
「機械学習モデルをトレーニングする」チュートリアル
Amazon SageMaker Clarifyのデモを記録しておきたいので「機械学習モデルをトレーニングする」チュートリアルをやりました。
最終的に使用したコードは記録としてGitHubにアップロードしています。
sagemaker-clarify-tutorial
目次
Amazon SageMaker Sudioドメインの設定
チュートリアル付属のCloudFormationテンプレートは使用せずに、クイックセットアップで作成しました。
Amazon SageMaker AIのクイックセットアップ
SageMaker AI StudioでJupyterLab スペースを作成しJupyterLab を起動、S3拡張のインストール
変更箇所
ドキュメントにあるxgboostとpandasのバージョン指定は外して実行しています。
|
1 2 |
%pip install -q xgboost pandas |
対象データ
sagemaker.Session().default_bucket()が書き込み先のバケットになっています。
SageMakerがアカウント、リージョンでデフォルトで使用しているバケットです。
トレーニングデータと検証データは次のURLでアクセスできました。
トレーニングデータ
https://sagemaker-sample-files.s3.amazonaws.com/datasets/tabular/synthetic_automobile_claims/train.csv
検証データ
https://sagemaker-sample-files.s3.amazonaws.com/datasets/tabular/synthetic_automobile_claims/test.csv
保険の請求データで、不正が行われていないかを検知する推論モデルを作成するシナリオです。
不正か不正でないかの判定ですので、二項分類問題です。
データには、詐欺, 関係車両数, 負傷者数, 目撃者数, 警察報告書入手可能, クレーム有無, 請求総額, 日時, 顧客年齢, 顧客としての月数, 過去のクレーム数, 家族構成, 州, 性別などの特徴を表すデータがあります。
xgboost_train.py
コンテナで実行されるトレーニングスクリプトです。
%%writefile xgboost_train.pyでxgboost_train.pyを作成しています。
from sklearn.metrics import roc_auc_score
モデル評価のためのAUCスコア計算関数をインポートしています。
parser = argparse.ArgumentParser():
コマンドライン引数を解析するためのパーサーを初期化します。
この次の行からparser.add_argument(“–num_round”, type=int, default=100)のようにパラメータを定義しています。
XGBoostモデルのハイパーパラメータです。
- num_round: ブースティングの反復回数(デフォルト: 100回)
- max_depth: 決定木の最大深さ(デフォルト: 3)
- eta: 学習率(デフォルト: 0.2)
- subsample: 各ブースティング反復でサンプリングする訓練データの割合(デフォルト: 0.9)
- colsample_bytree: 木を構築する際に使用する特徴量の割合(デフォルト: 0.8)
- objective: 最適化する目的関数(デフォルト: “binary:logistic”、二値分類用)
- eval_metric: 評価指標(デフォルト: “auc”)
