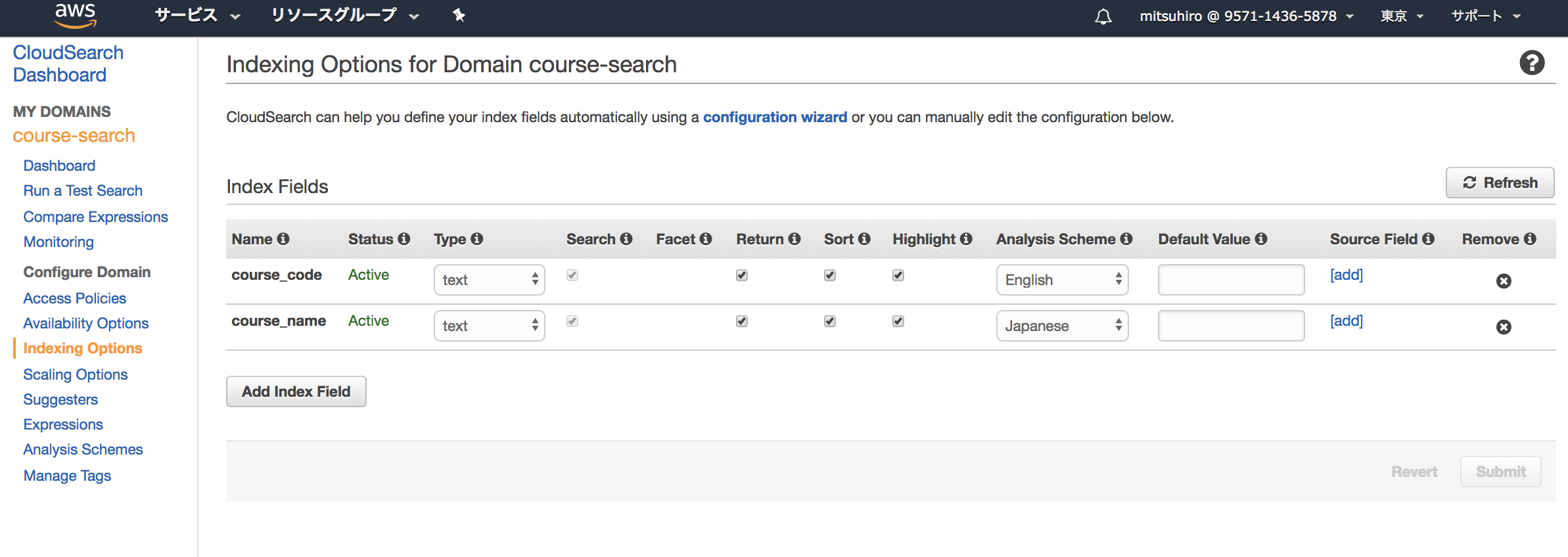
ドメインを新規作成して、course_codeとcourse_nameという2つのフィールドを作りました。
AWS Lambda
IAMロールはもちろんCloudSearchへのアップロードが必要です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
import traceback, json, os, boto3 import logging.config logger = logging.getLogger() logger.setLevel(logging.INFO) ENDPOINT = os.environ.get('ENDPOINT', '') def lambda_handler(event, context): try: logger.info(event) domain = boto3.client( 'cloudsearchdomain', endpoint_url=ENDPOINT ) documents = [] for record in event['Records']: if record['eventName'] == 'REMOVE': continue course_code = record['dynamodb']['NewImage']['course_code']['S'] course_name = record['dynamodb']['NewImage']['course_name']['S'] document = { 'type': 'add', 'id': course_code, 'fields': { 'course_code': course_code, 'course_name': course_name } } documents.append(document) if len(documents) == 0: return response = domain.upload_documents( documents=json.dumps(documents), contentType='application/json' ) logger.info(response) except: raise Exception(traceback.format_exc()) |
- CloudSearchドメインのエンドポイントは環境変数に設定しています。
- トリガーはDyanmoDBで新規のアイテムのみを対象にしています。
- boto3.clientはcloudsearchdomainです。
- documentsでCloudSearchへの操作をJsonで新規アイテムの数だけ配列にしています。
- upload_documentsでcontentTypeを’application/json’にしてます。
これで、データが追加されて、全文検索できました!!
最後までお読みいただきましてありがとうございました!
「AWS認定資格試験テキスト&問題集 AWS認定ソリューションアーキテクト - プロフェッショナル 改訂第2版」という本を書きました。

「AWS認定資格試験テキスト AWS認定クラウドプラクティショナー 改訂第3版」という本を書きました。

「AWS認定資格試験テキスト AWS認定AIプラクティショナー」という本を書きました。

「ポケットスタディ AWS認定 デベロッパーアソシエイト [DVA-C02対応] 」という本を書きました。

「要点整理から攻略するAWS認定ソリューションアーキテクト-アソシエイト」という本を書きました。

「AWSではじめるLinux入門ガイド」という本を書きました。

開発ベンダー5年、ユーザ企業システム部門通算9年、ITインストラクター5年目でプロトタイプビルダーもやりだしたSoftware Engineerです。
質問はコメントかSNSなどからお気軽にどうぞ。
出来る限りなるべく答えます。
このブログの内容/発言の一切は個人の見解であり、所属する組織とは関係ありません。
このブログは経験したことなどの共有を目的としており、手順や結果などを保証するものではありません。
ご参考にされる際は、読者様自身のご判断にてご対応をお願いいたします。
また、勉強会やイベントのレポートは自分が気になったことをメモしたり、聞いて思ったことを書いていますので、登壇者の意見や発表内容ではありません。
関連記事
-

-
Amazon Connectのパスワードどころかユーザー名も忘れたのでEmergency accessした
長い間放置していたAmazon Connect環境にアクセスしようとしたところ、 …
-
-
AWS EC2 インスタンスステータスのチェックで失敗 原因はPHP-FPMのOOM-KILLER
先週に引き続きEC2のインスタンスステータスチェックで失敗 再起動するも失敗する …
-
-
スポットインスタンスの削減額情報を見ました
なんだこれ?と思って、検索してみたら、2018年11月からあったのですね。 Am …
-
-
Amazon SNSサブスクリプションフィルターを設定してPython(boto3)からPublish
上記のような構成でRocketChatを使うとき使わないときがあります。 都度都 …
-
-
ユーザーガイドの方法でGithubからCodeCommitへリポジトリを移行する
GitリポジトリをAWS CodeCommitに移行するを参照しました。 環境 …
-
-
AlexaにAWSの最新Feedを読み上げてもらう(Lambda Python)
年末にAmazon Echo Dotを購入しましたので、練習がてらAlexaスキ …
-
-
AWSマネジメントコンソールのマルチセッションサポート
AWSマネジメントコンソールにマルチセッションサポートが追加されましたので使いま …
-
-
GoogleフォームからAPI Gatewayで作成したREST APIにPOSTリクエストする
「API GatewayからLambdaを介さずにSNSトピックへ送信」の続きで …
-
-
AWS認定試験の自宅受験で壁のポスターを注意されちゃいました
AWS認定オンライン受験をしてみましたに書きましたとおり、自宅受験デビューしまし …
-
-
Amazon LinuxのNginx+RDS MySQLにレンタルWebサーバーからWordPressを移設する(失敗、手戻りそのまま記載版)
勉強のためブログサイトを長らくお世話になったロリポップさんから、AWSに移設する …