- nfold: クロスバリデーションの分割数(デフォルト: 3)
- early_stopping_rounds: 早期停止の基準となるラウンド数(デフォルト: 3)
次にSageMaker固有のパラメータが続きます。
- train_data_dir: 訓練データの場所(SageMaker環境変数 “SM_CHANNEL_TRAIN” から取得)
- validation_data_dir: 検証データの場所(SageMaker環境変数 “SM_CHANNEL_VALIDATION” から取得)
- model_dir: 訓練されたモデルを保存する場所(SageMaker環境変数 “SM_MODEL_DIR” から取得、デフォルト: /opt/ml/model)
- output_data_dir: モデルの出力アーティファクトを保存する場所(SageMaker環境変数 “SM_OUTPUT_DATA_DIR” から取得、デフォルト: /opt/ml/output/data)
次にトレーニングデータと検証データの読み込みと前処理を行います。
- data_train = pd.read_csv(f”{args.train_data_dir}/train.csv”)
訓練データをCSVファイルから読み込みます。 -
train = data_train.drop(“fraud”, axis=1)
目的変数(”fraud”)を除いた特徴量データを作成します。 -
label_train = pd.DataFrame(data_train[“fraud”])
目的変数(”fraud”)をDataFrameとして抽出します。
trainが問題で、label_trainが目的とする答えがあるデータとして分けています。
- dtrain = xgb.DMatrix(train, label=label_train)
XGBoost専用のデータ構造(DMatrix)に変換します。
同様の処理を検証データにも行います。
- cv_results = xgb.cv()
クロスバリデーション関数を使用し、結果をcv_resultsに格納します。 -
metrics=[“auc”], 評価指標としてAUCを使用します。
-
seed=42, 再現性確保のための乱数シード値を設定します。
-
model = xgb.train(params=params, dtrain=dtrain, num_boost_round=len(cv_results))
モデルのトレーニングをします。 -
train_pred = model.predict(dtrain)
-
validation_pred = model.predict(dvalidation)
トレーニングデータと検証データに対してそれぞれ予測を行います。 -
train_auc = roc_auc_score(label_train, train_pred)
-
validation_auc = roc_auc_score(label_validation, validation_pred)
トレーニングデータと検証データそれぞれのAUCスコアを計算します。 -
json.dump(metrics_data, f)
メトリクスデータをJSONファイルとして保存します。 -
joblib.dump(model, f)
訓練されたモデルをバイナリファイルとして保存します
ハイパーパラメーターチューニング
static_hyperparams = {}
チューニングの対象としない静的パラメータを指定しています。
- eval_metric: モデルの評価指標として「AUC」(Area Under the ROC Curve)を使用
- objective: 「二値分類のロジスティック回帰」を目的関数として使用
- num_round: ブースティングの反復回数を5回に設定
xgb_estimator = XGBoost()
XGBoostフレームワークを使用するEstimatorオブジェクト
- entry_point=”xgboost_train.py”: トレーニングスクリプトのファイル名を指定
- output_path: モデルアーティファクトの保存先S3パスを指定
- code_location: トレーニングコードの保存先S3パスを指定
- hyperparameters: 先ほど定義した静的ハイパーパラメータを指定
- role: SageMakerが使用するIAMロールを指定
- instance_count: トレーニングインスタンスの数を指定
- instance_type: トレーニングに使用するEC2インスタンスタイプを指定
- framework_version: XGBoostのバージョンを「1.3-1」に指定
- base_job_name: トレーニングジョブの基本名を指定
hyperparameter_ranges = {}
- eta: 学習率を0から1までの連続値で探索
- subsample: 各トレーニングラウンドでサンプリングする訓練データの割合を0.7から0.95の連続値で探索
- colsample_bytree: 木を構築する際に使用する特徴量の割合を0.7から0.95の連続値で探索
- max_depth: 決定木の最大深さを1から5までの整数値で探索
objective_metric_name = “validation:auc”
ハイパーパラメータチューニングで最適化する目標メトリックを「validation:auc」(検証データでのAUC)に設定しています。このメトリックが最大化されるようなハイパーパラメータの組み合わせを探索します。
tuner_config_dict = {}
ハイパーパラメータチューニングを行うためのHyperparameterTunerオブジェクト
- estimator: 先ほど作成したXGBoostのEstimatorオブジェクトを指定
- max_jobs: チューニングジョブで実行する最大トレーニング数を5に設定
- max_parallel_jobs: 並列実行するトレーニングジョブの最大数を2に設定
- objective_metric_name: 最適化する目標メトリックを指定
- hyperparameter_ranges: チューニング対象のハイパーパラメータ範囲を指定
- base_tuning_job_name: チューニングジョブの基本名を指定
- strategy: ハイパーパラメータ探索戦略を「ランダム探索」に設定
tuner.fit(inputs={“train”: s3_input_train, “validation”: s3_input_validation}, include_cls_metadata=False)
トレーニングデータ、検証データを使用してチューニングジョブを開始
tuner.wait(): チューニングジョブが完了するまで待機
sagemaker.HyperparameterTuningJobAnalytics()
最新のチューニングジョブ結果を分析オブジェクトとして取得
df_tuner[df_tuner[“FinalObjectiveValue”]>-float(‘inf’)]
有効な結果のみをフィルタリング(無効な結果は-infになる場合がある)
.sort_values(“FinalObjectiveValue”, ascending=False): 目標メトリック(AUC)の値が高い順にソート
これにより、最も良い性能を発揮したハイパーパラメータの組み合わせがわかりました。
sess.create_model_from_job()
トレーニングジョブからモデルを作成します。
- name=xgb_model_name: 作成するモデルの名前を指定します。
- training_job_name=tuner_job_info[‘BestTrainingJob’][“TrainingJobName”]: 最適なトレーニングジョブの名前を指定します。
- role=sagemaker_role: モデルがアクセスするリソースの権限を持つIAMロールを指定します。
- image_uri=tuner_job_info[‘TrainingJobDefinition’][“AlgorithmSpecification”][“TrainingImage”]: モデルのデプロイに使用するDockerイメージを指定します。
Amazon SageMaker Clarifyによるモデルのバイアス分析と説明可能性分析
バイアス分析の実行
train_df = pd.read_csv(train_data_uri)
train_df_cols = train_df.columns.to_list()
トレーニングデータをCSVファイルから読み込み、カラム名のリストを取得します。
clarify_processor = sagemaker.clarify.SageMakerClarifyProcessor()
SageMaker Clarifyを実行するためのプロセッサーを初期化します
- role: Clarifyが使用するIAMロールを指定します
- instance_count: Clarify処理に使用するインスタンスの数を指定します
- instance_type: Clarify処理に使用するインスタンスタイプを指定します
- sagemaker_session: SageMakerセッションオブジェクトを指定します
bias_data_config = sagemaker.clarify.DataConfig()
バイアス分析に使用するデータの設定
model_config = sagemaker.clarify.ModelConfig()
分析対象のモデルの設定
predictions_config = sagemaker.clarify.ModelPredictedLabelConfig(probability_threshold=0.5)
モデル予測の設定、確率値を二値ラベルに変換する際のしきい値は0.5にしています。
bias_config = sagemaker.clarify.BiasConfig()
バイアス分析の具体的な設定
- label_values_or_threshold: 注目する目的変数の値(0=詐欺ではない)
- facet_name: バイアスを分析したい特徴量(customer_gender_female:女性かどうか)
- facet_values_or_threshold: 注目する特徴量の値(1=女性)
clarify_processor.run_bias()
バイアス分析の実行
- data_config: データの設定
- bias_config: バイアス分析の設定
- model_config: モデルの設定
- model_predicted_label_config: 予測ラベルの設定
- pre_training_methods=[“CI”]: 事前訓練バイアス指標として「Class Imbalance(CI)」を使用
- post_training_methods=[“DPPL”]: 事後訓練バイアス指標として「Difference in Positive Proportions in Labels(DPPL)」を使用
事前訓練バイアス指標はモデル構築前に確認できます。
トレーニングデータのクラスごとの不均衡を測定できます。
事後訓練バイアスはモデル訓練後に評価できます。
モデルの予測結果のクラスごとの不均衡を測定できます。
バイアス分析の結果
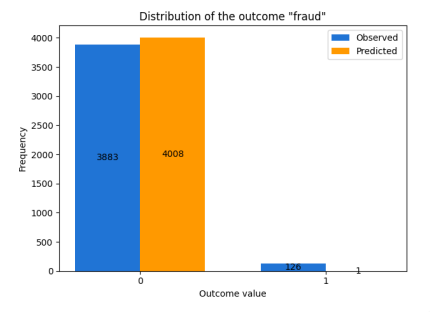
青色がトレーニングデータの分布で、オレンジが予測値です。
左側の0が不正ではない、右側の1が不正です。
トレーニングデータでも不正のデータが少なく、予測では1件しか予測されなかった結果となり、偏りが発生していることを示しています。
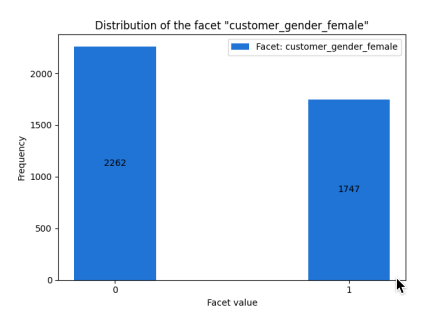
男性と女性の分布の図です。
男性のほうが500人ほど多いことがわかります。
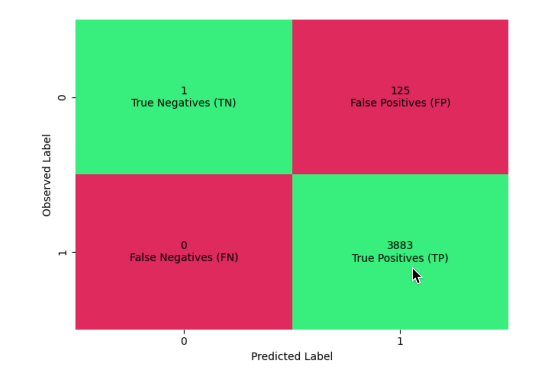
全体の混同行列です。
真陽性(TP):3883件(正しく不正ではないと予測)
偽陽性(FP):125件(不正を不正ではないと誤予測)
偽陰性(FN):0件(不正ではないを不正と誤予測)
真陰性(TN):1件 (正しく不正と予測)
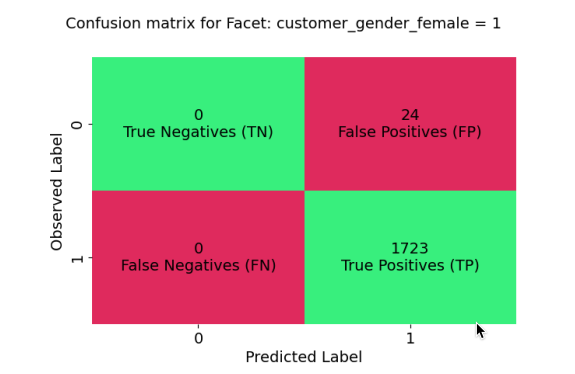
女性(customer_gender_female=1)に関する混同行列です。
真陽性(TP):1723件(正しく不正ではないと予測)
偽陽性(FP):24件(不正を不正ではないと誤予測)
偽陰性(FN):0件(不正ではないを不正と誤予測)
真陰性(TN):0件 (正しく不正と予測)
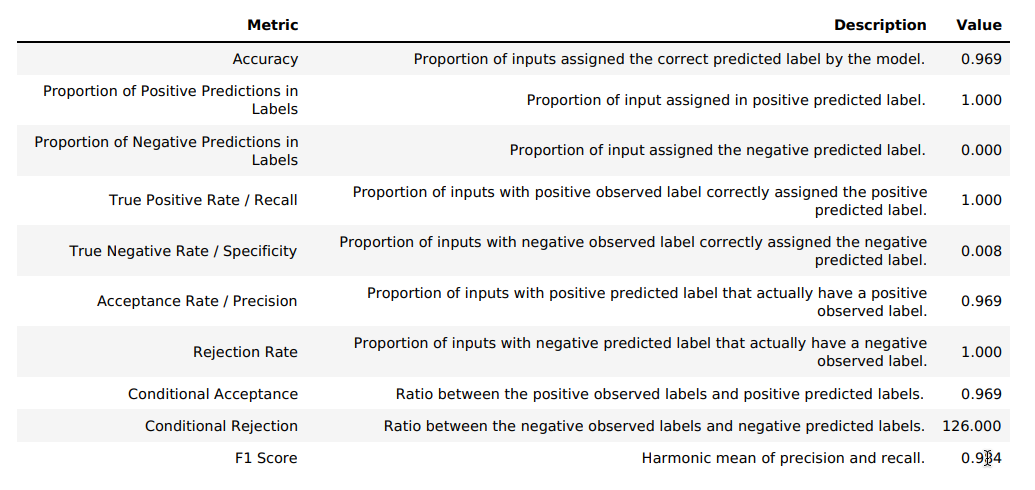
- 精度(Accuracy):0.969
- 正例予測の割合:1.000(すべての予測が正例)
- 真陽性率(Recall):1.000
- 真陰性率(Specificity):0.008
- 適合率(Precision):0.969
- F1スコア:0.984
これらの数値から、モデルはほぼすべての事例を不正ではない(fraud=0)と予測する傾向があることがわかります。
性別バイアスはCIが0.128でわずかな不均衡、DPPLは0なので差異なし。
ですが、そもそもほぼすべてを不正ではないと予測しているため、改善したほうが良いことがわかりました。
説明可能性分析の実行
explainability_data_config = sagemaker.clarify.DataConfig()
説明可能性分析に使用するデータの設定
shap_baseline = [list(train_df.drop([“fraud”], axis=1).mean())]
SHAP値計算のためのベースラインデータポイント、トレーニングデータの各特徴量の平均値を使用
shap_config = sagemaker.clarify.SHAPConfig()
SHAP値分析の設定
clarify_processor.run_explainability()
設定したパラメータを使って説明可能性分析を実行
説明可能性分析の結果
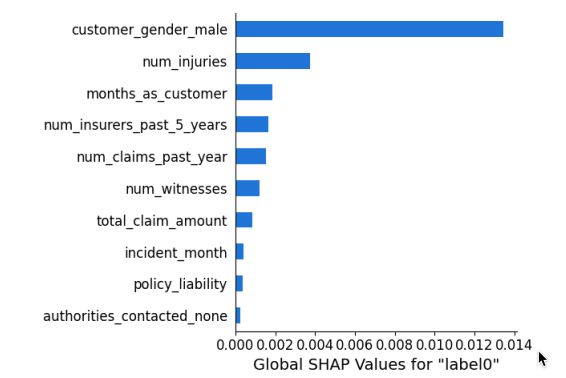
特徴量のうち影響の大きい順にソートしています。
customer_gender_male(男性顧客)が最も大きく影響与えていることがわかります。
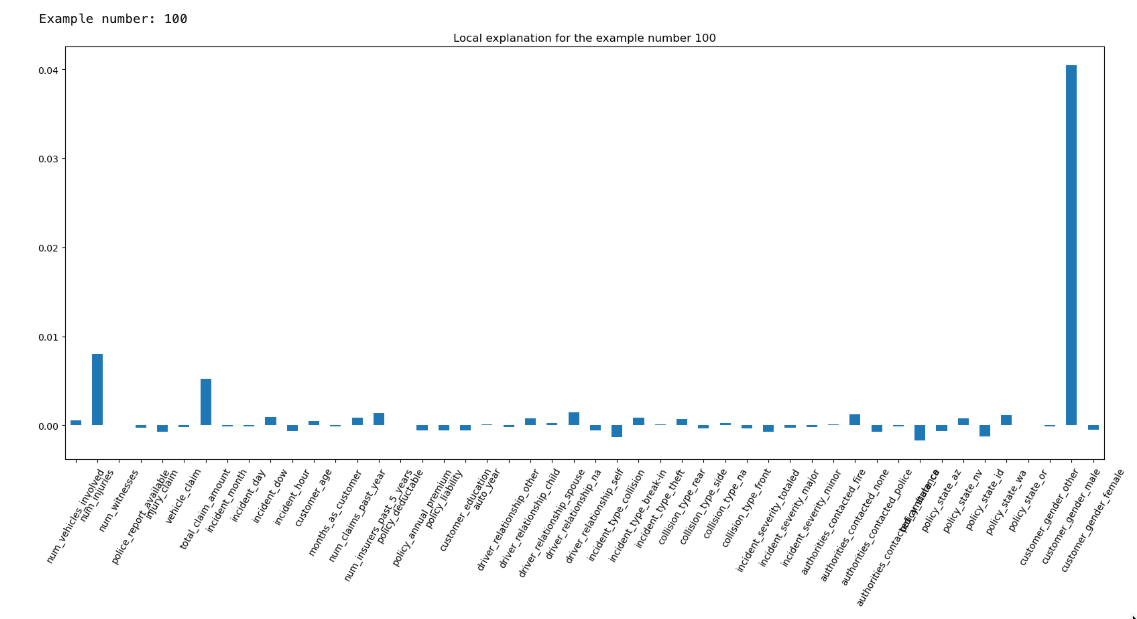
特定のデータに対しての特徴量の影響を示しています。
最後までお読みいただきましてありがとうございました!
「AWS認定資格試験テキスト&問題集 AWS認定ソリューションアーキテクト - プロフェッショナル 改訂第2版」という本を書きました。

「AWS認定資格試験テキスト AWS認定クラウドプラクティショナー 改訂第3版」という本を書きました。

「AWS認定資格試験テキスト AWS認定AIプラクティショナー」という本を書きました。

「ポケットスタディ AWS認定 デベロッパーアソシエイト [DVA-C02対応] 」という本を書きました。

「要点整理から攻略するAWS認定ソリューションアーキテクト-アソシエイト」という本を書きました。

「AWSではじめるLinux入門ガイド」という本を書きました。

開発ベンダー5年、ユーザ企業システム部門通算9年、ITインストラクター5年目でプロトタイプビルダーもやりだしたSoftware Engineerです。
質問はコメントかSNSなどからお気軽にどうぞ。
出来る限りなるべく答えます。
このブログの内容/発言の一切は個人の見解であり、所属する組織とは関係ありません。
このブログは経験したことなどの共有を目的としており、手順や結果などを保証するものではありません。
ご参考にされる際は、読者様自身のご判断にてご対応をお願いいたします。
また、勉強会やイベントのレポートは自分が気になったことをメモしたり、聞いて思ったことを書いていますので、登壇者の意見や発表内容ではありません。
関連記事
-

-
百聞は一見にしかず!AWSセルフペースラボの無料ラボ!
※2019年5月12日現在に試してみた記録です。 AWSセルフペースラボとは A …
-
-
CloudFrontからのバーチャルホストなサイトのテストってどうしてます?
このブログの構成です。 AWSで構築しています。 4つのサイトを1つのEC2で配 …
-
-
IAM Access Analyzerの検出をEventBridgeルールで検知して通知する
やりたかったことは使用可能としているリージョンのIAM Access Analy …
-
-
RDSの拡張モニタリングを有効にしました
RDS for MySQLです。 変更メニューで、[拡張モニタリングを有効にする …
-
-
Lambda関数をPython3.6から3.9に変更
CodeGuru ProfilerでLambda関数(Python 3.9)のパ …
-
-
Amazon Q Developer for CLIをmacOSにインストールしました
2025/3/26のAWS Expert Online for JAWSの「Am …
-
-
前からできましたっけ??CloudWatch Logsの保持設定を複数まとめて設定
AWSの個人アカウントで要らなさそうなリソースの断捨離をしてます。 CloudW …
-
-
「AWS認定資格試験テキスト AWS認定クラウドプラクティショナー」を執筆いたしました
「AWS認定資格試験テキスト AWS認定クラウドプラクティショナー」という本の第 …
-
-
Intel 82599 VF インターフェイスで拡張ネットワーキングが有効なEC2インスタンスで帯域幅を確認してみました
拡張ネットワーキングが有効なEC2インスタンスとそうではないインスタンスの2セッ …
-
-
Amazon Glacierでボールトロックポリシーの作成開始をしてみました
Glacierを単体で使用することもそうそうないので、確認しました。 まずボール …